Linux CFS调度算法核心解析
回家的路上,聊了下CFS调度器…我昨天不是写了一篇批判性的文章嘛:
【为什么Linux CFS调度器没有带来惊艳的碾压效果】
https://blog.csdn.net/dog250/article/details/95729830
确实如此啊,我又没说错啥。
CFS stands for “Completely Fair Scheduler,” and is the new "desktop" process
scheduler implemented by Ingo Molnar and merged in Linux 2.6.23.
发现很多人并不真的理解CFS调度器的思想,所以想写一篇文章说明一下。
就像作者本人说的,CFS调度器的收益本来就在Desktop环境呀,如果不是为了 优雅的提高响应度 ,谁会去用CFS啊,以前的 O ( 1 ) O(1) O(1)调度器也能做到提高响应度,只是不够优雅而已,此外效果也真的并不如CFS,但是Linux的拿手菜不是Desktop呀!
我至今想不通为啥有人会把只运行数据库缓存/查询或者反向代理服务的内核HZ设置成HZ1000,要知道CPU时间对于大规模部署的云服务来讲,那可是真金白银,怎么无休止地消耗在所谓的task切换上,到头来只是为了提高响应度?who care?Web服务进程正在拼命执行倒排索引,啪的一下要switch,flush cache,flush tlb…对于计算密集的服务而言,latency并不重要啊。
先看老调度器算法有什么问题,再说用什么新的算法取而代之。
先看 O ( 1 ) O(1) O(1)调度器,其实该调度器中, O ( 1 ) O(1) O(1)并不是关键,对应的,CFS调度器中的红黑树也不是重点,它们只是 找到下一个投入运行的task的一个操作步骤 。 O ( 1 ) O(1) O(1)调度器真正的核心在于:
- task的优先级线性映射到固定时间片。
- 根据task的优先级做时间片轮转。
举一个例子,我们假设两个优先级分别为 P r i o 1 Prio_1 Prio1和 P r i o 2 Prio_2 Prio2的task P 1 P_1 P1和 P 2 P_2 P2,映射到的时间片分别为10ms,50ms,那么下图展示:

看起来没有任何问题,那么我们如何再创建2个(或多个)优先级为 P r i o 2 Prio_2 Prio2的进程 P 3 P_3 P3和 P 4 P_4 P4呢?

嗯,看到了问题,由于固定优先级映射到了固定的时间片,所以在进程很多的时候,造成调度周期太久,进程饥饿。
在 O ( 1 ) O(1) O(1)的大框架下如何解决这个问题呢?
- 双斜率映射,即低优先级比较抖,高优先级比较缓。
- 设置最大饥饿容忍时间,到时间后强行切换调度。
还好,总算是解决了问题,但是代码却不优雅了,这些措施并不是与生俱来的,而是加入的trick,不好。
再看另一个问题,假如系统中仅仅有两个优先级为 P r i o 1 Prio_1 Prio1的进程呢?按照公式,它们映射到了10ms的时间片:
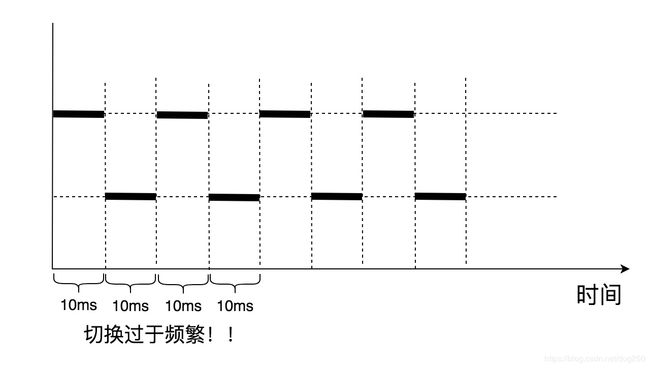
为了解决少数低优先级task共存时切换频繁的问题,又要加入一系列的限制,比如设置task最小时间片什么的,又是一对的trick。
总的来讲, O ( 1 ) O(1) O(1)调度器作用下,task的调度周期随着task的数量增加而线性增加,抖动剧烈,很难扩展:
- 高优先级task过多造成task饥饿。
- 低优先级task过多造成切换频繁。
Linux CFS调度器就是来解决这些问题的,而且是用最简单直接的方法,作为和 O ( 1 ) O(1) O(1)和CFS调度器共同的作者,Ingo Molnar深谙此道。
此外,道理背后,另有深意:
- 这些问题对于计算密集型的task是问题吗?
- 大规模分布式部署的云服务器上会有大量优先级参差不齐的进程存在吗?
- 即便真的有优先级参差不齐的task存在,业务care吗?低优先级的task会不会是故意为之根本不cafe饥饿的呢?
- 真的要因为一些莫须有的名堂完全放弃 O ( 1 ) O(1) O(1)调度器吗?
- HZ1000好,咋不HZ2000呢?
- NOHZ好,咋不轮询呢?
- …
以下我姑且承认就是在Desktop环境,让我们共赏CFS如何见招拆招。
CFS不再以 如何计算时间片 这个问题为核心,换句话说它彻底抛弃了 时间片轮转 的策略,而是改之为 在任意的调度周期内公平分享CPU时间 的问题。
CFS旨在一个调度周期内让所有的task公平分享CPU时间份额。
以100ms的调度周期为例,比如下面的情景:
- 如果系统只有一个最低优先级的进程,那么它将独享这100ms。
- 如果有两个最低优先级的进程,那么第一个先运行50ms,切换到第二个再运行50ms。
- 如果有一个高优先级进程和一个低优先级进程,那么高优先级进程先运行到它的份额结束,切换到低优先级进程运行到100ms。
- …
在具体的事实上,为了让优先级的概念和运行时间片彻底解耦合,CFS将40个优先级映射成了连续的40个权重用于计算:
/*
* Nice levels are multiplicative, with a gentle 10% change for every
* nice level changed. I.e. when a CPU-bound task goes from nice 0 to
* nice 1, it will get ~10% less CPU time than another CPU-bound task
* that remained on nice 0.
*
* The "10% effect" is relative and cumulative: from _any_ nice level,
* if you go up 1 level, it's -10% CPU usage, if you go down 1 level
* it's +10% CPU usage. (to achieve that we use a multiplier of 1.25.
* If a task goes up by ~10% and another task goes down by ~10% then
* the relative distance between them is ~25%.)
*/
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
接下来让我们忘掉优先级,直接使用weight,即权重。
给定一个调度周期的时间 T T T,在 n n n个task的系统中,如何为这 n n n个task分配时间,这其实很简单,设task P n P_n Pn的权重为 w n w_n wn,那么它在调度周期内运行的总时间将会是:
T n = T × w n Σ i = 1 n w i T_n=T\times \dfrac{w_n}{\Sigma_{i=1}^nw_i} Tn=T×Σi=1nwiwn
可以看出,这里每一个task的运行时间 T n T_n Tn并不是固定的,它和总task的数量负相关。这样就做到了对CPU时间资源的 完全加权公平共享 !这便是Linux CFS调度器的核心思想。
实现看起来超级简单:
- 一个进程投入运行时:
P . R u n t i m e = n o w P.Runtime=now P.Runtime=now - 时钟tick时:
Δ T = n o w − P . R u n t i m e \Delta T = now-P.Runtime ΔT=now−P.Runtime
如果 Δ T \Delta T ΔT 大于 T × w n Σ i = 1 n w i T\times \dfrac{w_n}{\Sigma_{i=1}^nw_i} T×Σi=1nwiwn,就切换到下一个task。
但问题是,如何确定哪个task为下一个要执行的task呢?这便是一个 编程实现 问题了。要用一种办法对系统中所有的task按照某种顺序进行排序。
我们注意到CFS的Doc里有关于其实现思想的第一手资料:
80% of CFS’s design can be summed up in a single sentence: CFS basically models
an “ideal, precise multi-tasking CPU” on real hardware.
“Ideal multi-tasking CPU” is a (non-existent ) CPU that has 100% physical
power and which can run each task at precise equal speed, in parallel, each at
1/nr_running speed. For example: if there are 2 tasks running, then it runs
each at 50% physical power — i.e., actually in parallel.
On real hardware, we can run only a single task at once, so we have to
introduce the concept of "virtual runtime." The virtual runtime of a task
specifies when its next timeslice would start execution on the ideal
multi-tasking CPU described above. In practice, the virtual runtime of a task
is its actual runtime normalized to the total number of running tasks.
我们需要对每一个task添加一个 线索字段 用于追踪task的执行时间以确保 完全加权公平 。该字段就是 "virtual runtime" 。换句话说,每一个task的"virtual runtime"必须 趋向于相等 ,这便是保真地模拟了实际上的多个物理CPU,每一个CPU上处理一个进程。理解这一点至关重要,它涉及到了 task执行时间分配和执行空间分配的等价性!
现在,我们假设一共有3个task,其权重分别为1,2,3,那么在调度周期为6ms的时间段内, P 1 P_1 P1, P 2 P_2 P2, P 3 P_3 P3可分别执行1ms,2ms,3ms,在单处理器上,可如下安排时间:

如果我们有3个处理器呢?
那么便可以让3个task分别在这3个处理器上执行,这是显然的。问题是,完全的加权公平,意味着什么?最完美的公平执行,这意味着什么?注意CFS的Doc里描述的:
ideal, precise multi-tasking CPU
我们就需要这个!我们的这3个CPU处理 P 1 P_1 P1, P 2 P_2 P2, P 3 P_3 P3要 “同时开始,同时结束!” ,方为 完全加权公平 。
先看模拟的3个CPU执行3个task:

它们同时开始了,但是却没有同时结束,没有同时结束意味着什么?
意味着先结束执行task的CPU要等待最后结束执行task的CPU结束之后才能启动下一轮的调度周期!这便和 CPU that has 100% physical power 相违背!
我们知道,事实上我们并没有多个CPU,我们只有一个!要想在仅有的一个CPU模拟完全加权公平,就不能引入等待,否则就是不公平。
所以, 3个虚拟CPU的时间流逝是不同的:
- 执行绝对时间久的task的CPU时间流逝慢一些。
- 执行绝对时间短的task的CPU时间流逝快一些。
- 以执行时间不快不慢的task的绝对时间为基本归一化。
最终,我们就有了:

OK,我们有了一个保证公平的线索,在上例中,就是上述的CPU2的基准时间流逝的值,我们已经可以得到,对于一个调度周期时间 T T T内一个权重为 w n w_n wn的task,其执行的绝对时间为 T n T_n Tn,那么其 virtual runtime 就是:
V n = T n × w b a s e w n = T × w n Σ i = 1 n w i × w b a s e w n = T × w b a s e W T o t a l V_n= T_n\times \dfrac{w_{base}}{w_n}=T\times \dfrac{w_n}{\Sigma_{i=1}^nw_i}\times \dfrac{w_{base}}{w_n}=T\times \dfrac{w_{base}}{W_{Total}} Vn=Tn×wnwbase=T×Σi=1nwiwn×wnwbase=T×WTotalwbase
它已经和具体的权重 w n w_n wn无关了,如果按照 w b a s e w_{base} wbase比如上例的 w 2 w_2 w2归一化,即将 w b a s e w_{base} wbase作为 单位1 ,那么在一个调度周期内,每一个task流逝的虚拟时间 virtual runtime 就是:
V 1 = V 2 = . . . = V n = T × 1 W t o t a l V_1=V_2=...=V_n=T\times \dfrac{1}{W_{total}} V1=V2=...=Vn=T×Wtotal1
事实上,我们可以将任意task的权重做基准来计算基准流逝时间,而不一定非要用中间的那个,只所以用中间的那个,只是计算时方便。
自然而然,两次时钟tick时间差 Δ T \Delta T ΔT之间,当前task的 virtual runtime 流逝必须是 Δ T × 1 W t o t a l \Delta T\times \dfrac{1}{W_{total}} ΔT×Wtotal1 才能保证所有task的 virtual runtime 趋向于一致,保证完全公平!
那么,我们最初的问题也就迎刃而解了,当当前task的执行时间超过调度周期内的配额 T n T_n Tn时,如何挑选下一个要执行的task呢?
- 挑选 virtual runtime 累加和最小的即可。
现在让我们更新一下算法:
-
一个进程投入运行时:
P . R u n t i m e = n o w P.Runtime=now P.Runtime=now -
时钟tick时:
Δ T = n o w − P . R u n t i m e \Delta T = now-P.Runtime ΔT=now−P.Runtime
V n = V n + Δ T × 1 W t o t a l V_n = V_n+\Delta T\times \dfrac{1}{W_{total}} Vn=Vn+ΔT×Wtotal1如果 Δ T \Delta T ΔT 大于 T × w n Σ i = 1 n w i T\times \dfrac{w_n}{\Sigma_{i=1}^nw_i} T×Σi=1nwiwn,就切换到下一个task。
-
切换时:
将当前task以 V n V_n Vn为键值插入队列;
在队列中选取 V i V_{i} Vi最小的task投入运行。
以上这些就是Linux CFS的核心了。
在这个核心之外,还有诸多外围的但是并不简单的策略:
- 新的task的 virtual runtime 如何设置。
- 睡眠刚醒的task由于 virtual runtime 已经太久没有推进,如何矫正它。
- 队列如何实现,出了红黑树之外,是不是还有优于 O ( log n ) O(\log n) O(logn)的数据结构。
- 调度周期如何确定,如何计算(可以sysctl配置,但是task太多,会覆盖你的配置,内核自己计算,这里有调优的空间)。
- …
本文并不准备描述这些,已经太晚了,明天还得上班,如果描述这些,难免还是要做源码分析,而这是我最不喜欢做的事情。
现在总结一下,本文主要是想说清三件事情:
- 传统(并不能说是传统…)的 O ( 1 ) O(1) O(1)调度器算法存在什么问题,CFS是如何解决的。
- CFS是如何将空间分配和时间分配互相转换的,这其实是一个很难得的方法论总结(嗯,Tencent最喜欢搞这套说辞…)。
- 虚拟时钟是如何抽象出来的,重点在 CPU that has 100% physical power 已经基准时间倍速流逝。
抽空我再说说当前多核环境下,如何将算法的重心从单CPU调度task转化到多CPU均衡task,这将又是一个时间和空间的故事。
旋转升降座椅,经理的座椅,一定会爆炸,菊花残,满地伤,花落人,断肠,人断肠。
皮鞋啊皮鞋,君不见浙江温州皮鞋湿,下雨进水不会胖。