Ceph 进阶系列(一):一些基本概念(1 of 2,偏client端 )
推荐的三本中文书:
- 《Ceph设计原理与实现》-- 概念入门阶段
- 《Ceph分布式存储实战》-- 安装部署阶段
- 《Ceph源码分析》 -- 撸代码阶段
带着问题 看书/看源码/看blog,搞事情:
1. 什么是pool?
pool是一个抽象的存储池。它规定了数据冗余的类型以及对应的副本分布策略。目前实现了两种pool类型:replicated类型(副本类型)和Erasure Code类型(纠错码类型)。一个pool由多个PG构成。
2. 什么是PG?
PG(placement group)从名字可理解为一个放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略:对
象的副本都分布在相同的OSD列表上。一个对象只能属于一个PG,一个PG对应于放置在其上的OSD列表。一个OSD上可以分布
多个PG。Ceph数据迁移的基本单位是PG,即数据迁移是将PG中的所有对象作为一个整体来迁移。
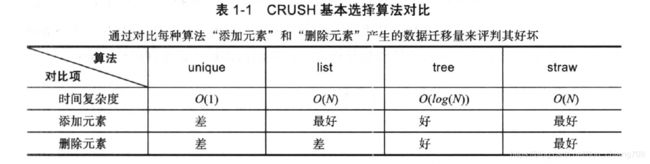
3. CRUSH是什么? 为什么要有CRUSH? CRUSH里有哪些基本选择算法?
CRUSH(Controlled Replication Under Scalable Hashing)是一种基于HASH的数据分布式算法。通过相应格式的输入(数据唯一标识符/当前存储集群的拓扑结构/数据备份测率),可以随时随地计算过获取数据所在的底层存储设备的位置并直接与其通信,从而避免查表操作,是实现去中心化和高度并发。
基本选择算法有:unique/list/tree/straw(straw2)
linux kernel 里 net/ceph/crush/crush.c里的代码:unique -> uniform
case CRUSH_BUCKET_UNIFORM: return "uniform";
case CRUSH_BUCKET_LIST: return "list";
case CRUSH_BUCKET_TREE: return "tree";
case CRUSH_BUCKET_STRAW: return "straw";
case CRUSH_BUCKET_STRAW2: return "straw2";
4. 什么是Cluster Map(集群的层级化描述)?权重值weight怎么计算?
Cluster Map:集群的层级化描述,描述Ceph集群的拓扑结构容器。

Cluster Map保存了系统的全局信息,主要包括:
·Monitor Map
·包括集群的fsid
·所有Monitor的地址和端口
·current epoch
·OSD Map:所有OSD的列表,和OSD的状态等。
·MDS Map:所有的MDS的列表和状态。
层级化的Cluster Map的一些基本概念如下:
·Device:最基本的存储设备,也就是OSD,一个OSD对应一个磁盘存储设备。
·bucket:设备的容器,可以递归的包含多个设备或者子类型的bucket。bucket的类型:bucket可以有很多的类型,例如host就代表了一个节点,可以包含多个device。Rack就
是机架,包含多个host等。在Ceph里默认的有root、datacenter、room、row、rack、host六个等级。用户也可以自己定义新的类型。每个device都设置了自己的权重,和自己的存
储空间相关。bucket的权重就是子bucket(或者设备)的权重之和。
5. 什么是Placement Rule(数据分布策略)? 有哪些操作?
Placement Rule:指Ceph集群的数据分布策略,完成数据映射。
有3种操作类型:take/select/emit

6. 什么是CRUSH Map?如何导出CRUSH Map到文件?怎么编辑及使用它(反编译(或导出)/编译)?
CRUSH算法解决了PG的副本如何分布在集群的OSD上的问题。

CRUSH map = cluster map + placement rule
