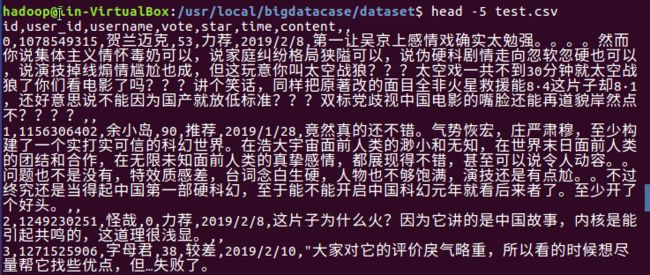
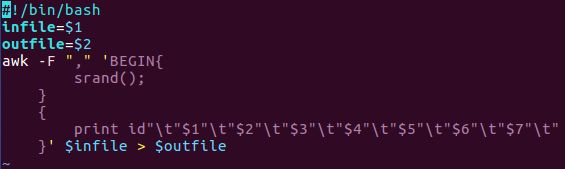
- 2012-6-3 金学伟:在混沌中寻找有序
Jasmine_yao
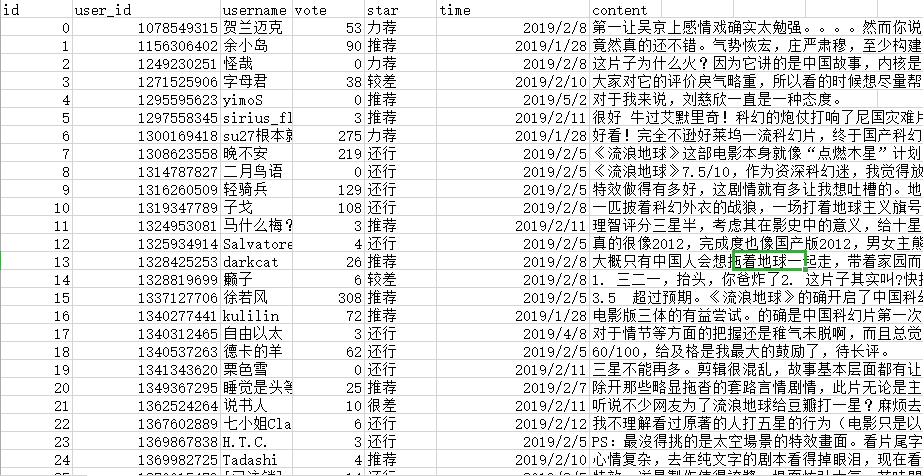
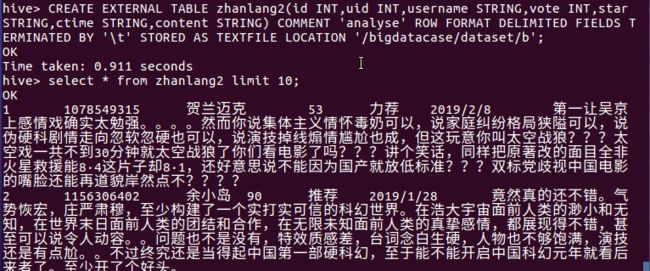
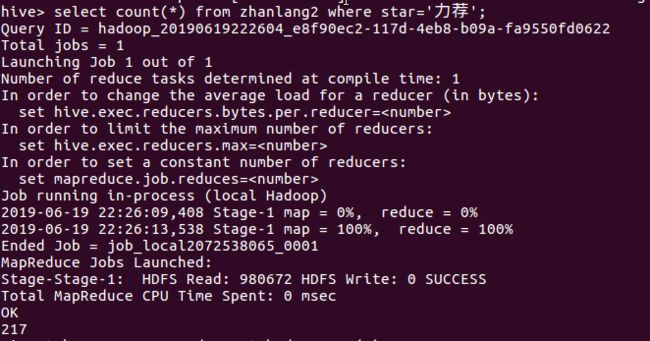
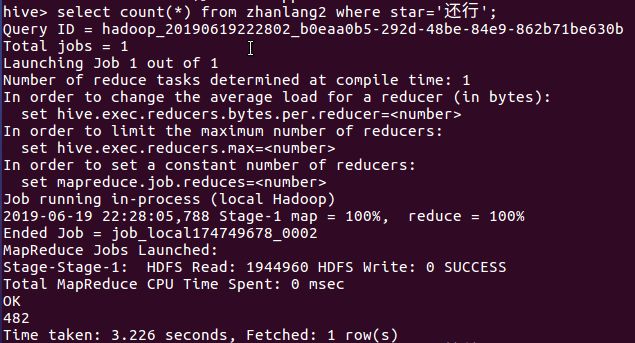
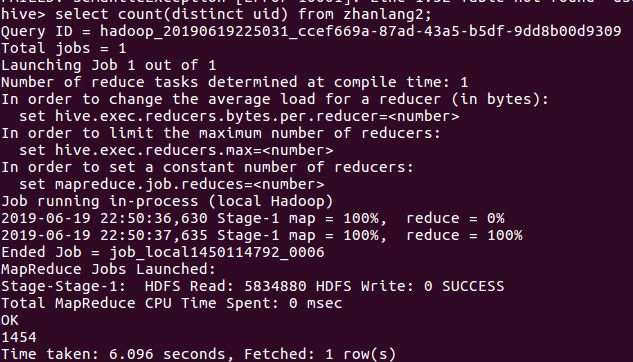
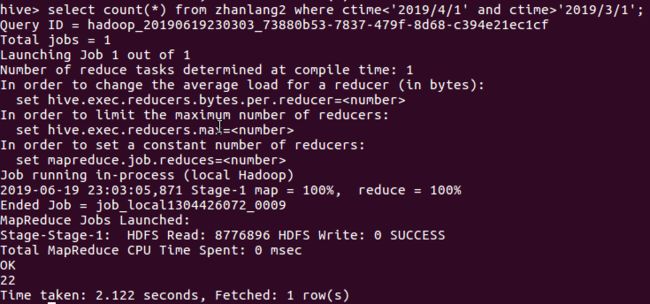
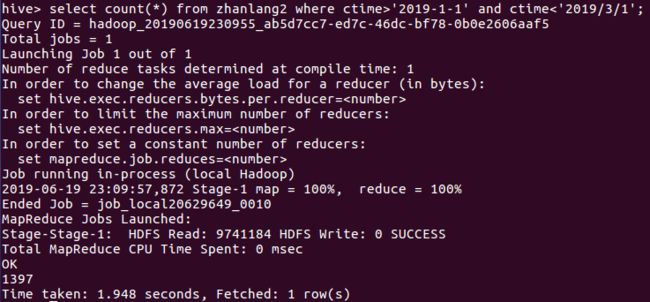
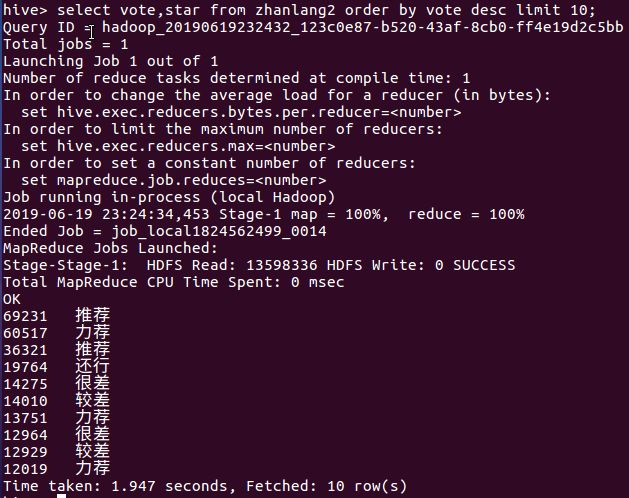
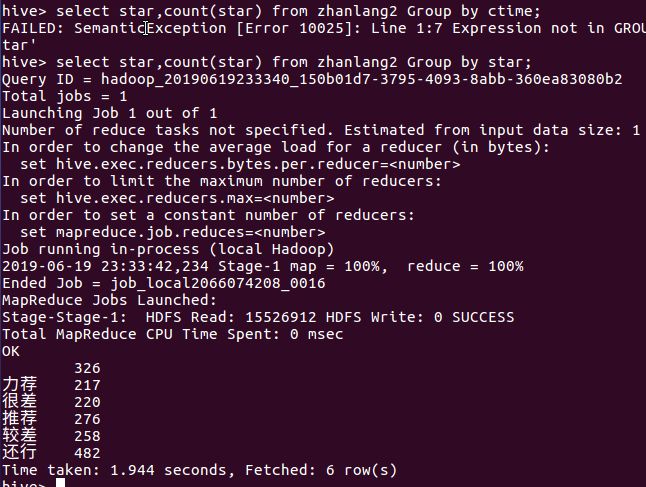
5月26日我在公司给客户讲课并给不能前来现场的客户录制视频。讲课中我演示了一组数据——(1429-386)÷1429=0.7299(1558-325)÷1558=0.7914(1052-512)÷1052=0.5133(2245-998)÷2245=0.5554(6124-1664)÷6124=0.7283(3478-2132)÷3478=0.387这是1992年以来6次重大调整(幅度超过50%或
- 软件从业人员高发疾病排行整理
两圆相切
健康健康
软件从业人员因职业特性(如久坐、高用眼强度、高压、饮食作息不规律等)发病率显著高于其他人群的常见健康问题详细介绍。 核心诱因:久坐不动+超高强度用眼+长期精神压力+不良工作生活习惯+特定工作环境。 排名依据:综合发病率、对工作生活的直接影响程度、与职业的关联紧密性。一、肌肉骨骼系统疾病(骨科/康复科)核心问题:颈椎病、腰椎间盘突出、肩周炎、腕管综合征、腱鞘炎(尤其是鼠标手)、腰肌劳损、梨状
- 【云原生】Helm来管理Kubernetes集群的详细使用方法与综合应用实战
景天科技苑
云原生K8S零基础到进阶实战云原生kubernetes容器Helmk8sk8s集群
✨✨欢迎大家来到景天科技苑✨✨养成好习惯,先赞后看哦~作者简介:景天科技苑《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。《博客》:Python全栈,前后端开发,小程序开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django,fastapi,flask等框架,云原生k8s,linux,she
- 《我的爷爷》第16章 婚礼
赵同小异
作者:赵同第十六章婚礼半年前那场职工联谊活动收获最多的人就是研究所的丁良平,在春节之前双方家庭同意后,丁良平和焦炀在大学食堂举行了一个简单婚礼。程学鹏和关茉芬作为新郎新娘的好朋友也来参加了婚礼,这是他们回到滨海市的第一次碰面。给丁良平主持婚礼的是他们研究所的领导石主任。一番慷慨激昂的讲话后,石主任从台上下来坐到了程学鹏的旁边。“你是管理学院的小程?”老石问旁边的程学鹏。“是,石主任您好。”程学鹏恭
- spring-framework之AnnotatedBeanDefinitionReader解析
澹泊明志 宁静致远
Spring系列javaspring软件框架
AnnotatedBeanDefinitionReader的作用Spring源码中类的命名还是很讲究的,AnnotatedBeanDefinitionReader它的作用如同它本身的命名,主要是为了解析带有注解的bean的beanDefinition,并将其注册到Bean工厂中。在此类的注释中也有介绍,功能与ClassPathBeanDefinitionScanner类似,但是不同的是Annota
- “解读《文化自信和民族复兴》”(76)“七个家庭幸福的着力点"之“超越交易层面的爱”
周安柱
家庭幸福要突破的第二个重要元素:“千万不要把爱变成交换”。古人有“仁者爱人”之说,既然我们选定了“爱人”作为伴侣,就是要付出自己的爱心,透过和伴侣及家人的互动,来生长和绽放我们的爱心,这其实就是“恋爱(心)”的秘诀。如果把爱伴侣及家人变成了一种“交易”,不断的换算对方给我多一些爱时才多付出爱,对方少给自己些爱时就少付出些爱,甚至总是期望对方多爱自己,多满足自己的需要,却很少真正爱对方及成就对方,这
- 2021关注亲情,珍惜友情,走好自己规划之路,此生无憾
小小白杨天天长
都说流星有求必应,2021我许下三个愿望亲情:感谢父母养育之恩。友情:友谊之花四季常青。人生之路:踏平坎坷,走出无悔人生。相信都能实现。过去已成历史,当下正在经历,未来希望无限。有生之年,不留遗憾。图|源自网络|侵删01亲情:常回家看看马克思说:还有什么比父母心中蕴藏着的情感更为神圣的呢?父母的心,是最仁慈的法官,是最贴心的朋友,是爱的太阳,它的光焰照耀、温暖着凝聚在我们心灵深处的意向!父母的爱永
- 2021-08-10:误判的心理——查理·芒格对人类心理学研究所在 [1]
会说话的河马
昨天谈到盲点很难发现,涉及了一点人的心理。今天想了想,想停下来稍微来聊一下人复杂的心理。心理学其实是一门实证主义的学科,并不是很多人理解伪科学。同时心理学确又是不断在自我颠覆的学科,很多今天人理解的心理学现象的解释,已经经历过很多个理论或版本的演绎了。因为工作关系,需要学习心理学。不是专业学这个的门外汉要学一点专业性很强的学科,总是避免不要要找大众读物来科普自己。在汗牛充栋的心理学大厦门前,我拜读
- 现实就是如此
大雄ETony
除了有一个大专文凭,其他的好像什么都不会。要算专业的话,专业知识早就忘光了,英语四级也没过。想找工作,就连找份销售都难找到适合的,没有能力的我,只能苦苦地面对世间的黑与白。有时候真的不知道何去何从,前路是何方?也恰恰是在这个时候,很容易产生沮丧不安各种坏情绪,也很容易堕落。没钱,还没有为之奋斗的方向,还被感情挫折折磨着,此刻是我人生中最黑暗的时候了。也许如果有个人轻轻的推一下,我就会陷入万丈深渊,
- 某网安公司护网红队面试经验分享
掌控安全官号
面试经验分享职场和发展
所在城市:成都面试职位:2025年护网红队面试过程:线下1V2面试,大概40分钟吧。上次侥幸过了一面,这次记录下二面经过。技术问题问得都比较深入,要求对原理系统掌握,其次综合性要求也比一面要高不少,好几个问题我都被追问的没啥思路了,汗。当前环境下,网安圈也越来越卷,希望给最近找工作的小伙伴们提供参考,祝愿大家早日找到“薪”满意足的好工作。面试官的问题:问题1、如何绕过CDN获取目标网站真实IP?查
- Python类中魔术方法(Magic Methods)完全指南:从入门到精通
盛夏绽放
python开发语言
文章目录Python类中魔术方法(MagicMethods)完全指南:从入门到精通一、魔术方法基础1.什么是魔术方法?2.魔术方法的特点二、常用魔术方法分类详解1.对象创建与初始化2.对象表示与字符串转换3.比较运算符重载4.算术运算符重载5.容器类型模拟6.上下文管理器7.可调用对象三、高级魔术方法1.属性访问控制2.描述符协议3.数值类型转换四、魔术方法最佳实践五、综合案例:自定义分数类Pyt
- 注意:脸部脂肪大作战将开始,还不来参加?
简小微
俗话说“一白遮三丑,一高遮五丑,一瘦遮七丑,一富遮百丑”,但最终还是会归为“一胖毁所有”。因为现在的审美天平向纤细倾斜。无论男女,他们都对肥胖避之不及。也是因为大众审美的一致性,导致减肥成为了大家日日挂在口边的事。但是,每个人的胖也不是相同的。有人是四肢肥胖;有的人是肚子胖;有的人是单独脸胖;有的人是全身胖。但在这众多的肥胖类型中,脸胖是最难解决的,也是大家最头疼的。身体的肥胖大多可以通过运动来解
- 天路
猫姐猫姐
今天单位公差,到张家口,路上很多限速,限到70迈,四个小时才到,所幸到了中午,把所有的该做的事情都做好了,这才踏实下来。很喜欢张家口这个城市,冬季寒冷,夏季凉爽,是避暑胜地,草原天路风光无限,有花之妩媚,也有山之伟岸。天然景色,优美宜人,推荐朋友们一定去游览。
- 灵契之绚烂
泡泡国漫漫研社
文|泡泡圈漫评团九•落叶“端木熙!”杨敬华看着正埋在书里的某人愤愤不平,“怎么了?”端木熙视线从书上移开,打量着杨敬华。“我说端木,你就这样打算整天在家看书?”杨敬华随手拿了一本书翻了几页。“嗯。”简短的一个字让杨敬华险些跌倒。“端木,我很想知道你以前是怎么过日子的!”杨敬华有些无语地看着他。“以前啊!”端木熙放下手中的书,看着杨敬华。“以前不是工作就是上学或者在家看书。”好吧!杨敬华服了。“行了
- “解读《文化自信和民族复兴》”(54)“五个数字背后的启迪 之"心上用功的3.0企业家"
周安柱
客户不仅需要物质财富,更渴望精神财富。当企业家在提供产品和服务的过程中成就客户建设心灵品质,则他所从事的事业就与化育人心的事业相应。相对于在事上用功的企业家,1.0企业家在德上用功,2.0企业家在道上用功,3.0企业家在心上用功。3.0企业家培养3.0团队,制定3.0战略,打造3.0产品,不仅满足客户的物质需求,而且通过成就员工与客户建设心灵品质以满足其精神需求,极大提高利益员工与客户的价值,从而
- 【家庭经济学】陈健
中流砥柱陈健
【家庭经济学专栏】陈健(356)林园6确定性卖出“老公,老公”朱姨渐渐地觉得,林园的投.资策略更接地气,一早起来,就煮水泡茶,听朱公吹水。朱公品了口茶,“老婆,林园的确定性还有一个,就是确定性卖出。”“懂得卖出才是师傅啊!他怎卖出呢?”“他介绍了五种离场的方法。”朱公扳起拇指,“首先是持股公司经营困难;如果企业产品的毛利率有下降趋势,最终得到确认,就会坚决卖掉股.票。”“林园还提醒投资者说,股市最
- 2021-09-15
刘晓琳_6c39
家伙今天在幼儿园学关于小宝宝的问题了说是卵子和精子合起来住个小房子爸爸的像个小蝌蚪,妈妈的像个小水母、小太阳、小花小宝宝看肚脐眼吃饭小宝宝里面还有水还能游泳来
- 前端面试十一之TS
闲蛋小超人笑嘻嘻
前端
TS是TypeScript的缩写,是一种由微软开发的开源编程语言,它是JavaScript的一个超集,为JavaScript添加了类型系统和对ES6+的支持。以下是关于TypeScript的详细介绍:一、特点类型系统:TypeScript引入了类型注解,允许开发者为变量、函数参数、返回值等添加类型信息。这有助于在编译阶段发现潜在的类型错误,提高代码的健壮性和可维护性。例如:letmessage:s
- 每日一省第155天·认命修运
历事炼心
什么是命运?命运不是公平的母亲。有人在控诉命运的不公,给别人如此之多给自己如此之少。有人用忧伤博取命运的同情,让命运看到自己的可怜悲惨,祈求命运赐给自己好的未来,控诉和祈求命运只会让我们失去更多,因为女神会让富有者更加富有,因为富有者会看到未来和更多的资源;让智慧者更加智慧,因为智慧者懂得用学习成长疏通智慧的源泉;让勇敢者更加勇敢,因为勇敢者无惧的面对,更容易挑战死神的魔爪。人之道损不足以奉有余,
- 《87期读书会》坚持第646天读书会分享(2016.09.24星期六)
半夏五月天
坚持第646天读书会分享(2016.09.24星期六)《87期读书会》值班中参加读书会,庆幸的是虽然偶尔有电话和借东西,但是没有急诊,可以让我顺利参加读书会。读书收获:(3)请受督者检核与扩大其对咨询专业的信念。3.省思介入策略与后续可能性。(1)检视受督者后续介入的意图,与可能成效为何。(2)请受督者思考后续可有的不同技巧与切入方向之可能性,并接着探问受督者的看法,与当事人可能会有的反应。(3)
- 淘宝返利微信公众号?淘宝返利app哪个最好
氧惠好物
值得推荐返利app有哪些?十大返利最高的平台1、氧惠app(邀请码:666888)氧惠APP是一家综合优惠导购返佣分享型社交电商平台,致力于做全网全品类商品和服务的供给,为用户提供购物、餐饮、休闲娱乐及生活服务等领域的消费优惠,让用户可以一站式享受全网的优惠。手机应用商店搜索“氧惠”即可下载,注册填写邀请码:666888【氧惠】是一个自用省钱佣金高,分享推广赚钱多的平台,2022全新模式,0投资,
- 脑子进水算什么,脑子长虫才吓人呢!
643bce369bfe
01陈女士近期突然出现嘴角不由自主地抽搐,有时在吃饭时抽,有时在说话时抽,有时就是安静呆着也抽。最烦人的是近日右手也开始抽搐了。工作受到影响,她不得不来到医院看病,彦之医生给她开了头颅CT,检查结果显示,她的脑袋里出现许多圆形的小黑影!“你的脑袋里有许多小病灶,很可能是虫子,需要进一步检查明确。”彦之医生对陈女士说。头颅磁共振和血液化验结果证实了彦之医生的推测,陈女士得了脑囊虫病,头脑里面那些小东
- 每个人的愿景
依衣多
在办公室闲聊,同事说起他孩子可以背诵很多的古诗词和英语单词了,我很是羡慕,他孩子比我孩子只大了10个月左右。这让我很是羡慕,也让我有了紧迫感,确实要开始教点东西给宝宝了。每天要计划教点幼儿的知识,让孩子多听多看多学,多花时间陪伴孩子成长是我现在需要做的事情。隔壁村李大爷和大娘的愿景是希望他33岁的儿子早点结婚,家里的小儿子早早的已经结婚生子,二儿子的媳妇很顺利,家教又好,从湖北孝感市嫁到这个山沟沟
- 人生对自由的向往,无非是做真实的自己——卢梭追求浪漫的一生
紫如妍雨
卢梭其名,早已如雷贯耳,学习社会学课程时,其著作《社会契约论》是必读书目,了解到其作为思想运动的启蒙者之一,在政治、哲学、教育等领域都有所建树。他还开创了浪漫主义文学流派,在“人欲横流的功利主义时代”逆流而行。《浪漫之魂:让-雅克·卢梭》一书的作者赵林,哲学博士,长期研究西方哲学及文化,尤其偏爱卢梭这位“沉寂而又激烈的浪漫主义先驱”,仍深刻记得初读卢梭的《忏悔录》时那激动的心情,并自此与这个“心灵
- [心理援助学习营成长记录]+一个充实的假期
九班陈宏玲
2020年的春节是一个特殊的春节,因为新冠肺炎疫情的发生,为此我们度过了一个超长的假期。在这个假期里,有人在玩游戏,有人在吵架,有人在追剧,更多的可能是对疫情的担心与焦虑,而我却度过了一个非常有意义的假期——参加通辽心理援助学习营的管理与学习活动。在疫情发展的初期阶段,通辽心理咨询师协会会长贾文贤老师就迅速带领同事们成立了心理援助公益热线和学习群,为需要的人提供帮助。同时也为了大家能更好更有效的学
- 17.论语~譬如北辰,领导者的最高境界,是不打扰
会飞的鱼topyux
子曰:为政以德,譬如北辰,居其所而众星拱之。这句话直译过来就是,如果你用德行,来这里国家就如北极星养殖,需要在自己本来的位置就够了,重心依然会围绕着你。理解孔子的这句话呢?我们先从老子最为人熟知的一句话说起,治大国若很小,先当小鱼,小虾在锅里的时候不能总去翻动它们,否则就会搅得一团糟之大国也是如此,不能总是折腾。我们举个最简单的例子,就是不要像乾隆那样,总是下江南劳民伤财。一本书叫复杂,这本书讲了
- 坚持不懈以学筑魂,不断筑牢政治忠诚
日落时分217
孔子曰:“学而时习之,不亦说乎”古人在面对学习时的态度也再次印证了学习的重要性,活到老,学到老的坚持是我们每个党员干部需要贯彻的学习思想,只有通过不断地学习,才能武装思想扎实理论基础,跟得上时代的变迁,适应世界格局的变化。自治区党委理论学习中心组会议暨省级领导读书班交流研讨会隆重举行。马兴瑞书记强调:“深入学习贯彻习近平新时代中国特色社会主义思想是新时代新征程下的党员干部的首要政治任务个终身必修课
- 读书笔记之 瑞达利欧《原则》
niuDavid
桥水创始人瑞·达利欧写的《原则》一书,厚厚的竟达五百多页,我也是花费很长时间读完。《原则》主体架构无非分为三个部分,首先是写自己的历程,夹杂一些自己感悟作为本书的引子,第二部分是讲到归纳的生活原则,最后一部分就讲了工作中的原则。书中归纳点很多,虽然有些是我们早已体察到的,但仍有部分观点新鲜可敬,有些理论是深刻的,有些观点是让人触动不已,有些竟是即相通而又交叉验证的,这些都通过此书系统的给我们展显出
- 2023-10-30
佳依我心
“生活中都有面具,既然看透了,那么就请用绝对清醒的理智,去压制不该有的情绪;最好的状态就是不属于任何人,也不拥有任何人,减少期待,好好生活。”我自己本人,不是很喜欢与人过多的交往和接触,只不过到了后来,不得不为之改正和调整自己的方式,只有这样才能适应越来越多的复杂个艰苦,却不会轻易放弃自己所坚持的事。未来有多远,我们并不知道,可是脚下的路却让我们变得更加强大和无畏,只有不停的走下去,才能够变得越来
- 量子计算与AI融合的技术突破与实践路径
量子计算与人工智能的融合正开启一个全新的技术纪元,这种"量智融合"不是简单的技术叠加,而是多领域、多学科的横向连接,通过协同创新实现非线性增长。本文将深入探讨这一领域的最新进展、技术实现路径以及行业应用案例。电子-光子-量子一体化芯片:硬件基础突破2025年7月,美国波士顿大学、加州大学伯克利分校和西北大学团队联合开发出全球首个电子-光子-量子一体化芯片系统。这一突破性成果发表在《自然·电子学》杂
- java解析APK
3213213333332132
javaapklinux解析APK
解析apk有两种方法
1、结合安卓提供apktool工具,用java执行cmd解析命令获取apk信息
2、利用相关jar包里的集成方法解析apk
这里只给出第二种方法,因为第一种方法在linux服务器下会出现不在控制范围之内的结果。
public class ApkUtil
{
/**
* 日志对象
*/
private static Logger
- nginx自定义ip访问N种方法
ronin47
nginx 禁止ip访问
因业务需要,禁止一部分内网访问接口, 由于前端架了F5,直接用deny或allow是不行的,这是因为直接获取的前端F5的地址。
所以开始思考有哪些主案可以实现这样的需求,目前可实施的是三种:
一:把ip段放在redis里,写一段lua
二:利用geo传递变量,写一段
- mysql timestamp类型字段的CURRENT_TIMESTAMP与ON UPDATE CURRENT_TIMESTAMP属性
dcj3sjt126com
mysql
timestamp有两个属性,分别是CURRENT_TIMESTAMP 和ON UPDATE CURRENT_TIMESTAMP两种,使用情况分别如下:
1.
CURRENT_TIMESTAMP
当要向数据库执行insert操作时,如果有个timestamp字段属性设为
CURRENT_TIMESTAMP,则无论这
- struts2+spring+hibernate分页显示
171815164
Hibernate
分页显示一直是web开发中一大烦琐的难题,传统的网页设计只在一个JSP或者ASP页面中书写所有关于数据库操作的代码,那样做分页可能简单一点,但当把网站分层开发后,分页就比较困难了,下面是我做Spring+Hibernate+Struts2项目时设计的分页代码,与大家分享交流。
1、DAO层接口的设计,在MemberDao接口中定义了如下两个方法:
public in
- 构建自己的Wrapper应用
g21121
rap
我们已经了解Wrapper的目录结构,下面可是正式利用Wrapper来包装我们自己的应用,这里假设Wrapper的安装目录为:/usr/local/wrapper。
首先,创建项目应用
&nb
- [简单]工作记录_多线程相关
53873039oycg
多线程
最近遇到多线程的问题,原来使用异步请求多个接口(n*3次请求) 方案一 使用多线程一次返回数据,最开始是使用5个线程,一个线程顺序请求3个接口,超时终止返回 缺点 测试发现必须3个接
- 调试jdk中的源码,查看jdk局部变量
程序员是怎么炼成的
jdk 源码
转自:http://www.douban.com/note/211369821/
学习jdk源码时使用--
学习java最好的办法就是看jdk源代码,面对浩瀚的jdk(光源码就有40M多,比一个大型网站的源码都多)从何入手呢,要是能单步调试跟进到jdk源码里并且能查看其中的局部变量最好了。
可惜的是sun提供的jdk并不能查看运行中的局部变量
- Oracle RAC Failover 详解
aijuans
oracle
Oracle RAC 同时具备HA(High Availiablity) 和LB(LoadBalance). 而其高可用性的基础就是Failover(故障转移). 它指集群中任何一个节点的故障都不会影响用户的使用,连接到故障节点的用户会被自动转移到健康节点,从用户感受而言, 是感觉不到这种切换。
Oracle 10g RAC 的Failover 可以分为3种:
1. Client-Si
- form表单提交数据编码方式及tomcat的接受编码方式
antonyup_2006
JavaScripttomcat浏览器互联网servlet
原帖地址:http://www.iteye.com/topic/266705
form有2中方法把数据提交给服务器,get和post,分别说下吧。
(一)get提交
1.首先说下客户端(浏览器)的form表单用get方法是如何将数据编码后提交给服务器端的吧。
对于get方法来说,都是把数据串联在请求的url后面作为参数,如:http://localhost:
- JS初学者必知的基础
百合不是茶
js函数js入门基础
JavaScript是网页的交互语言,实现网页的各种效果,
JavaScript 是世界上最流行的脚本语言。
JavaScript 是属于 web 的语言,它适用于 PC、笔记本电脑、平板电脑和移动电话。
JavaScript 被设计为向 HTML 页面增加交互性。
许多 HTML 开发者都不是程序员,但是 JavaScript 却拥有非常简单的语法。几乎每个人都有能力将小的
- iBatis的分页分析与详解
bijian1013
javaibatis
分页是操作数据库型系统常遇到的问题。分页实现方法很多,但效率的差异就很大了。iBatis是通过什么方式来实现这个分页的了。查看它的实现部分,发现返回的PaginatedList实际上是个接口,实现这个接口的是PaginatedDataList类的对象,查看PaginatedDataList类发现,每次翻页的时候最
- 精通Oracle10编程SQL(15)使用对象类型
bijian1013
oracle数据库plsql
/*
*使用对象类型
*/
--建立和使用简单对象类型
--对象类型包括对象类型规范和对象类型体两部分。
--建立和使用不包含任何方法的对象类型
CREATE OR REPLACE TYPE person_typ1 as OBJECT(
name varchar2(10),gender varchar2(4),birthdate date
);
drop type p
- 【Linux命令二】文本处理命令awk
bit1129
linux命令
awk是Linux用来进行文本处理的命令,在日常工作中,广泛应用于日志分析。awk是一门解释型编程语言,包含变量,数组,循环控制结构,条件控制结构等。它的语法采用类C语言的语法。
awk命令用来做什么?
1.awk适用于具有一定结构的文本行,对其中的列进行提取信息
2.awk可以把当前正在处理的文本行提交给Linux的其它命令处理,然后把直接结构返回给awk
3.awk实际工
- JAVA(ssh2框架)+Flex实现权限控制方案分析
白糖_
java
目前项目使用的是Struts2+Hibernate+Spring的架构模式,目前已经有一套针对SSH2的权限系统,运行良好。但是项目有了新需求:在目前系统的基础上使用Flex逐步取代JSP,在取代JSP过程中可能存在Flex与JSP并存的情况,所以权限系统需要进行修改。
【SSH2权限系统的实现机制】
权限控制分为页面和后台两块:不同类型用户的帐号分配的访问权限是不同的,用户使
- angular.forEach
boyitech
AngularJSAngularJS APIangular.forEach
angular.forEach 描述: 循环对obj对象的每个元素调用iterator, obj对象可以是一个Object或一个Array. Iterator函数调用方法: iterator(value, key, obj), 其中obj是被迭代对象,key是obj的property key或者是数组的index,value就是相应的值啦. (此函数不能够迭代继承的属性.)
- java-谷歌面试题-给定一个排序数组,如何构造一个二叉排序树
bylijinnan
二叉排序树
import java.util.LinkedList;
public class CreateBSTfromSortedArray {
/**
* 题目:给定一个排序数组,如何构造一个二叉排序树
* 递归
*/
public static void main(String[] args) {
int[] data = { 1, 2, 3, 4,
- action执行2次
Chen.H
JavaScriptjspXHTMLcssWebwork
xwork 写道 <action name="userTypeAction"
class="com.ekangcount.website.system.view.action.UserTypeAction">
<result name="ssss" type="dispatcher">
- [时空与能量]逆转时空需要消耗大量能源
comsci
能源
无论如何,人类始终都想摆脱时间和空间的限制....但是受到质量与能量关系的限制,我们人类在目前和今后很长一段时间内,都无法获得大量廉价的能源来进行时空跨越.....
在进行时空穿梭的实验中,消耗超大规模的能源是必然
- oracle的正则表达式(regular expression)详细介绍
daizj
oracle正则表达式
正则表达式是很多编程语言中都有的。可惜oracle8i、oracle9i中一直迟迟不肯加入,好在oracle10g中终于增加了期盼已久的正则表达式功能。你可以在oracle10g中使用正则表达式肆意地匹配你想匹配的任何字符串了。
正则表达式中常用到的元数据(metacharacter)如下:
^ 匹配字符串的开头位置。
$ 匹配支付传的结尾位置。
*
- 报表工具与报表性能的关系
datamachine
报表工具birt报表性能润乾报表
在选择报表工具时,性能一直是用户关心的指标,但是,报表工具的性能和整个报表系统的性能有多大关系呢?
要回答这个问题,首先要分析一下报表的处理过程包含哪些环节,哪些环节容易出现性能瓶颈,如何优化这些环节。
一、报表处理的一般过程分析
1、用户选择报表输入参数后,报表引擎会根据报表模板和输入参数来解析报表,并将数据计算和读取请求以SQL的方式发送给数据库。
2、
- 初一上学期难记忆单词背诵第一课
dcj3sjt126com
wordenglish
what 什么
your 你
name 名字
my 我的
am 是
one 一
two 二
three 三
four 四
five 五
class 班级,课
six 六
seven 七
eight 八
nince 九
ten 十
zero 零
how 怎样
old 老的
eleven 十一
twelve 十二
thirteen
- 我学过和准备学的各种技术
dcj3sjt126com
技术
语言VB https://msdn.microsoft.com/zh-cn/library/2x7h1hfk.aspxJava http://docs.oracle.com/javase/8/C# https://msdn.microsoft.com/library/vstudioPHP http://php.net/manual/en/Html
- struts2中token防止重复提交表单
蕃薯耀
重复提交表单struts2中token
struts2中token防止重复提交表单
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年7月12日 11:52:32 星期日
ht
- 线性查找二维数组
hao3100590
二维数组
1.算法描述
有序(行有序,列有序,且每行从左至右递增,列从上至下递增)二维数组查找,要求复杂度O(n)
2.使用到的相关知识:
结构体定义和使用,二维数组传递(http://blog.csdn.net/yzhhmhm/article/details/2045816)
3.使用数组名传递
这个的不便之处很明显,一旦确定就是不能设置列值
//使
- spring security 3中推荐使用BCrypt算法加密密码
jackyrong
Spring Security
spring security 3中推荐使用BCrypt算法加密密码了,以前使用的是md5,
Md5PasswordEncoder 和 ShaPasswordEncoder,现在不推荐了,推荐用bcrpt
Bcrpt中的salt可以是随机的,比如:
int i = 0;
while (i < 10) {
String password = "1234
- 学习编程并不难,做到以下几点即可!
lampcy
javahtml编程语言
不论你是想自己设计游戏,还是开发iPhone或安卓手机上的应用,还是仅仅为了娱乐,学习编程语言都是一条必经之路。编程语言种类繁多,用途各 异,然而一旦掌握其中之一,其他的也就迎刃而解。作为初学者,你可能要先从Java或HTML开始学,一旦掌握了一门编程语言,你就发挥无穷的想象,开发 各种神奇的软件啦。
1、确定目标
学习编程语言既充满乐趣,又充满挑战。有些花费多年时间学习一门编程语言的大学生到
- 架构师之mysql----------------用group+inner join,left join ,right join 查重复数据(替代in)
nannan408
right join
1.前言。
如题。
2.代码
(1)单表查重复数据,根据a分组
SELECT m.a,m.b, INNER JOIN (select a,b,COUNT(*) AS rank FROM test.`A` A GROUP BY a HAVING rank>1 )k ON m.a=k.a
(2)多表查询 ,
使用改为le
- jQuery选择器小结 VS 节点查找(附css的一些东西)
Everyday都不同
jquerycssname选择器追加元素查找节点
最近做前端页面,频繁用到一些jQuery的选择器,所以特意来总结一下:
测试页面:
<html>
<head>
<script src="jquery-1.7.2.min.js"></script>
<script>
/*$(function() {
$(documen
- 关于EXT
tntxia
ext
ExtJS是一个很不错的Ajax框架,可以用来开发带有华丽外观的富客户端应用,使得我们的b/s应用更加具有活力及生命力。ExtJS是一个用 javascript编写,与后台技术无关的前端ajax框架。因此,可以把ExtJS用在.Net、Java、Php等各种开发语言开发的应用中。
ExtJs最开始基于YUI技术,由开发人员Jack
- 一个MIT计算机博士对数学的思考
xjnine
Math
在过去的一年中,我一直在数学的海洋中游荡,research进展不多,对于数学世界的阅历算是有了一些长进。为什么要深入数学的世界?作为计算机的学生,我没有任何企图要成为一个数学家。我学习数学的目的,是要想爬上巨人的肩膀,希望站在更高的高度,能把我自己研究的东西看得更深广一些。说起来,我在刚来这个学校的时候,并没有预料到我将会有一个深入数学的旅程。我的导师最初希望我去做的题目,是对appe