FBV与CBV
视图函数并不只是指函数,也可以是类
FBV:基于函数的视图,类似面向函数式编程
CBV:基于类的视图,类似面向对象编程

研究解析render源码:
render:返回html页面;并且能够给该页面传值
分析:FBV视图原理
from django.shortcuts import render,HttpResponse # Create your views here. from django.template import Template,Context # FBV解析 def index(request): temp = Template('{{ user }}
') con = Context({"user":{"name":'gets','password':'123456'}}) res =temp.render(con) print(res) return HttpResponse(res)
print的结果:

可以分析出利用关键字:Context 先获取数据格式,通过con = Context({"user":{"name":'gets','password':'123456'}})转成字典形式传给前端显示
分析CBV视图原理:类方法
问题:基于CBV的视图函数,get请求来就会走类里面get方法,post请求来就会走类里面post方法 为什么???
为什么会自动分布请求类中的get/post方法呢?有什么在自动识别?
验证请求方式的get/post的执行
#CBV视图 from django.views import View from django.conf import settings class MyLogin(View): def get(self,request): print("from MyLogin get方法") 为什么会走get/post return render(request,'login.html') def post(self,request): return HttpResponse("from MyLogin post方法")
CBV对应的路由层:url
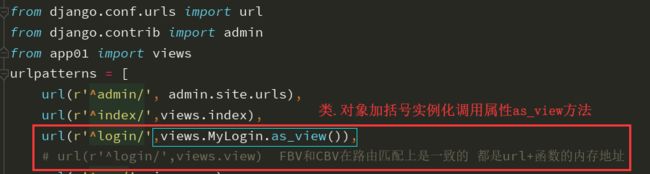
由于函数名加括号执行优先级最高,所以这一句话一写完会立刻执行as_view()方法
1、从url入手分析这一现象的存在:分析as_view源码解析结果:

分析步骤:

点击view方法查看:

点击view继承的父类dispatch方法

再次查看源码部分内容分析:
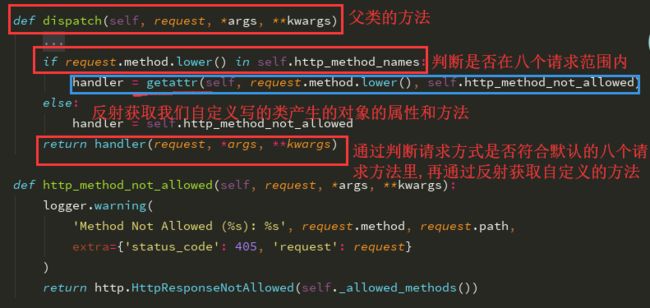
源码解析:
@classonlymethod def as_view(cls, **initkwargs): # cls就是我们自己的写的类 MyLogin def view(request, *args, **kwargs): self = cls(**initkwargs) # 实例化产生MyLogin的对象 self = MyLogin(**ininkwargs) if hasattr(self, 'get') and not hasattr(self, 'head'): self.head = self.get self.request = request self.args = args self.kwargs = kwargs # 上面的几句话都仅仅是在给对象新增属性 return self.dispatch(request, *args, **kwargs) # dispatch返回什么 浏览器就会收到什么 # 对象在查找属性或者方法的时候 你一定要默念 先从对象自己这里找 然后从产生对象的类里面找 最后类的父类依次往后 return view
通过源码发现url匹配关系可以变形成
url(r'^login/',views.view) # FBV和CBV在路由匹配上是一致的 都是url后面跟函数的内存地址
2、当浏览器中输入login,会立刻触发view函数的运行
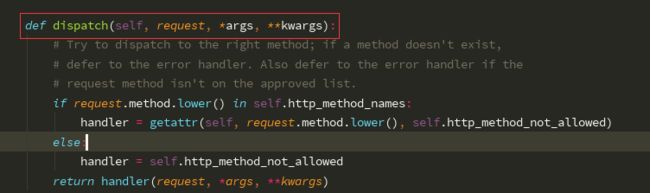
第二部分分析源码:
def dispatch(self, request, *args, **kwargs): # Try to dispatch to the right method; if a method doesn't exist, # defer to the error handler. Also defer to the error handler if the # request method isn't on the approved list. # 我们先以GET为例 if request.method.lower() in self.http_method_names: # 判断当前请求方法是否在默认的八个方法内 # 反射获取我们自己写的类产生的对象的属性或者方法 # 以GET为例 handler = getattr(self,'get','取不到报错的信息') # handler = get(request) handler = getattr(self, request.method.lower(), self.http_method_not_allowed) else: handler = self.http_method_not_allowed return handler(request, *args, **kwargs) # 直接调用我们自己的写类里面的get方法 # 源码中先通过判断请求方式是否符合默认的八个请求方法 然后通过反射获取到自定义类中的对应的方法执行
通过路由层url中的.re_view方法,解析源码分析得出实现get/post请求分发的原理,是什么请求就走什么方法
Django settings 源码解析:
前提:
1、diango除了暴露给用户一个settings.py配置的文件之外,自己内部还有一个全局的配置文件(只是展示了部分信息的settnigs)。
2、我们在使用配置文件的时候,可以直接导入暴露给用户的settings.py也可以使用django全局的配置问的文件
需要导入的模块:from django.conf import settings
点击settings 查看源码配置文件

3、django的启动入口是manage.py
分析为什么在settings配置文件中的变量名都是大写的?为什么写小写的就不行了呢?

基于以上分析源码后,分析实现seettings的功能,受限变量名必须写大写
import os import sys if __name__ == "__main__": # django在启动的时候 就会往全局的大字典中设置一个键值对 值是暴露给用户的配置文件的路径字符串 os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day54.settings") class Settings(object): def __init__(self, settings_module): # settings_module = 'day54.settings' # update this dict from global settings (but only for ALL_CAPS settings) or setting in dir(global_settings): # django全局配置文件 # dir获取django全局配置文件中所有的变量名 if setting.isupper(): # 判断文件中的变量名是否是大写 如果是大写才会执行/生效 setattr(self, setting, getattr(global_settings, setting)) # 给settings对象设置键值对 # 给settings对象设置键值对 settings[配置文件中大写的变量名] = 配置文件中大写的变量名所对应的值 # store the settings module in case someone later cares self.SETTINGS_MODULE = settings_module # 'day54.settings' mod = importlib.import_module(self.SETTINGS_MODULE) # mod = 模块settings(暴露给用户的配置文件) for setting in dir(mod): # for循环获取暴露给用户的配置文件中所有的变量名 if setting.isupper(): # 判断变量名是否是大写 setting_value = getattr(mod, setting) # 获取大写的变量名所对应的值 setattr(self, setting, setting_value) # 给settings对象设置键值对 """ d = {} d['username'] = 'jason' d['username'] = 'egon' 用户如果配置了就用用户的 用户如果没有配置就用系统默认的 其实本质就是利用字典的键存在就是替换的原理 实现了用户配置就用用户的用户没配置就用默认的 """
class settings 实现必须书写大写的精髓部分:

继承的类分析:
class LazySettings(LazyObject): def _setup(self, name=None): # os.environ你可以把它看成是一个全局的大字典 settings_module = os.environ.get(ENVIRONMENT_VARIABLE) # 从大字典中取值键为DJANGO_SETTINGS_MODULE所对应的值:day54.settings # settings_module = 'day54.settings' self._wrapped = Settings(settings_module) # Settings('day54.settings')
settings = LazySettings() # 单例模式
实现功能的核心代码块:

作业:
参考django settings源码 实现自己的项目也能够做到 用户配置了就用用户的 用户没有配置 就用全局的
__init__.py文件下:
import os import importlib from lib.conf import global_settings class Settings(object): def __init__(self): # 先for循环获取全局配置文件中所有的变量名 for name in dir(global_settings): # 判断是否是大写 if name.isupper(): #给settings对象设置键值对 setattr(self,name,getattr(global_settings,name)) path = os.environ.get('xxx') module = importlib.import_module(path) #再循环暴露给用户的文件中所有的变量名 for name in dir(module): if name.isupper(): k=name v=getattr(module,name) setattr(self,k,v) settings=Settings()
start.py文件
import os import sys BASE_DIR = os.path.dirname(__file__) sys.path.append(BASE_DIR) if __name__ == '__main__': # 在项目中的全局一个大字典 os.environ.setdefault('xxx','conf.settings') from lib.conf import settings print(settings.NAME)
Django模板层
模板语法
1、为模板传值
只需要记两种特殊符号: {{ }}和 {% %} 变量相关的用{{}},逻辑相关的用{%%}。
两种给前端传值的区别
给模板传值的方式 方式1 # 通过字典的键值对 指名道姓的一个个的传 return render(request,'reg.html',{'n':n,'f':f})
方式2 # locals会将它所在的名称空间中的所有的名字全部传递给前端 # 该方法虽然好用 但是在某些情况下回造成资源的浪费
# return render(request, 'reg.html', locals())
传函数名,会自动加括号调用该函数,前端展示的是函数调用之后的返回值:{{ index }}
注意:如果函数需要参数的话 那么不好意思 模板语法不支持
变量
在Django的模板语法中按此语法使用{{变量名}}.
当模版引擎遇到一个变量,它将计算这个变量,然后用结果替换掉它本身。 变量的命名包括任何字母数字以及下划线 ("_")的组合。 变量名称中不能有空格或标点符号
标签与过滤器
Filters(过滤器)
在Django的语法中,通过使用过滤器来改变变量的显示.
过滤器的语法: {{ value|filter_name:参数 }}
使用管道符"|"来应用过滤器。
{#<h1>模板语法之标签:内部原理(会将|前面的当做第一个参数传入标签中)h1>#}
注意事项:
1、过滤器支持“链式”操作。即一个过滤器的输出作为另一个过滤器的输入。
2、过滤器可以接受参数,例如:{{ sss|truncatewords:30 }},这将显示sss的前30个词。
3、过滤器参数包含空格的话,必须用引号包裹起来。比如使用逗号和空格去连接一个列表中的元素,如:{{ list|join:', ' }}
4、'|'左右没有空格没有空格没有空格
Django的模板语言中常用的内置过滤器有:
default:如果一个变量是false或者为空,使用给定的默认值。否则,使用变量的值
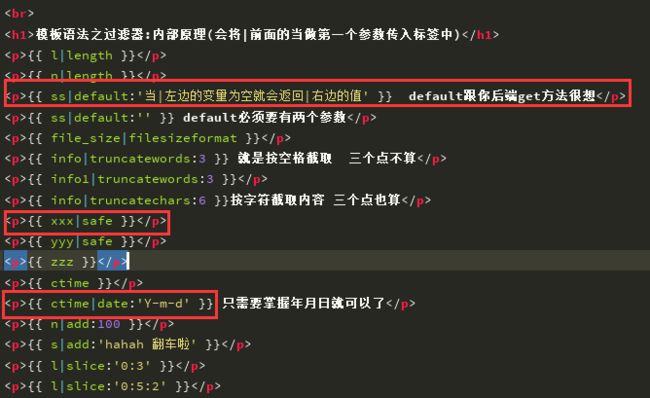
一些常用的过滤器的详解:
length
返回值的长度,作用于字符串和列表。
{{ value|length }}
返回value的长度,如 value=['a', 'b', 'c', 'd']的话,就显示4.
filesizeformat
将值格式化为一个 “人类可读的” 文件尺寸 (例如 '13 KB', '4.1 MB', '102 bytes', 等等)。例如:
{{ value|filesizeformat }}
如果 value 是 123456789,输出将会是 117.7 MB。
slice
切片
{{value|slice:"2:-1"}}
date
格式化
{{ value|date:"Y-m-d H:i:s"}}
safe
Django的模板中会对HTML标签和JS等语法标签进行自动转义,原因显而易见,这样是为了安全。如果是一个单独的变量我们可以通过过滤器“|safe”的方式告诉Django这段代码是安全的不必转义
比如:
value = "点我"
{{ value|safe}}
前后端取消转义
也就意味着前端的html代码 并不单单只能在html文件中书写
你也可以在后端先生成html代码 然后直接传递给前端(**)
前端
|safe
后端
from django.utils.safestring import mark_safe mark_safe("xxx")
truncatechars
如果字符串字符多于指定的字符数量,那么会被截断。截断的字符串将以可翻译的省略号序列(“...”)结尾。
参数:截断的字符数
{{ value|truncatechars:9}}
truncatewords
在一定数量的字后截断字符串。
{{ value|truncatewords:9}}
cut
移除value中所有的与给出的变量相同的字符串
{{ value|cut:' ' }}
如果value为'i love you',那么将输出'iloveyou'.
join
使用字符串连接列表,例如Python的str.join(list)
timesince
将日期格式设为自该日期起的时间(例如,“4天,6小时”)。
采用一个可选参数,它是一个包含用作比较点的日期的变量(不带参数,比较点为现在)。
例如,如果blog_date是表示2006年6月1日午夜的日期实例,并且comment_date是2006年6月1日08:00的日期实例,则以下将返回“8小时”:
{{ blog_date|timesince:comment_date }}
分钟是所使用的最小单位,对于相对于比较点的未来的任何日期,将返回“0分钟”。
timeuntil
似于timesince,除了它测量从现在开始直到给定日期或日期时间的时间。 例如,如果今天是2006年6月1日,
而conference_date是保留2006年6月29日的日期实例,则{{ conference_date | timeuntil }}将返回“4周”。
使用可选参数,它是一个包含用作比较点的日期(而不是现在)的变量。 如果from_date包含2006年6月22日,则以下内容将返回“1周”:
{{ conference_date|timeuntil:from_date }}
标签:逻辑相关 {%%}
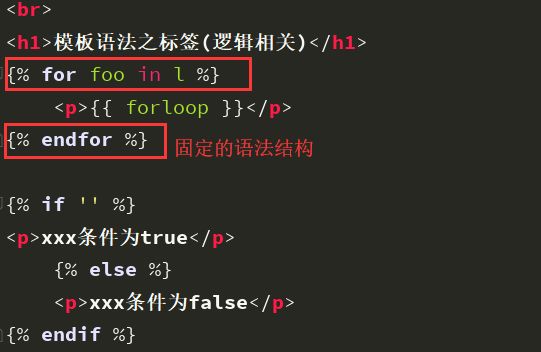
for循环可用的一些参数:

| Variable | Description |
|---|---|
forloop.counter |
当前循环的索引值(从1开始) |
forloop.counter0 |
当前循环的索引值(从0开始) |
forloop.revcounter |
当前循环的倒序索引值(从1开始) |
forloop.revcounter0 |
当前循环的倒序索引值(从0开始) |
forloop.first |
当前循环是不是第一次循环(布尔值) |
forloop.last |
当前循环是不是最后一次循环布尔值) |
forloop.parentloop |
本层循环的外 |
if判断
if,elif和else

结合使用:
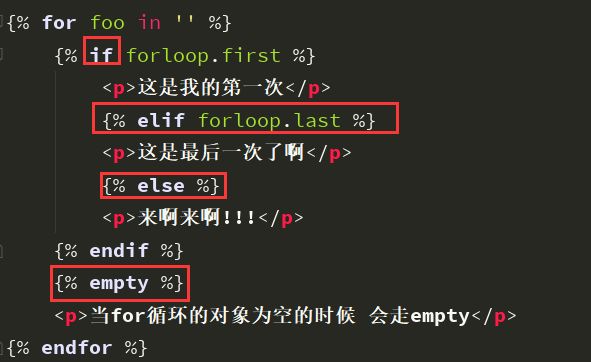
if语句支持 and 、or、==、>、<、!=、<=、>=、in、not in、is、is not判断。
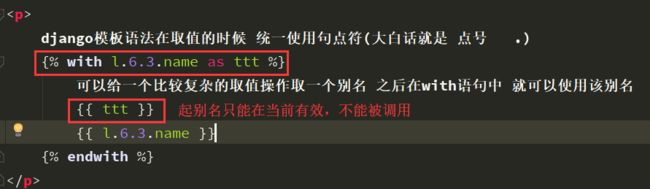
with
定义一个中间变量,多用于给一个复杂的变量起别名。
注意等号左右不要加空格。
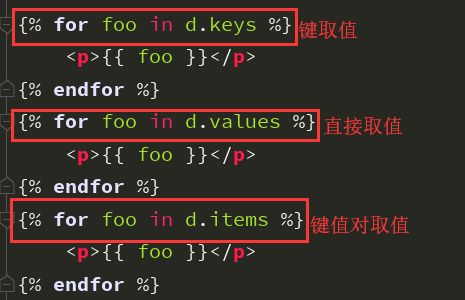
针对字典形式的取值:
自定义过滤器和标签
适应场景:例如Django提供的过滤器或标签不能够处理一些特殊的数据时,可以自定义写
使用注意事项:
1、先在应用名下的文件夹中新建一个名字必须叫做templatetags文件夹(必须是这个名字)
2、在该文件夹内新建一个任意名称的.py文件
3、在该py文件中,必须先写以下两句代码
from django import template
register = template.Library()
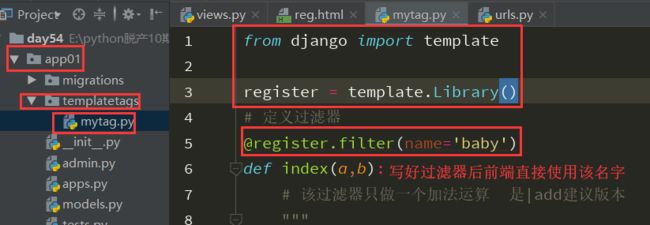
前端的使用:
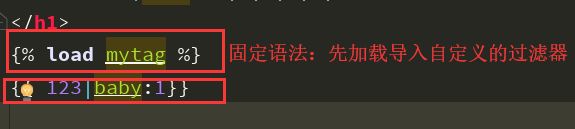
自定义标签
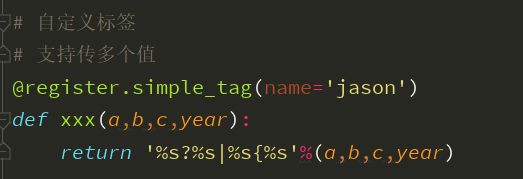
总结:
from django import template
register = template.Library()
# 自定义过滤器
@register.filter(name='mysum')
def mysum(a,b)
retunr a + b
# 自定义标签
@register.simple_tag(name='myplus')
def myplus(a,b,c,d,e):
return None
# 自定义inclusion_tag
@register.inclusion_tag('mytag.html')
def mytag(n):
...
# return {'l':l}
return locals()
在html上使用需要先导入后使用
{% load py文件名 %}
{{ 2|mysum:1}}
{% myplus 1 2 3 5 5 %}
{% mytag 10 %}
模板的继承与导入
使用的场景:当多个HTML页面需要使用相同的HTML代码的时候,可以考虑使用继承
搭页面:

首先需要你在模板html代码中 通过block块儿划定后续想要修改的区域
{%block content%}
{%endblock%}
一般情况下 模板html文件内应该有三块区域 css,content,js
模板一般情况下
应该至少有三个可以被修改的区域
{ % block
css %}
子页面自己的css代码
{ % endblock %}
{ % block
content %}
子页面自己的html代码
{ % endblock %}
{ % block
js %}
子页面自己的js代码
{ % endblock %}
实际应用到html:
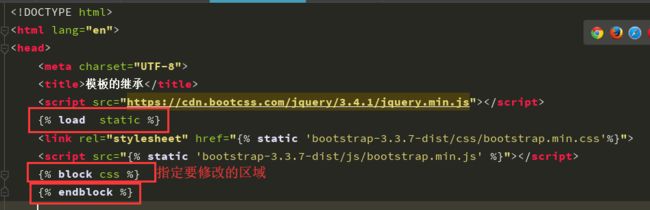
简单的结构介绍:
模板的导入 {% extends '模板的名字'%} {%block content%} 修改模板中content区域的内容 {{ block.super }}重新复用模板的html样式 {%endblock%} 模板的导入 {% include '你想要导入的html文件名'%}
模板的导入:关键字:include 路由分发:也是用这个关键字,联想记忆
模型层的单表查询
创建表:
create_time = models.DateField() 关键性的参数 1.auto_now:每次操作数据 都会自动刷新当前操作的时间 2.auto_now_add:在创建数据的时候 会自动将创建时间记录下来 后续的修改不会影响该字段
简单创建一张表:
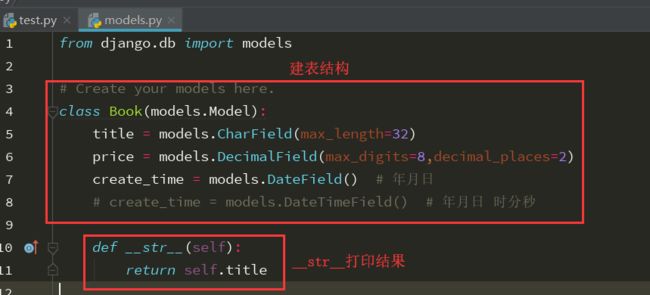
创建表后记得更新表的迁移操作:两条命令
编写测试脚本:
在django中 你可以写一个单独测试某一个py文件的测试脚本 不需要再频繁的走web请求
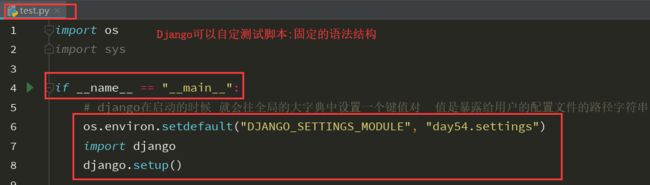
单表的操作: 增 删 改 查
import os import sys if __name__ == '__main__': # django 在启动的时候 就会往全局的大字典一个键值对,值时暴露给用户的 os.environ.setdefault("DJANGO_SETTINGS_MODULE", "Djangoday54.settings") import django django.setup() from app01 import models models.Book.objects.all() book_obj = models.Book.objects.create(title="百年孤独",price=199.99,create_time=2019-11-20) print(book_obj.title) # from datetime import datetime # ctime = datetime.now() # book_obj = models.Book(title='围城',price=200.99,create_time=ctime) # book_obj.save() #查 print(models.Book.objects.all()) print(models.Book.objects.get(id=2)) # 自动查找到当前的数据主键字段 # 改 update models.Book.objects.filter(pk=1).update(title='百年孤独') book_obj =models.Book.objects.get(pk=1) book_obj.price = 66.34 book_obj.save() # 删除 delete() models.Book.objects.filter(pk=1).delete()
单表查询必会的13个方法:
返回QuerySet对象的方法有
all()
filter()
exclude()
order_by()
reverse()
distinct()
特殊的QuerySet
values() 返回一个可迭代的字典序列
values_list() 返回一个可迭代的元祖序列
返回具体对象的
get()
first()
last()
返回布尔值的方法有:
exists()
返回数字的方法有
count()
< 1 > all(): 查询所有结果 < 2 > filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 < 3 > get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。(源码就去搂一眼~诠释为何只能是一个对象) < 4 > exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 print(models.Book.objects.exclude(pk=1)) # 只要pk不是1的数据全部查询出来 < 5 > order_by(*field): 对查询结果排序('-id') / ('price') print(models.Book.objects.order_by('price')) # 默认是升序 print(models.Book.objects.order_by('-price')) # 加负号就是降序 # < 6 > reverse(): 对查询结果反向排序 >> > 前面要先有排序才能反向 # print(models.Book.objects.order_by('price').reverse()) # < 7 > count(): 返回数据库中匹配查询(QuerySet) # print(models.Book.objects.count()) # 对查询出来的结果进行一个计数 # < 8 > first(): 返回第一条记录 # print(models.Book.objects.filter(pk=1).first()) # < 9 > last(): 返回最后一条记录 # print(models.Book.objects.all()) # print(models.Book.objects.all().last()) # < 10 > exists(): 如果QuerySet包含数据,就返回True,否则返回False # print(models.Book.objects.filter(pk=1000)) # print(models.Book.objects.filter(pk=1000).exists()) # < 11 > values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 # model的实例化对象,而是一个可迭代的字典序列 # print(models.Book.objects.values('title','price')) # 得到的结果是列表套字典 # < 12 > values_list(*field): 它与values() # print(models.Book.objects.values_list('title','price')) # 得到的结果是列表套元组 # 非常相似,它返回的是一个元组序列,values返回的是一个字典序列 # < 13 > distinct(): 从返回结果中剔除重复纪录 """ 去重的前提是 一定要有完全重复的数据 才能去重 """ # print(models.Book.objects.filter(title='三国演义').distinct()) # print(models.Book.objects.values('title','price','create_time').distinct())