Hadoop 2.7.1 集群搭建 基于CentOS 6.2
Hadoop 2.7.1 集群搭建 基于CentOS 6.2
之前写了一个Hadoo 2.7.1集群的搭建http://blog.csdn.net/dongbeiman/article/details/51752276,当时的操作系统是ubuntu,这篇blog系统换成了CenotOS
- 一. 环境和相关软件
台式机一个,启动两个CentOS6.2的虚拟机
虚拟机:VMware Workstation 12 Pro
操作系统版本:CentOS x64
两个系统 master 10.11.12.3 用户root
slave 10.11.12.4 用户root
hadoop:hadoop-2.7.1.tar.gz
JDK:java version "1.7.0_79-b15" 64-Bit

- 二. CentOS准备工作
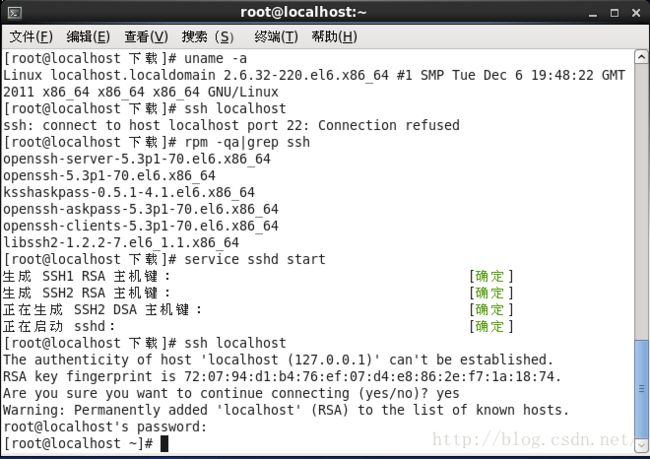
- 1. 开启ssh登陆
- 2. 检查是否安装ssh server rpm -qa | grep ssh
- 3. 若没有安装则执行安装命令
yum install openssh-server
- 4. 启动SSH服务。
输入命令:service sshd restart 重启SSH服务。
命令:service sshd start 启动服务
命令:service sshd stop 停止服务
命令:chkconfig sshd on开机自启动
重启后可输入:netstat -antp | grep sshd 查看是否启动22端口(可略)
- 5. 关闭防火墙和SELinux方便调试
1. 临时生效,重启后复原
开启: service iptables start
关闭: service iptables stop
查看: service iptables status
2. 永久性生效,重启后不会复原
开启: chkconfig iptables on
关闭: chkconfig iptables off
3. 关闭SELinux (为了调试方便暂时关闭)
查看selinux的模式
# getenforce
彻底关闭SELinux
用vim打开 /etc/selinux/config
在 SELINUX=enforcing 前面加个#号注释掉它
#SELINUX=enforcing
然后新加一行
SELINUX=disabled
保存,退出,重启系统,搞定。

- 三. 安装 JDK 1.7
- 1. 下载JDK 1.7
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
- 2. 上传jdk-7u79-linux-x64.tar.gz 到CentOS中/root 下
scp jdk-7u79-linux-x64.tar.gz [email protected]:/root
- 3. cd /root
- 4. 解压
tar -zvxf jdk-7u79-linux-x64.tar.gz
- 5. 移动目录
mv jdk1.7.0_79/ /opt
- 6. 修改 /etc/profile
vi /etc/profile
在最尾添加:
export JAVA_HOME=/opt/jdk1.7.0_79
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- 7. source /etc/profile 使配置生效
- 8. java –version 查看JDK是否配置好

- 四. 解压 hadoop-2.7.1.tar.gz 并配置环境变量
- 1. 上传到CentOS /root 下
scp hadoop-2.7.1.tar.gz [email protected]:/root
- 2. 解压tar -zvxf hadoop-2.7.1.tar.gz
- 3. 移动目录:mv hadoop-2.7.1 /opt
- 4. 修改 /etc/profile
vi /etc/profile
export HADOOP_PREFIX=/opt/hadoop-2.7.1
export PATH=$HADOOP_PREFIX/bin:$PATH
- 5. source /etc/profile 使配置文件生效
- 6. 验证:hadoop version

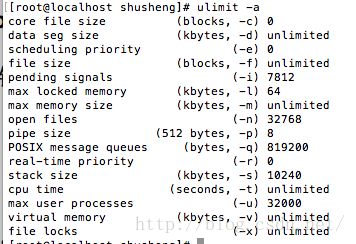
- 五. 修改 ulimit open file 和 nproc
- 1. 在文件 /etc/security/limits.conf 添加三行,如:
root - nofile 32768
root soft nproc 32000
root hard nproc 32000
说明 root 为当前用户
还有注销再登录,这些配置才能生效!
- 六. 复制虚拟机
1. 关闭虚拟机系统,复制虚拟机文件。
目的弄出两个虚拟机1个是master另1个为slave
- 七. 修改 hostname 和 /etc/hosts
- 1.修改/etc/sysconfig/network
vi /etc/sysconfig/network
HOSTNAME改为 master 或 slave
- 2. 分别修改master和slave
主机master的hostname为master
分机slave的hostname为slave
master:

slave

修改完成后用命令hostname查看
- 3. 分别修改/etc/hosts
添加
10.11.12.3 master
10.11.12.4 slave
修改前
![]()
修改后


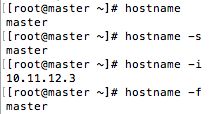
- 4. 重启系统后登录后查看hostname
重启系统命令:shutdown -r now
命令:hostname 查看hostname 可以加参数
master
slave

- 5. 验证:用ping master 和 ping slave

- 八. 设置 ssh 免密码登陆
- 1. 两个机器都要做 ssh localhost 免登陆
执行下面两个命令后:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
用ssh localhost 登陆,应该就不需要输入密码了。
- 2. 两个机器 master和slave 都需要互相ssh登陆免密码
- a. master 免密码登陆 slave
- 1. 登陆master,把master生成的 ~/.ssh/id_dsa.pub 复制到slave下, 用scp命令
scp ~/.ssh/id_dsa.pub root@slave:/root
- 2. 登陆slave 把 id_dsa.pub 放倒 authorized_keys 中
cat ~/id_dsa.pub >> ~/.ssh/authorized_keys
- 3. 在 slave 中检查 ~/.ssh/authorized_keys 中内容,执行命令
more ~/.ssh/authorized_keys
- 4. 在master系统中,登陆slave 看看是能ssh免密码登陆,执行命令
ssh slave
- b. slave 免密码登陆 master
- 1. 登陆slave,把slave生成的 ~/.ssh/id_dsa.pub 复制到master下, 用scp命令
scp ~/.ssh/id_dsa.pub root@master:/root
- 2. 登陆master 把 id_dsa.pub 放倒 authorized_keys 中
cat ~/id_dsa.pub >> ~/.ssh/authorized_keys
- 3. 在 master 中检查 ~/.ssh/authorized_keys 中内容,执行命令
more ~/.ssh/authorized_keys
- 4. 在slave系统中,登陆master 看看是能ssh免密码登陆,执行命令
ssh master
- 九. 修改master和slave的hadoop配置文件
master和slave的hadoop配置文件都是这么修改。
- 1. 先把配置文件目录备份,然后再修改
cd /opt/hadoop-2.7.1/etc
cp -R hadoop/ hadoop#bak
- 2. 修改配置文件etc/hadoop/core-site.xml
在
在/opt下创建fengwork目录
mkdir /opt/fengwork
- 3. 修改配置文件etc/hadoop/hdfs-site.xml
在
- 4. 修改配置文件etc/hadoop/yarn-site.xml
在
- 5. 修改配置文件etc/hadoop/mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
修改mapred-site.xml在
- 6. 修改配置文件etc/hadoop/slaves
添加:
master
slave
- 7. 修改配置文件etc/hadoop/hadoop-env.sh
在export JAVA_HOME=${JAVA_HOME}上面添加:
JAVA_HOME=/opt/jdk1.7.0_79
如:
JAVA_HOME=/opt/jdk1.7.0_79
export JAVA_HOME=${JAVA_HOME}
至此,Hadoop集群配置基本完成了。
- 十. hadoop命令
命令:第一次启动前,需先格式化一次。
$HADOOP_PREFIX/bin/hdfs namenode -format
如:
hdfs namenode -format hadoop_fengwork
或
/opt/hadoop-2.7.1/bin/hdfs namenode -format hadoop_fengwork
启动全部:
$HADOOP_PREFIX/sbin/start-all.sh
关闭全部:
$HADOOP_PREFIX/sbin/stop-all.sh
#解除hadoop的安全模式
$HADOOP_PREFIX/bin/hadoop dfsadmin -safemode leave
#进入hadoop的安全模式
$HADOOP_PREFIX/bin/hadoop dfsadmin -savemode enter
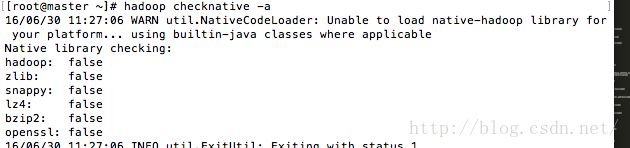
验证hadoop安装环境的命令
$HADOOP_PREFIX/bin/hadoop checknative -a
在master 执行 sbin/start-all.sh后则完成集群的启动
在master中:

在slave中:
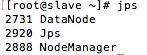
访问:http://master:50070
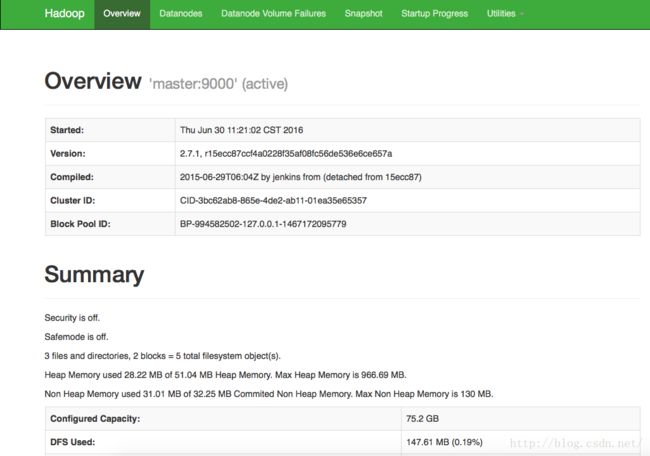

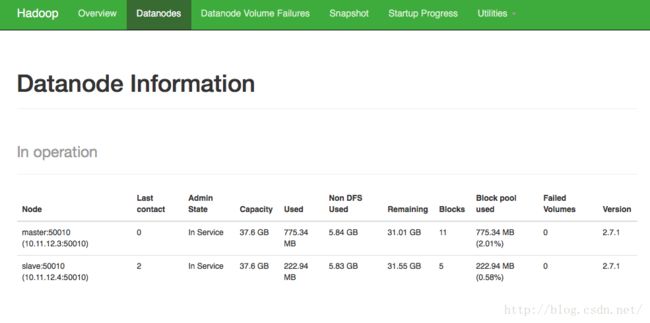
- 十一. 基本操作命令
创建目录
$HADOOP_PREFIX/bin/hadoop fs -mkdir /usr
上传文件:
$HADOOP_PREFIX/bin/hadoop fs -put ~/hadoop-2.7.1.tar.gz /usr/feng/
下载文件:
$HADOOP_PREFIX/bin/hadoop fs -get /usr/feng/jdk-8u25-linux-x64.tar.gz ~/Downloads/
可以验证文件的是否被窜改了:
feng@master:~$ md5sum ~/Downloads/jdk-8u25-linux-x64.tar.gz
e145c03a7edc845215092786bcfba77e /home/feng/Downloads/jdk-8u25-linux-x64.tar.gz
feng@master:~$ md5sum ~/jdk-8u25-linux-x64.tar.gz
e145c03a7edc845215092786bcfba77e /home/feng/jdk-8u25-linux-x64.tar.gz
查看md5结果是一个,所以文件是没有问题的。
***********
展示文件列表:
$HADOOP_PREFIX/bin/hadoop fs -ls /
递归展示文件列表:
$HADOOP_PREFIX/bin/hadoop fs -ls -R /
展示文件内容:
$HADOOP_PREFIX/bin/hadoop fs -tail /feng/tmp/1462950193038
展示全部文件内容:注意查看测试的小文件可以,太大文件最好不用
$HADOOP_PREFIX/bin/hadoop fs -cat /feng/tmp/1462950193038
更多命令查看官网:
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html