OpenStack原理框架及在大型公有云可用性分析
一、组件框架
OpenStack项目是一个开源的云计算平台,旨在实现很简单,大规模可伸缩,功能丰富。来自世界各地云计算开发人员和技术人员共同创建OpenStack项目。OpenStack通过一组相关的服务提供一个基础设施即服务(IaaS)解决方案。每个服务提供了一个应用程序编程接口(API),促进了这种集成。根据您的需要,你可以安装部分或全部服务。下表描述了构成OpenStack架构的OpenStack服务:
| Service | Code Name | Description |
| Identity Service | Keystone | User Management |
| Compute Service | Nova | Virtual Machine Management |
| Image Service | Glance | Manages Virtual image like kernel image or disk image |
| Dashboard | Horizon | Provides GUI console via Web browser |
| Object Storage | Swift | Provides Cloud Storage |
| Block Storage | Cinder | Storage Management for Virtual Machine |
| Network Service | Neutron | Virtual Networking Management |
| Orchestration Service | Heat | Provides Orchestration function for Virtual Machine |
| Metering Service | Ceilometer | Provides the function of Usage measurement for accounting |
| Database Service | Trove | Database resource Management |
| Data Processing Service | Sahara | Provides Data Processing function |
| Bare Metal Provisioning | Ironic | Provides Bare Metal Provisioning function |
| Messaging Service | Zaqar | Provides Messaging Service function |
| Shared File System | Manila | Provides File Sharing Service |
| DNS Service | Designate | Provides DNS Server Service |
| Key Manager Service | Barbican | Provides Key Management Service |
下面的图显示了OpenStack服务之间的关系: 
为了设计、部署和配置OpenStack,管理员必须理解明白OpenStack的逻辑架构。正如OpenStack概念架构图显示,OpenStack包含一些独立的部分,称作OpenStack服务。所有服务授权认证都是通过Identity服务。单个服务通过公共APIs与其他服务进行交互,特权管理员用户命令除外。在内部,OpenStack服务是由几个进程组成。所有服务至少有一个API进程,用来监听API请求,预处理它们并传递它们到其他服务。除了Identity服务外,其他服务实际工作是由不同的进程完成。对于一个服务之间的进程通信,使用AMQP消息块。这些服务状态存储在一个数据库中。当部署和配置你的OpenStack云,你可以选择不同的消息队列服务和数据库服务,如RabbitMQ、MySQL、MariaDB和SQLite。下面的图显示了大多数通用的OpenStack云: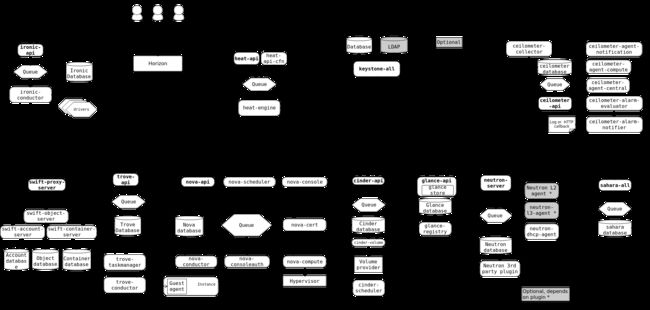
二、在大型公有云可用性分析
1、
项目内通信机制:
项目内通信一般使用RPC.call、RPC.cast进行通信:
RPC.call请求
对于RPC.call请求,借助官方一张经典的图来描述:
以nova-compute服务调用nova-network服务分配网络为例:
1. nova-compute服务向消息队列服务的compute.node队列发送RPC请求,并等待请求的最终回复。
2. nova-network服务通过nova exchange(topic exchange)从compute.node队列中获取消息并作出相应的处理。
3. nova-network服务消息处理完了之后,向reply_XXX队列发送一条回复消息
4. nova-compute服务通过reply_XXX exchange(direct exchange)接受从nova-network发送的RPC消息。
RPC.cast请求
对于RPC.cast请求,同样借助官方一张经典的图来描述:
以nova-conductor服务调用nova-compute服务build_and_run_instance为例:
1. nova-conductor服务向消息队列服务的compute队列发送RPC请求,请求结束,不需要等待请求的最终回复。
2. nova-compute服务通过nova exchange(topic exchange)从compute队列中获取消息并作出相应的处理。
在openstack项目中,一般情况下,RPC server端发送一个请求到消息队列,一般只有一个消费者(及时有多个消费者)接受并处理这条消息,还有一种类型的RPC.cast请求,也称为fanout_cast请求,fanout_cast发送的是广播请求,所有对应的consumer都能接收到。
调度器(Nova-schduler)策略
1、获取全量资源视图
2、使用多级filter进行筛选,剔除不需要的宿主机
3、对宿主机进行权重计算,涉及多个纬度
4、按照权重对宿主机进行排序
5、按照优先级高低依次尝试资源扣减,提交修改事务,直到成功。
这里引用官方的经典图来展示筛选过程。
可用性分析:
大规模公有云需求:
结合现在的工作经验总结大规模公有云的需求如下:
1、宿主机规模较大,单个区域数W台,即全局资源视图较大。并且渴望全局最有的调度策略。
2、云计算需求爆发式增长,潮汐式海量并发购买,每小时 数万台 VM 购买请求,峰值每分钟上千台VM 购买请求。
3、用户期望尽可能快的交付。
openstack用于公有云的问题:
先看一组业界openstack较大规模的性能测试数据:
https://www.cnblogs.com/allcloud/p/5567083.html
文中提到,宿主机规模为400,虚拟机创建时间最长10分钟,并发请求最高可以为500。更大规模的测试系统已经变得极不稳定,甚至不可用。
参照业界其他测试,这也确实接近openstack极限性能了
参照前面的架构介绍,分析:
1、项目内通信依赖基于mq带有返回的rpc调用,会在每个会话中建立临时的返回队列。在高并发场景下,会维护大量临时会话队列、连接,对系统造成较大的压力,成为瓶颈。
2、全局资源视图的获取为全量,并且大规模公有云较上面的测试规模增长两个数量级,所以调度性能成为极大挑战。
总和上面两点,可以看出openstack用于大规模公有云,还需要解决需要问题的挑战才行。