如何使用 Gridx
简介: Gridx 的是为了弥补 Dojo 现有的 Grid 控件(主要是 DataGrid 及其子类 EnhancedGrid)的各种不足而诞生的。Gridx 脱离了 DataGrid 的框架,具有高度模块化的设计,使其能适应各种使用场景的需要。大量针对 DataGrid/EnhancedGrid 的问题而做出的设计上的改进使 Gridx 具有更高的稳定性和更好的性能。同时,API 的设计更直观,且难以被误用。本文从如何创建和使用 Gridx 入手介绍了 Gridx 的基本特点和基本用法,目的是让您对 Gridx 有一个基本的了解。
准备工作
Gridx 是基于 Dojo 的开源项目,在 GitHub 或者其官网都可以下载到源码包。下载解压后将 gridx 文件夹置于与 dojo、dijit 和 dojox 等文件夹同级的目录即可。目前 Gridx 支持 Dojo1.7+。
gridx/tests 文件夹中有大量的示例页面,可以从修改这些示例页面开始学习使用 Gridx。
回页首
创建 Gridx
Gridx 继承了 dijit._WidgetBase,因此其创建方式和其他 widget 类似,只是有一些必须指定的参数需要特别说明。
选用合适的 store 和 cache
Gridx 与 DataGrid 一样,都以 Dojo 的 store 作为数据源。不过,Gridx 需要用户指出所用的 store 是异步的还是同步的。异步 store 通常由服务器端提供数据,向它请求数据时往往需要异步地接收返回数据;而同步 store 的所有数据一般都在客户端,因此所有的请求都能同步完成。异步 store 往往会带来更为复杂的逻辑,因此 Gridx 针对这两种 store 分别进行了优化。但由于无法从 store 本身得知它是否异步,同时为了减小代码量,用户需要将这个信息告知 Gridx。告知的方法是设置 cacheClass 参数:
清单 1. 创建 Gridx 并配置 cacheClass 参数
require([
"gridx/Grid",
"gridx/core/model/cache/Sync",
......
"dojo/domReady!"
], function(Gridx, Cache, ......){
......
var grid = new Gridx({
cacheClass: Cache
store: store,
......
});
grid.placeAt('gridContainerNode');
grid.startup();
});
|
目前 Gridx 有两种 cache 实现:gridx/core/model/cache/Sync 和 gridx/core/model/cache/Async,前者用于同步 store,后者用于异步 store。Async 的实现逻辑比 Sync 要复杂得多,这是因为它需要考虑数据的延迟加载。这样,如果用户的应用只需要客户端数据,就完全不必用到关于延迟加载的代码,从而减小了最终下载到浏览器的代码量。
cacheClass 既可以直接接受 cache 实现的构造函数(如上例),也可以接受 MID,例如:
清单 2. 用 MID 设置 cacheClass 参数
var grid = new Gridx({
cacheClass: "gridx/core/model/cache/Async"
......
});
|
这种写法更适合以 HTML 声明的方式创建 Gridx 的场合,因为它不需要引入额外的变量。
目前 Gridx 能够直接支持 dojo(x)/data/* 的老 store 以及 dojo/store/* 的新 store,而不需要任何适配转换。常用的同步 store 有 dojo/data/ItemFileWriteStore 以及 dojo/store/Memory。常用的异步 store 有 dojox/data/JsonRestStore、dojox/data/QueryReadStore 以及 dojo/store/JsonRest。
需要特别注意的是,Gridx 要求 store 中的数据行必须具有唯一标识符(ID)。对于老 store 而言,也就是必须要实现 dojo/data/api/Identity。所幸刚才列举的常用 store 都满足这个要求。
声明列
配好 store 并选择好 cache 之后,就需要声明 Gridx 的列结构。列声明使用 structure 参数,这和 DataGrid 类似。所不同的是,Gridx 的列声明结构非常简单,只支持一维数组,没有 DataGrid 中视图(View)和子行(rows/cells)等复杂的声明结构:
清单 3. 一维数组结构的列声明
var grid = new Gridx({
cacheClass: Cache
store: store,
structure: [
{id: 'column1', ......},
{id: 'column2', ......},
{id: 'column3', ......},
......
]
});
|
下面各小节详细介绍列声明中各个属性的含义。
id、name、field
对于 Gridx 来说,每一列都有一个唯一标识符(ID)。用户最好能指定一些有意义的 ID,从而方便以后的使用。如果用户没有指定,那么 Gridx 会分别赋予"1", "2", "3", ....... 等字符串类型的自然数作为列的默认 ID。
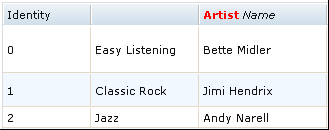
与 DataGrid 类似,name 属性是指表头上显示出来的列名。name 属性可以是任意字符串,甚至可以包含 HTML 标签,从而做出各种定制效果。例如:{id: 'column1', name: 'Company Name'}。
field 属性也是从 DataGrid 沿袭下来的,指该列在 store 中的对应域。该列中的单元格会从这个 field 域中取得数据。
图 1. name 属性作为普通字符串、未指定、以及带 HTML/CSS 的各种情况
formatter 函数
Gridx 的 formatter 函数与 DataGrid 中的同名函数不同,其目的在于为 Gridx 提供数据,而不是对数据做显示上的修饰。如果某一列没有 field 参数,就可以通过 formatter 函数来提供数据,例如:
清单 4. 使用 formatter 函数组合多个域的数据
{id: 'column1', formatter: function(rawData){
return rawData.field1 + rawData.field2;
});
|
这样,这一列就能显示两个数据域的和。
图 2. formatter 函数综合多个数据域的内容产生了 Summary 列中的数据
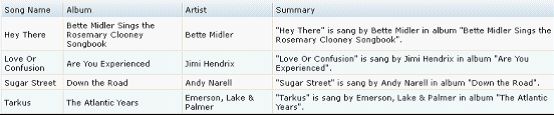
formatter 函数所传入的 rawData 参数是以 store 的 field 名称作为 key 的关联数组(对象),包含当前行中的所有数据,形如:
清单 5. rawData 格式
rawData: {
field1: data1,
field2: data2,
......
}
|
这种形式要比某些 store(主要是老 store)的数据项(item)更容易使用,也使接口与新 store 保持一致。
decorator 函数
Gridx 对数据的产生和数据的修饰做了严格的区分。formatter 是用于产生数据,decorator 函数则用于修饰数据。例如:
清单 6. 用 decorator 函数为单元格添加 HTML/CSS
{id: 'column1', field: 'field1',
decorator: function(cellData, rowId, rowIndex){
return "" +
cellData + "";
}
}
|
这样就能在单元格中显示出链接。
图 3. 使用 decorator 对数据做修饰

decorator 函数只能返回字符串,不像 DataGrid 的 formatter 函数还可以返回 widget 实例。关于如何在单元格中显示 widget 的问题将在其他文章中详细介绍。
style 和 class
通过在 decorator 函数中加入 HTML 标签和 style 属性可以对单元格中的内容做各种修饰,但无法改变单元格本身的样式。要做到这一点,需要 style 或 class:
清单 7. 字符串形式的 style 和 class 参数
{id: 'column1', field: 'field1',
style: 'text-align: center;',
'class': 'mySpecialColumn'
}
|
style 和 class 都会直接加入到
style 和 class 还可以写成一个返回字符串的函数,这样单元格的样式就能随数据而变化:
清单 8. 函数形式的 style 和 class 参数
{id: 'column1', field: 'field1',
style: function(cell){
return cell.data() % 2 ? 'color: red;' : 'color: blue;';
},
'class': function(cell){
return cell.data() %2 ? 'oddClass' : 'evenClass';
}
}
|
这里 style 和 class 函数所传入的 cell 参数代表了当前所处理的单元格,可以通过各种方便的方法获取有关该单元格的一切信息。
图 4. 使用 style 函数为每一个单元格设置独特背景色的例子
配置功能模块
有了 store、cacheClass 和 structure 后,Gridx 就能运行了。不过这样的 Gridx 除了显示数据之外,几乎没有任何界面功能。Gridx 几乎所有的功能都是由可选模块(module)实现的,需要在创建时声明使用了那些模块。这提供了巨大的灵活性来满足各种不同的需求。
声明模块的是 modules 属性:
清单 9. 通过 modules 参数配置功能模块
require([
"gridx/Grid",
"gridx/core/model/cache/Sync",
"gridx/modules/VirtualVScroller",
"gridx/modules/ColumnResizer",
"gridx/modules/Focus",
"gridx/modules/SingleSort",
......
dojo/domReady!"
], function(Gridx, Cache, VirtualVScroller, ColumnResizer, Focus, SingleSort, ......){
......
var grid = new Gridx({
cacheClass: Cache
store: store,
structure: structure,
vScrollerLazy: true,// 模块参数可作为 Gridx 参数传递
modules: [
VirtualVScroller, // 用法 1:直接列举模块构造函数
"gridx/modules/ColumnResizer", // 用法 2:模块 MID
{ // 用法 3:带有 moduleClass 的对象
moduleClass: SingleSort,
initialOrder: { colId: 'column1', descending: true }
},
{ // 用法 4: moduleClass 也接受 MID
moduleClass: "gridx/modules/Focus"
}
]
});
......
});
|
从上面的例子可见,要使用一个模块先要引入该模块的文件,然后直接列举在 modules 数组中即可。modules 数组中的模块既可以是模块构造函数本身,也可以是模块的 MID,还可以是一个含有 moduleClass 属性的对象。模块本身也可能有参数,这些参数既可以与 moduleClass 一起放在一个对象里(如 initialOrder),也可以直接作为 Gridx 的参数,只不过需要加上所属模块的名称作为前缀(如 vScrollerLazy,这里 vScroller 是模块名称,lazy 是属性名,加上前缀后首字母大写)。模块参数直接作为 Gridx 参数可以使代码更为简洁,因此是推荐的配置方法。
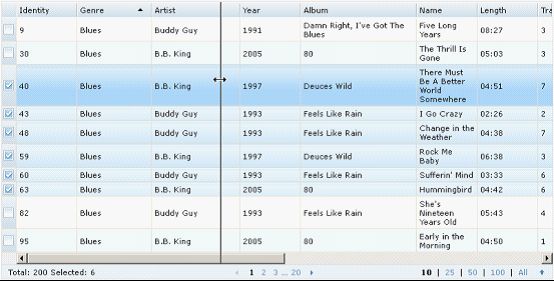
上面的例子中加入了 4 个模块:VirtualVScroller 实现了延迟渲染的功能,每次只渲染出需要显示的行,从而可以很快地完成拥有大量数据的 Grid 的创建;ColumnResizer 实现了鼠标拖动改变列宽的功能;SingleSort 是一个单列排序的简单实现;Focus 模块则是对键盘的支持,这是一个被许多其他模块引用的模块,对于 A11y 非常重要。
熟悉 DataGrid 的用户会发现这些功能在 DataGrid 中都是默认自带的。虽然这些功能很常用,但用户在不需要它们的时候却难以屏蔽;即使能够屏蔽它们的功能,大量的有关这些功能的代码也依旧存在,而这不失为一种浪费。
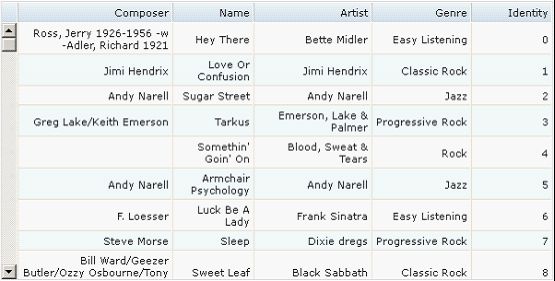
图 5. 启用了排序、分页、改变列宽、行选择、行首勾选框等多个模块的 Gridx
Gridx 的模块化是其最大的特点之一。其实 Gridx 的所有用户界面(包括表头、数据行、纵向滚动条、横向滚动条等)都是模块,只不过这些模块是默认加载的核心模块而已。所谓创建 Gridx 其实就是在一个很小的逻辑内核(称为 Core)的基础上依次创建这些模块。模块之间秉承低耦合的原则,只以 API 和功能相联系而不涉及具体实现,因此几乎所有的模块都是可替换的。同时模块本身是高内聚的,使得维护和调试也更为方便。
其他配置参数
Gridx 本身还有少数几个参数:如 autoHeight 和 autoWidth,可以由行高和列宽来决定 Gridx 的高度和大小;使用 cache/Async 时的 cacheSize 参数可以配置保存在客户端的最大行数,而 pageSize 可是每次向 store 请求数据时的推荐请求行数。这些参数只有在特殊需求下才有必要使用,具体用法可关注 Gridx 文档。
创建 Gridx 时还有一个基本要求就是要指定 Gridx 的大小。Gridx 与 DataGrid 不同,没有默认高度(DataGrid 有 6em 的默认高度),因此必须通过 CSS 为 Gridx 指定高度(除非使用 autoHeight)。同样,也没有默认宽度。
目前 Gridx 只支持 Claro 主题,通过 gridx/resources/claro/Gridx.css 可以引入所有与 Gridx 相关的样式。若要支持 RTL,还需要引入 gridx/resources/claro/Gridx_rtl.css。
图 6. RTL 状态下采用了 autoWidth 的 Gridx
回页首
使用 Gridx API
Gridx 本身的 API 很少,主要的 API 来源是其数据模型(grid.model)和各个模块。
数据模型 API
Gridx 的数据模型(grid.model)是其 MVC 模式的 M 部分,是整个 Grid 的数据层和逻辑层,没有任何用户界面(甚至可以单独使用)。grid.model 的 API 就是为了与 Gridx 的数据进行便捷的交互。主要 API 有:
清单 10. grid.model 的常用 API
grid.model.byIndex(rowIndex); grid.model.byId(rowId); grid.model.indexToId(rowIndex); grid.model.idToIndex(rowId); grid.model.size(); grid.model.when(request, callback); |
可见除了最后一个 when 函数,都是取数据的 API。这个 when 函数是数据模型中唯一的异步函数,它可以接受一个回调函数作为参数,也会返回一个 Deferred 对象。其语义是:当所请求 request 的数据行都已加载到客户端,且所有改变数据的操作都完成时,调用回调函数 callback。因此典型的用法是:
清单 11. grid.model.when 的用法
grid.model.when([1, 3, 5, 7, 9], function(){
// 获取第 5 行的 ID
var rowId = grid.model.indexToId(5);
// 获取第 1 行的数据
var rowData = grid.model.byIndex(1).data;
// 获取第 9 行的 item
var storeItem = grid.model.byIndex(9).item;
});
|
这里的 [1, 3, 5, 7, 9] 是用 index 的方式来请求行。Gridx 也支持通过范围的方式来请求行:
grid.model.when({start: 0, count: 20}, ....);
|
或是用 ID 来请求行:
grid.model.when({id: ['row1', 'row2']}, ....);
|
更多用法请参见文档。
grid.model 还有一些 API 可以对数据行的顺序进行改变或者过滤,例如:
清单 12. 改变数据模型的 API
grid.model.sort(); grid.model.query(); grid.model.filter(); grid.model.move(); |
这些功能其实是由 model 的扩展(modelExtension)实现的。如果今后出现了其他类型的数据操作需求,就可以以这种扩展的形式进行补充。
注意到 Gridx 的数据模型没有提供插入、删除、修改数据的方法,这是因为这些操作都可以直接通过 store 的 API 来完成,Gridx 并不需要提供重复的接口。
模块 API
模块 API 是 Gridx 的另一大 API 来源。Gridx 的几乎所有模块都可以通过 Gridx 实例直接访问到。例如:
清单 13. 访问模块 API
grid.sort.clear(); // 调用 sort 模块的 clear 方法。 grid.columnResizer.setWidth(); // 调用 columnResizer 模块的 setWidth 方法。 grid.select.row.getSelectedIds(); // 行选择模块的 getSelectedIds 方法 grid.select.column.selectById(); // 列选择模块的 selectById 方法 // 甚至核心模块也不例外: grid.header.hidden = true; grid.body.refresh(); grid.vScroller.scrollToRow(); |
由于每一个模块都有自己的名字空间,因此不容易引发命名冲突。有的模块(如行列选择等)甚至可以创造出更深层次的命名空间,从而使 API 的命名更精简。
Gridx 几乎所有主要的功能 API 都由模块提供,这其实简化了各个 API 的命名。例如 selectRow 模块和 selectColumn 模块都可以有 selectById 函数,命名精简的同时在使用的时候仍然具有清晰的语义。每个模块具体的 API 请参考 Gridx 文档。
行、列、单元格
行、列和单元格是 Grid 中非常直观的界面元素,因此在 Gridx 中它们都有各自的对象表示,使用起来非常方便:
清单 14. 行、列、单元格对象使用举例
var row = grid.row(1); // 获取第 2 行(行号从 0 开始)
var row = grid.row('rowId'); // 获取标识符为 rowId 的行
var column = grid.column(3); // 获取第 4 列
var column = grid.column('columnId'); // 获取标识符为 columnId 的列
var cell = grid.cell(2, 3); // 获取位于第 3 行第 4 列的单元格
|
这些对象只是 API 的集合,而没有任何状态,因此不用担心一个 row 对象会因为 Grid 经过某种改变(例如排序)之后而失效。例如:
清单 15. 数据模型改变前后同一个行、列或单元格对象仍然有效
var row = grid.row('rowId'); // 获取一个行对象
var indexBeforeSort = row.index(); // 获取排序前的行号
grid.column('column1').sort(); // 排序
grid.model.when({id: 'rowId'}, function(){ // 等待数据更新
var indexAfterSort = row.index(); // 从同一个 row 对象中获取排序后的行号
});
|
行和列对象中的只有只读的 id 属性不是函数,由此来唯一地指代一行或一列。
单元格对象的 row 和 column 也是只读属性而不是函数,分别表示该单元格所在的行和列:
grid.cell(1, 2).row.id; // 获取第 2 行第 3 列的单元格的行 ID。 |
Gridx 的模块可以向这些对象中增加方法来增强它们的能力。例如一旦启用了 gridx/modules/move/Row 模块,就能写出如下代码:
grid.row(2).moveTo(10); // 将第 3 行移动到第 11 行的位置 |
回页首
使用 Gridx 事件
Gridx 的各个部分都可以和用户交互,因此需要支持各种鼠标和键盘事件。不仅如此,在 Gridx 生命周期以及使用过程中还会出现许多与特定功能相关的“事件”,例如渲染、选择等等。
鼠标键盘事件
Gridx 上继承了 DataGrid 的事件命名方式(on + 界面对象 + 事件类型),但提供的事件更全面,信息更完善。Gridx 提供下表中的所有组合:
表 1.Gridx 支持的所有鼠标键盘事件
| Cell | HeaderCell | Row | Header | |
|---|---|---|---|---|
| Click | onCellClick | onHeaderCellClick | onRowClick | onHeaderClick |
| DblClick | onCellDblClick | onHeaderCellDblClick | onRowDblClick | onHeaderDblClick |
| MouseDown | onCellMouseDown | onHeaderCellMouseDown | onRowMouseDown | onHeaderMouseDown |
| MouseUp | onCellMouseUp | onHeaderCellMouseUp | onRowMouseUp | onHeaderMouseUp |
| MouseOver | onCellMouseOver | onHeaderCellMouseOver | onRowMouseOver | onHeaderMouseOver |
| MouseOut | onCellMouseOut | onHeaderCellMouseOut | onRowMouseOut | onHeaderMouseOut |
| MouseMove | onCellMouseMove | onHeaderCellMouseMove | onRowMouseMove | onHeaderMouseMove |
| ContextMenu | onCellContextMenu | onHeaderCellContextMenu | onRowContextMenu | onHeaderContextMenu |
| KeyDown | onCellKeyDown | onHeaderCellKeyDown | onRowKeyDown | onHeaderKeyDown |
| KeyPress | onCellKeyPress | onHeaderCellKeyPress | onRowKeyPress | onHeaderKeyPress |
| KeyUp | onCellKeyUp | onCellKeyUp | onRowKeyUp | onHeaderKeyUp |
对所有的 Row 事件,都会在事件对象中提供以下信息:
清单 16. 事件对象上提供的附加信息
evt.rowId // 行 ID evt.parentId // 如果该行是子行,则提供父行 ID evt.rowIndex // 行号(与分页、展开状态无关) evt.visualIndex // 在当前页中实际显示是第几行(与分页、树节点展开状态有关) |
由于 Grid 可能分页显示或者有可展开的树节点,因此有逻辑行号(rowIndex)和实际显示位置(visualIndex)的区别。逻辑行号表示该行在其父行之下是第几个子行(所有根节点行都假设有一个虚构的父行);显示位置则表示该行在当前视图中处于第几行。
对于 Cell 事件,除了所有的行信息之外还提供列 ID 和列序号:
evt.columnId // 列 ID evt.columnIndex // 列号 |
HeaderCell 事件只有列信息,Header 事件则没有附加信息。
另外,所有这些事件都是空函数,因此可以在创建 Grid 时直接以参数形式给出:
清单 17. 以初始化参数形式提供的事件处理函数
var grid = new Gridx({
cacheClass: Cache,
store: store,
structure: structure,
onCellClick: function(evt){...} // 可以安全覆盖原来的空函数
});
|
当然,用 connect 连接也是推荐的方式:
清单 18. 以 connect 方式连接的事件处理函数
grid.connect(grid, 'onCellClick', function(evt){
var cell = grid.cell(evt.rowId, evt.columnId);
......
});
|
Grid 事件和模块事件
除了鼠标键盘事件之外,Gridx 本身和各个模块也会提供一些“钩子”函数作为事件挂载点,让用户对 Gridx 的运行过程有更好的控制。例如:
清单 19. 模块加载完毕事件
grid.connect(grid, 'onModulesLoaded', function(){
// 所有模块加载完毕
});
|
onModulesLoaded 事件会在所有模块都加载完毕后触发,可以认为是 Gridx 初始化完成的标志。
清单 20. 数据区域渲染事件
grid.connect(grid.body, 'onRender', function(){
// 数据区域进行了渲染
});
|
当 Gridx 的数据区域进行渲染的时候(例如滚动或刷新显示以后),grid.body 模块会触发 onRender 事件。
清单 21. 行选择事件
grid.connect(grid.select.row, 'onSelected', function(row){
//row 被选中时触发
});
|
当一行被选中时,grid.select.row 模块会触发'onSelected'事件。
类似的模块事件还有很多,请参考 Gridx 文档。
回页首
结束语
本文从创建和 API 使用的角度介绍了 Gridx 的基本用法,强调了 Gridx 的模块化和直观的 API 设计。限于篇幅,更多关于 Gridx 的新特性无法在本文中涵盖,例如新的延迟渲染机制、新的拖放机制、以及新的树结构支持等等。这些内容将在其他文章中做进一步介绍。对 Gridx 各个功能模块及其 API 的详细描述还请参考 Gridx 文档和 Github 网站。
参考资料
学习
- Gridx 官方网站:包含 Gridx 的最新动态。
- Gridx 功能展示:了解 Gridx 的新功能
- Gridx 的 GitHub 首页:参与 Gridx 开发及讨论
- 深入了解 Gridx 的数据模型:介绍了 gridx.model 的设计
- Gridx 1.0 API 文档。
- developerWorks Web development 专区:通过专门关于 Web 技术的文章和教程,扩展您在网站开发方面的技能。
- developerWorks Ajax 资源中心:这是有关 Ajax 编程模型信息的一站式中心,包括很多文档、教程、论坛、blog、wiki 和新闻。任何 Ajax 的新信息都能在这里找到。
- developerWorks Web 2.0 资源中心,这是有关 Web 2.0 相关信息的一站式中心,包括大量 Web 2.0 技术文章、教程、下载和相关技术资源。您还可以通过 Web 2.0 新手入门 栏目,迅速了解 Web 2.0 的相关概念。
- 查看 HTML5 专题,了解更多和 HTML5 相关的知识和动向。