Hadoop在Linux下伪分布式的安装以及wordcount实例的运行还有Eclipse的使用
Hadoop版本:hadoop-0.20.2
1、hadoop伪分布式的安装
1.安装配置java1.6。配置完毕后,在命令行中输入java -version,如出现下列信息说明java环境安装成功。
java version "1.6.0_20"
Java(TM) SE Runtime Environment (build 1.6.0_20-b02)
Java HotSpot(TM) Server VM (build 16.3-b01, mixed mode)
2.配置ssh免密码登录
(1)安装ssh:sudo apt-get install ssh
(2)配置可以无密码登陆本机:
首先查看在u用户下是否存在.ssh文件夹(注意ssh前面有“.”,这是一个隐藏文件夹),输入命令:
cd /home/wangxing。
接下来,输入命令:
ssh-keygen -t dsa -P '' –f~/.ssh/id_dsa
这个命令会在.ssh文件夹下创建两个文件id_dsa及id_dsa.pub,这是ssh的一对私钥和公钥,类似于钥匙及锁,把id_da.pub(公钥)追加到授权的key里面去,
输入命令:cat ~/.ssh/id_dsa.pub >>~/.ssh/authorized_keys
这段话的意思是把公钥加入到用于认证的公钥文件中,这里authorized_keys是用于认证的公钥文件。至此无密码登陆本机以安装完成。
(3)验证ssh已安装成功及无密码登陆本机
输入命令:ssh –version
显示结果:
OpenSSH_5.1p1 Debian-6ubuntu2, OpenSSL 0.9.8g 19Oct 2007
Bad escape character 'rsion'.
这显示了ssh已经安装成功
输入命令:
ssh localhost
会有如下显示:
The authenticity of host 'localhost (::1)' can't beestablished.
RSA key fingerprint is8b:c3:51:a5:2a:31:b7:74:06:9d:62:04:4f:84:f8:77.
Are you sure you want to continue connecting(yes/no)? yes
Warning: Permanently added 'localhost' (RSA) to thelist of known hosts.
Linux master 2.6.31-14-generic #48-Ubuntu SMP FriOct 16 14:04:26 UTC 2009 i686
To access official Ubuntu documentation, pleasevisit:
http://help.ubuntu.com/
Last login: Mon Oct 18 17:12:40 2010 from master
如上显示,说明已经安装成功,第一次登录时会询问你是否继续链接,输入yes即可以进入。
实际上,在hadoop的安装过程中,是否无密码登陆不是必须的,但是如果不配置无密码登陆的话,每次启动hadoop,都需要输入密码以登陆到每台daotanode,考虑到一般的hadoop集群动辄数十数百台机器,因此一般来说都会配置ssh的无密码登陆。
3.下载hadoop-0.20.2.tar.gz,放在用户根目录下,例如:/home/wangxing/hadoop-0.20.2:
下载地址:http://mirror.bjtu.edu.cn/apache/hadoop/common/hadoop-0.20.2/
解压:tar –zvxf hadoop-0.20.2.tar.gz
4.配置hadoop,hadoop 的主要配置都在hadoop-0.20.2/conf 下。
(1)在conf/hadoop-env.sh 中配置Java 环境以及HADOOP_HOME、PATH,例如
export JAVA_HOME=/usr/local/jre1.6.0_24
export HADOOP_HOME=/home/wangxing/hadoop-0.20.2
export PATH=$PATH:/home/wangxing/hadoop-0.20.2/bin
(2)配置conf/core-site.xml、conf/hdfs-site.xml、conf/mapred-site.xml
core-site.xml
fs.default.name
hdfs://localhost:9000/
hadoop.tmp.dir
/home/wangxing/hadoop-0.20.2/tmpdir
hdfs-site.xml
dfs.replication
1
dfs.name.dir
/home/wangxing/hadoop-0.20.2/tmpdir/hdfs/name
dfs.data.dir
/home/wangxing/hadoop-0.20.2/tmpdir/hdfs/data
mapred-site.xml
mapred.job.tracker
localhost:9001
mapred.local.dir
/home/wangxing/hadoop-0.20.2/tmpdir/mapred/local
mapred.system.dir
/home/wangxing/hadoop-0.20.2/tmpdir/mapred/system
5.格式化namenode、datanode:bin/hadoop namenode -format、bin/hadoop datanode -format
6.启动hadoop所有进程:bin/start-all.sh
7.验证hadoop是否安装成功
打开浏览器,分别输入网址
http://localhost:50030 (mapreduce的web页面)
http://localhost:50070 (hdfs的web页面)
http://localhost:50060 (TaskTracker运行状态的web页面)
如果都能查看,说明hadoop已经安装成功。
8.查看hadoop进程启动情况:jps。正常情况下应该有NameNode、SecondaryNameNode、DataNode、JobTracker、TaskTracker

9.查看集群状态:bin/hadoop dfsadmin -report

2、WordCount例子的运行
10.在/home/wangxing/hadoop-0.20.2创建目录test,在test下创建文本file01、file02,分别输入数个单词
11.在hdfs分布式文件系统创建目录input:bin/hadoop fs -mkdir input;之后可以使用bin/hadoop fs -ls查看
ps:删除目录:bin/hadoop fs -rmr ***;删除文件:bin/hadoop fs -rm ***
12.将文本文件放入hdfs分布式文件系统中:bin/hadoop fs -put /home/wangxing/hadoop-0.20.2/test/* input

13.执行例子中的WordCount:bin/hadoop jar hadoop-0.20.2-examples.jar wordcount input output
14.查看执行结果:bin/hadoop dfs -cat output/*
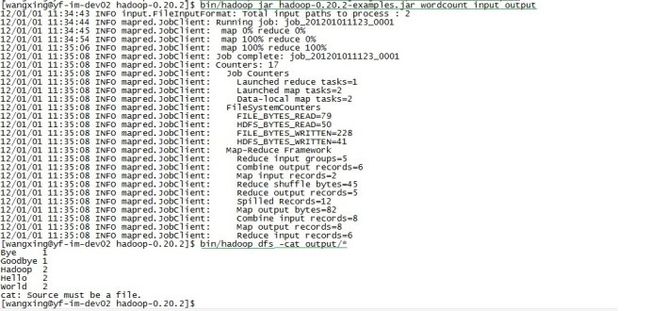
15.关闭hadoop所有进程:bin/stop-all.sh
3、Eclipse在Hadoop开发中的使用
2、安装eclipse
(1)把eclipse-java-helios-SR2-linux-gtk.tar.gz解压到某个目录中,我解压到的是/home/wangxing/Development,得到eclipse目录
(2)在/usr/bin目录下创建一个启动脚本eclipse,执行下面的命令来创建:
sudo gedit /usr/bin/eclipse
然后在该文件中添加以下内容:
#!/bin/sh
export MOZILLA_FIVE_HOME="/usr/lib/mozilla/"
export ECLIPSE_HOME="/home/wangxing/Development/eclipse"
$ECLIPSE_HOME/eclipse $*
(3)修改该脚本的权限,让它变成可执行,执行下面的命令:
sudo chmod +x /usr/bin/eclipse
3、在Applications(应用程序)菜单上添加一个图标
sudo gedit /usr/share/applications/eclipse.desktop
然后在文件中添加下列内容:
[Desktop Entry]
Encoding=UTF-8
Name=Eclipse Platform
Comment=Eclipse IDE
Exec=eclipse
Icon=/home/wangxing/Development/eclipse/icon.xpm
Terminal=false
StartupNotify=true
Type=Application
Categories=Application;Development;
复制 hadoop安装目录/contrib/eclipse-plugin/hadoop-0.20.203.0-eclipse-plugin.jar 到eclipse安装目录/plugins/ 下
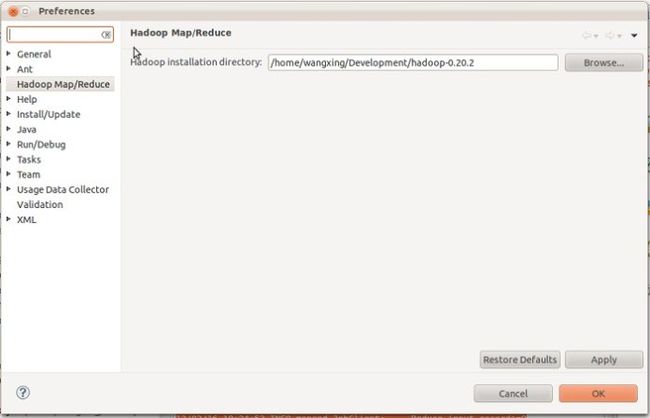
5.重启eclipse,配置hadoop installation directory。
如果安装插件成功,打开Window-->Preferens,你会发现Hadoop Map/Reduce选项,在这个选项里你需要配置Hadoop installation directory。配置完成后退出。
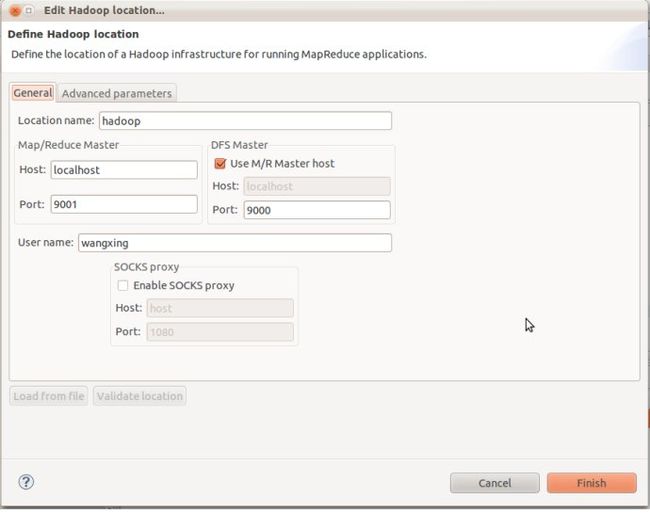
在Window-->Show View中打开Map/Reduce Locations,在Map/Reduce Locations中新建一个Hadoop Location。在这个View中,右键-->New Hadoop Location。在弹出的对话框中你需要配置Location name,如Hadoop,还有Map/Reduce Master和DFS Master。这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。(见1.4的代码)如:
File-->New-->Other-->Map/Reduce Project,项目名可以随便取,如WordCount。
java c++ python cjava c++ javascript helloworld hadoopmapreduce java hadoop hbase
6.通过hadoop的命令在HDFS上创建/tmp/workcount目录,命令如下:
bin/hadoop fs -mkdir /tmp/wordcount
通过copyFromLocal命令把本地的word.txt复制到HDFS上,命令如下:
bin/hadoop fs -copyFromLocal /home/wangxing/Development/eclipseWorkspace/word.txt /tmp/wordcount/word.txt
7.运行项目
(1).在新建的项目Hadoop,点击WordCount.java,右键-->Run As-->Run Configurations
(2).在弹出的Run Configurations对话框中,点Java Application,右键-->New,这时会新建一个application名为WordCount
(3).配置运行参数,点Arguments,在Program arguments中输入你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹,如:
hdfs://localhost:9000/tmp/wordcount/word.txt hdfs://localhost:9000/tmp/wordcount/out
(4)点击Run,运行程序
过段时间将运行完成,等运行结束后,查看例子的输出结果,使用命令:
bin/hadoop fs -ls /tmp/wordcount/out
发现有两个文件夹和一个文件,使用命令查看part-r-00000里的运行结果:
bin/hadoop fs -cat /tmp/wordcount/out/part-r-00000
复制 hadoop安装目录/src/example/org/apache/hadoop/examples/WordCount.java到刚才新建的项目WordCount下,删除WordCount.java首行package
