linux文件系统及磁盘格式化
千万注意:分区格式化磁盘前确保你磁盘的数据备份好了,要不可能就没了。
1、傻瓜式磁盘分区,最直接的方式(先fdisk后parted)。不用了解文件系统的原理。此处将对两种分区机制磁盘进行分区格式化(MBR类型磁盘——用fdisk###GPT类型磁盘——用parted)。fdisk不支持大于2T的分区寻址(后边再详细介绍原理,这里为保持简单不涉及)。
1> fdisk -l #查看当前系统上所有存储设备(包括挂在和没挂载的) 注:如果没有管理员权限是看不见磁盘的,因为fdisk默认读的/proc/partitions文件。无权限无法读取
Disk /dev/vda: 214.7 GB, 214748364800 bytes #磁盘一共214.7G
255 heads, 63 sectors/track, 26108 cylinders #共255个磁头,每个磁道63个扇区,共26108个柱面。
Units = cylinders of 16065 * 512 = 8225280 bytes #每个柱面8225280个字节。计算公式:255*63*512=8225280 (每个柱面255个磁道,每个磁道63个扇区。所以扇区总数16065/柱面。所以每个柱面也就8M多。这个是后边分区划分的单元)
Sector size (logical/physical): 512 bytes / 512 bytes #逻辑扇区和物理扇区都是512个自字节
I/O size (minimum/optimal): 512 bytes / 512 bytes #此参数不知道设么意思,知道的大神补充
Disk identifier: 0x00078f9c #这里是磁盘id
Device Boot Start End Blocks Id System
/dev/vda1 * 1 26109 209713152 83 Linux #该磁盘上有分区vda1,*号表示内核在此分区上,Start=1代表次分区大小是从1柱面开始的 End=26109表示次分区到26109柱面结束。Block=209713156表示次分区共209713156个块大小(每块1k默认大小,所以你可以看出总共多少空间),Id=83代表此分区文件系统编号是83即Linux(分区类型可以在分区的时候指定,这样可以使我们在用工具进行格式化分区的时候优化文件系统。)
附加:cat /proc/partitions 查看操作系统识别的磁盘和分区,包括挂在和没挂载的。fdisk -l命令读取的也是这个文件,只不过显示内容更详细。
2>知道了自己系统上磁盘的情况后就可以开始着手分区了。
直接上例子:fdisk使用语法如下
fdisk /dev/硬盘名字 //分区sda硬盘
p //打印已有分区
如果输入错误,按着ctrl + delete才能删除
n //创建新分区
e // 选择的是扩展分区 p //指的是主分区(注意分配的柱面是否全用完,避免浪费,磁盘上只能由最多3主分区和1扩展分区,或者最多4个主分区),之后你就可以在扩展分区上创建逻辑分区了(逻辑分区个数一般没什么限制几百个都没问题)
w //保存退出,这样你的分区信息即可生效,如果不保存则不生效(相当于取消操作什么都没做)
m //帮助信息
fdisk /dev/sdb =>键入m获取帮助信息。=>键入n创建新分区(e扩展分区,p主分区,l逻辑分区--主分区扩展分区逻辑分区分不清的请自行google,注意主分区和扩展分区个数和不能大于4。这是MBR分区机制的限制。)=>指定大小(用多少柱面或者多少 K、M、G)=>p查看下分区结果=>w保存分区结果
如果分区有问题:fdisk /dev/sdb=>键入p查看之前的分区=>键入d删除分区
如果还有没有用完的分区:fdisk /dev/sdb=>按照之前的步骤进行分区即可。但是注意主分区和扩展分区的数量必须<=4,如果要的分区多余4个的话请使用逻辑分区。
如果分区类型有问题:fdisk /dev/sdb =>p打印下当前分区,查看各个分区的分区类型=>键入t修改分区类型(键入L可列举分区类型)=>键入分区类型16进制id即可改变分区类型
如果分完区后新分区没有显示:则有可能是操作系统还没有识别新分区。之行下边两个命令即可
cat /proc/partitions //查看当前系统上内核已经识别的分区,分区完后内核可能没有识别的,需要重新读取分区信息。没有你之前分的分区的话之行下边命令重新读取磁盘的分区信息
partprobe /dev/sda //重新读取磁盘。/dev/sda磁盘的分区信息
附加知识点:cat /proc/filesystems //查看当前操作系统支持那些文件系统。了解即可,多说一句对于NTFS文件系统(windows下的文件系统类型)linux默认是不支持的,如果要支持的话可以安装第三方的工具--在这部分为了简化操作不涉及ntfs文件系统在linux下的使用,后边会详细介绍。
3>磁盘分区完毕后就可以考虑进行格式化了
工具及使用语法
mkfs语法:mkfs -t 文件系统类型 分区名字
例: mkfs -t ext3 /dev/sdb1 ## 文件系统的类型常用的值ext2、ext3、ext4
mke2fs语法:mke2fs [option] 分区名字
例:mke2fs -j /dev/sda5 ##将sda5格式化成ext3文件系统-j格式化成ext3文件系统
option选项主要有:
-j:创建ext3类型文件系统
-b:指定块大小,默认4096:可用取值1024、2048、4096
-L:指定卷标
-m:指定预留给超级用户的百分比
-i:用于指定多少字节空间创建一个inode,默认8192,这里给出的数值应该为块大小的2^n倍
-N:指定inode数,用的不多
-F:强制创建文件系统
-E:用户指定额外文件系统属性
附加信息命令输出详解及其他有用说明:此处只是加深对文件系统的进一步认识。不是必须查看的
mkfs -t ext3 /dev/sdb1
mke2fs 1.41.12 (17-May-2010)
Filesystem label= #当前分区的盘符
OS type: Linux #操作系统类型
Block size=4096 (log=2) #组成文件系统的最小单元,块大小
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
251472 inodes, 1004054 blocks #当前文件系统(这个分区)共有251472inode(inode是用于存储文件的元数据信息,后边详细说明),共有1004054个数据块
50202 blocks (5.00%) reserved for the super user #为root用户保留50202个数据块,保障root用户能对当前磁盘进行操作。默认是总容量的5%,此数值可调且很有必要调。
First data block=0
Maximum filesystem blocks=1031798784
31 block groups #块组个数共31个(这个是文件系统的结构信息,后边会有详细介绍)
32768 blocks per group, 32768 fragments per group #每个块组有32768个数据块
8112 inodes per group #每个块组有8112个innode,后边会有文件系统的结构详细解释,看完就明白了
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736 #超级块被存贮在那些块上(超级块会按照一定的算法存储在不同的块组的块中,主要用来保证文件系统的安全,存储分区的很多信息,后边会详细介绍。着急的话自行google)
Writing inode tables: done #向文件系统里边写inode
Creating journal (16384 blocks): done #ext3是日志型操作系统,对文件错误的查找速度更快。此处创建日志
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 33 mounts or #此文件系统将会在33次后或者180天后被自动检查,一般应该加以控制,防止在一些关键业务上由于文件系统的检查使得性能下降甚至出现问题
180 days, whichever comes first. Use tune2fs -c or -i to override. #可以使用tune2fs来覆盖默认检查机制
2、格式化分区时可以进行必要的定制,使文件系统更加合理。
mke2fs语法:mke2fs [option] 分区名字
例:mke2fs -j /dev/sda5 ##将sda5格式化成ext3文件系统-j格式化成ext3文件系统
option选项主要有:
-j:创建ext3类型文件系统
-b:指定块大小,默认4096:可用取值1024、2048、4096
-L:指定卷标
-m:指定预留给超级用户的百分比
-i:用于指定多少字节空间创建一个inode,默认8192,这里给出的数值应该为块大小的2^n倍
-N:指定inode数,用的不多
-F:强制创建文件系统
-E:用户指定额外文件系统属性
实例:mke2fs -b 2048 /dev/sda5 //指定块大小,默认4096。如果文件系统中存储小文件(几k的文件或者多少字节的文件)比较多,调小块大小可以减少块的浪费。
mke2fs -L MYDATA /dev/sda5 //指定卷标,到时候可用卷标来操作这个分区。如果使用分区名可能下次开机分区名会乱掉。所以用卷标比较稳定
mke2fs -m 3 /dev/sda5 //改变为超级用户预留的磁盘空间。(避免浪费太多起始1个G就够用了)
mke2fs -i 4096 /dev/sda5 //指定每4k创建一个inode。inode增多意味着可以存储更多的小文件。因为如果按照默认的8k创建一个inode。当存储过多的小文件时可能会将inode用完。一般来说不用改了8k也不差。
3、此步不是必须的,可直接跳到下部分挂载文件系统。这一步主要对格式化好的文件系统进行一定的调整和设置方便后续操作。
/dev/sdb1: UUID="1dbf4d39-a179-4559-9c60-2f38c782a532" SEC_TYPE="ext2" TYPE="ext3"
e2label /dev/sdb1 MY_DATE1 #设置分区盘符
[root@Centos-01 Desktop]# e2label /dev/sdb1 #查看分区盘符,当然blkid也能看见。盘符也经常用来进行自动挂载。
MY_DATE1
tune2fs 命令语法:tune2fs [option] 文件系统名字(分区) 这个命令可以在文件系统挂载这的时候使用,没什么影响。
[option]主要有:
-j:不损坏原有数据,将ext2升级为ext3
例:tune2fs -j /dev/sda5 //调整分区sda5的文件系统类型为ext3,无损修改,里边有文件也没有问题。
-L:设定或修改卷标
例:tune2fs -L MY_DATA1 /dev/sdb1 //修改卷标
-m:调整预留百分比
例:tune2fs -m 3 /dev/sdb1 //修改为管理员预留的空间大小,默认5%
-r:指定预留块数
例: tune2fs -r30122 /dev/sdb1
-o:设定默认挂载选项
acl ,一般在/etc/fstab里边指定。
例 tune2fs -o acl /dev/sdb1 //使用acl控制列表。开启这个功能才可以对文件的权限设置使用facl功能。
使用acl的功能实例:
setfacl语法:setfacl [option] USER_ATTR
[option]:
-m:设定
u:UID:perm
g:GID:perm
-x:取消权限
u:UID
g:GID
getfacl语法:getfacl filename
例:getfacl ./test.sh //查看文件权限信息
setfacl -m u:hadoop:rw ./test.sh //设置额外用户hadoop对此文件有读写权限,查看命令使用getfacl filename
setfacl -m g:hadoop:rw ./test.sh //设置二外组hadoop组对此文件有读写权限,查看命令使用getfacl filename
setfacl -x u:hadoop ./test.sh //取消hadoop用户对此文件的权限,查看命令使用getfacl filename
setfacl -x g:hadoop ./test.sh //取消hadoop组对此文件的权限,查看命令使用getfacl filename
-c:指定挂载次数到达多少之后进行自检,0或-1表示关闭此功能。与下边的-i一块用的情况多点
例:tune2fs -c -1 /dev/sdb1
-i:每挂载使用多少天后进行自检,0或者-1表示关闭此功能
例: tune2fs -i -1 /dev/sdb1
-l:显示超级快信息
例:tune2fs -l /dev/sdb1 //详细信息可参考,看出此文件系统超级块中的信息。可用于查看上述设置是否生效。看来挺好用。
tune2fs -l /dev/sdb1
tune2fs 1.41.12 (17-May-2010)
Filesystem volume name: MY_DATA1
Last mounted on:
Filesystem UUID: 1dbf4d39-a179-4559-9c60-2f38c782a532
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery sparse_super large_file
Filesystem flags: signed_directory_hash
Default mount options: acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 251472
Block count: 1004054
Reserved block count: 30123
Free blocks: 969892
Free inodes: 251461
First block: 0
Block size: 4096
Fragment size: 4096
Reserved GDT blocks: 245
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8112
Inode blocks per group: 507
Filesystem created: Mon Feb 13 13:52:52 2017
Last mount time: Mon Feb 13 15:34:47 2017
Last write time: Mon Feb 13 16:01:45 2017
Mount count: 1
Maximum mount count: -1
Last checked: Mon Feb 13 13:52:52 2017
Check interval: 4294880896 (1656 months, 4 weeks, 1 day, 6:28:16)
Next check after: Sun Feb 12 13:52:52 2017
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 7d15a978-21af-4819-a32a-0c839055a9ca
Journal backup: inode blocks
附加命令:
dumpe2fs /dev/sda5 //显示超级快信息 , dumpe2fs -h /dev/sda5 //只显示超级快信息
检查并修复文件系统的命令:fsck(用于检查并修复linux文件系统)和e2fsck(专门用于修复ext类型的文件系统)。注意检查前请备份好数据并卸载文件系统
fsck -t ext3 /dev/sdb1 //检查文件系统
fsck -p /dev/sdb1 //修复文件系统
e2fsck /dev/sda5 //检查分区
e2fsck -f -p /dev/sda5 //强制检查,如果有错误自动修复。
4、文件系统的挂载卸载 ,前面把文件系统格式化好后接下来就可以考虑挂载文件系统了。这里介绍mount使用。
1>挂载
mount 设备 挂载点
例:mount /dev/sdb1 /mnt
设备:设备文件(/dev/sdb1),测试的时候用下 ;卷标(LABEL“”“);UUID(UUID="")
挂载点:目录 。 要求:此目录不能被其他进程使用;目录必须存在;目录中原有文件会被临时隐藏
mount //不跟任何参数,显示当前挂载的文件系统和挂载点。比较乱不如df -l清楚
mount [option] [-o option] DEVICE MOUNT_POINT
[option]
-a:表示只挂载/etc/fstab中的文件系统
-n:默认情况mount每挂载一个文件系统就会将挂载得设备信息保存到/etc/mtab文件中
-t: FS_TYPE:指定正在挂载设备上的文件系统类型,不适用此选项时mount会调用blkid命令获取对应文件系统类型。一般挂载ntfs文件系统是时会使用此选项。
-r:只读挂载文件系统
-w:“读写”挂载文件系统
-o :指定挂载的额外选项
remount:重新挂载当前文件系统
ro:只读挂载
rw:读写挂
例:
mount -r /dev/sda5 /media/ //只读挂载
mount -o ro /dev/sda5 /media/ //只读挂载
mount -o remount,ro /dev/sda5 //重新挂载并启用新的功能。多个功能用逗号隔开
mount -o loop /root/*.iso /media //挂载iso文件,就可以直接访问里边的文件了,loop将一个文件当成分区挂载。
2>卸载
umount 设备/挂载点 //注意卸载文件系统的时候,此文件系统没有进程在使用。
例:umount /dev/sdb1
如果文件系统卸载不了,显示“busy”:
fuser -v /mnt/目录名 //查看谁或者那个进程正在访问这个文件系统(分区)
fuser -km /mnt/目录名 //将使用文件系统的用户或进程,踢出去或kill掉。之后再次umount即可
5、额外
1>对于swap(交换分区的格式化):
mkswap /dev/sdb2 //创建交换分区。尽量不要使用交换分区,太慢了。
-L LABEL
swapon /dev/sdb2 //打开交换分区/dev/sdb2的使用
swapoff /dev/sdb2 //关闭交换分区/dev/sdb2的使用
2>查看交换分区是否生效
free -m
total used free shared buffers cached
Mem: 1862 579 1283 0 32 204 #总共2G不到,使用了579M,空余1283M ,共享存储0M,缓冲32M,缓存204M
-/+ buffers/cache: 342 1520 #+-缓冲和缓存后的使用量342M,空闲1520M
Swap: 3999 0 3999 #交换分区4G,空余4G
6、parted命令进行分区格式化。直接引用别人的好了
操作实例:
(parted)表示在parted中输入的命令,其他为自动打印的信息
[[email protected] ~]# parted /dev/hdd
GNU Parted 1.8.1
Using /dev/hdd
Welcome to GNU Parted! Type 'help' to view a list of commands.
2、选择了/dev/hdd作为我们操作的磁盘,接下来需要创建一个分区表(在parted中可以使用help命令打印帮助信息):
(parted) mklabel
Warning: The existing disk label on /dev/hdd will be destroyed and all data on this disk will be lost. Do you want to continue?
Yes/No?(警告用户磁盘上的数据将会被销毁,询问是否继续,我们这里是新的磁盘,输入yes后回车) yes
New disk label type? [msdos]? (默认为msdos形式的分区,我们要正确分区大于2TB的磁盘,应该使用gpt方式的分区表,输入gpt后回车)gpt
3、创建好分区表以后,接下来就可以进行分区操作了,执行mkpart命令,分别输入分区名称,文件系统和分区 的起止位置
(parted) mkpart
Partition name? []? dp1
File system type? [ext2]? ext3
Start? 0
End? 500GB
4、分好区后可以使用print命令打印分区信息,下面是一个print的样例
(parted) print
Model: VBOX HARDDISK (ide)
Disk /dev/hdd: 2199GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name Flags
1 17.4kB 500GB 500GB dp1
5、如果分区错了,可以使用rm命令删除分区,比如我们要删除上面的分区,然后打印删除后的结果
(parted)rm 1 #rm后面使用分区的号码
(parted) print
Model: VBOX HARDDISK (ide)
Disk /dev/hdd: 2199GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name Flags
6、按照上面的方法把整个硬盘都分好区,下面是一个分完后的样例
(parted) mkpart
Partition name? []? dp1
File system type? [ext2]? ext3
Start? 0
End? 500GB
(parted) mkpart
Partition name? []? dp2
File system type? [ext2]? ext3
Start? 500GB
End? 2199GB
(parted) print
Model: VBOX HARDDISK (ide)
Disk /dev/hdd: 2199GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name Flags
1 17.4kB 500GB 500GB dp1
2 500GB 2199GB 1699GB dp2
7、由于parted内建的mkfs还不够完善,所以完成以后我们可以使用quit命令退出parted并使用 系统的mkfs命令对分区进行格式化了,此时如果使用fdisk -l命令打印分区表会出现警告信息,这是正常的
[[email protected] ~]# fdisk -l #列出的信息不太对,用cat /proc/partitions查看下是否已经有相应的分去了,有的话直接进行格式化。并挂在。记得加上-T largefile 这样可以是格式化的时候很快。
WARNING: GPT (GUID Partition Table) detected on '/dev/hdd'! The util fdisk doesn't support GPT. Use GNU Parted.
Disk /dev/hdd: 2199.0 GB, 2199022206976 bytes
255 heads, 63 sectors/track, 267349 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hdd1 1 267350 2147482623+ ee EFI GPT
[[email protected] ~]# mkfs.ext3 -T largefile /dev/hdd1
[[email protected] ~]# mkfs.ext3 -T largefile /dev/hdd2
[[email protected] ~]# mkdir /dp1 /dp2
[[email protected] ~]# mount /dev/hdd1 /dp1
[[email protected] ~]# mount /dev/hdd2 /dp2
7、文件系统的内部结构详解,有兴趣的可以看下。加深对文件系统的认识。首先先解决几个问题
1>gpt和mbr分区机制的不同(为什么用两个工具进行分区--fdisk和parted)。直接引用大神的图文说明。通过阅读可以知道为什么mbr分区机制不支持大于2T的分区。这就是gpt分区机制的产生原因。
MBR
MBR即主引导记录(Master Boot Record),位置在磁盘的第一个逻辑扇区,即LBA0的位置。一个逻辑扇区仅有512B(字节),分给MBR分区表的只有64B,由4个16B大小的分区,这也是硬盘主分区数目不能超过4个的原因,MBR分区表最大可寻址的存储空间只有2TB(2^32 * 512)。标准MBR结构如下:
由上图可以看出,MBR主要由三部分组成,主引导程序、硬盘分区表(DPT)、分区有效标志。主引导程序占据446字节,分区表占据64字节,由4个大小为16字节的主分区组成,还有分区有效标志占据2字节。接下来谈谈有关这三个部分的作用:
- 主引导程序(boot loader):主要负责从活动分区中装载并运行引导系统程序
- 分区表(DPT,Disk Partition Table):将大表的数据分成称为分区的许多小的子集。如果磁盘丢失了分区表,数据就无法按顺序读取和写入,导致无法操作
- 分区有效标志(magic number):有的地方也称为结束标志字,固定值为0xAA55或者0x55AA,取决于处理器类型,如果是小端模式处理器(如Intel系列),则该值为0xAA55,如果是大端模式处理器(如Motorola6800),则该值为0x55AA。如果该标志错误,系统就不能启动
传统的BIOS比较低级,它不能像操作系统一样识别文件系统,所有磁盘必须要有一个固定的物理块作为引导块(Boot Block),这个引导块就是MBR。也就是说MBR是用来引导内存加载并运行操作系统内核的。
GPT
GPT即全局唯一标识分区表(GUID Partition Table)是一个实体磁盘的分区表的结构布局的标准。它是可扩展接口(EFI)标准的一部分。由于MBR分区表最大可寻址的存储空间只有2TB这个局限性。CPT就诞生了,CGPT分类64bits给逻辑块地址,这就意味着寻址存储空间达到8ZB。GPT支持最多128个主分区。CPT结构图如下:
如图可以看出:GPT分为以下几个部分:
- 保护性MBR: 处于位置LBA0,是在CPT分区表的开头,为了兼容性而存在的传统的MBR。一般情况下是没有引导代码,仅仅有一个被标识为未知的分区,当支持GPT分区表的操作系统检索到这个MBR后会自动忽略并跳到LBA1读取CGT分区表。
- GPT头:定义了硬盘的可控件和组成分区表的项的大小和数量,还记录了这块硬盘的GUID,记录了分区表头本身的位置和大小以及备份分区表头和分区表的位置和大小。
- 分区表:用于存储分区的信息。如(分区类型GUID,起始LBA,末尾LBA等)
- 分区:是物理磁盘的一部分,作用如同一个物理分隔单元。其基本信息存在分区表中。
- 分区表备份对分区表进行备份
- GPT头备份对GPT头进行备份。处于硬盘最后面
2>以ext2文件系统为例理解文件系统的内部结构。
文件系统:我们经常看见的磁盘分区或者我们经常用的U盘就是一个文件系统。他们都是被格式化后的。 所有要用的存储设备都必须经过格式化之后才能存储数据。
文件系统的存储布局(可以说格式化后的磁盘内部结构)
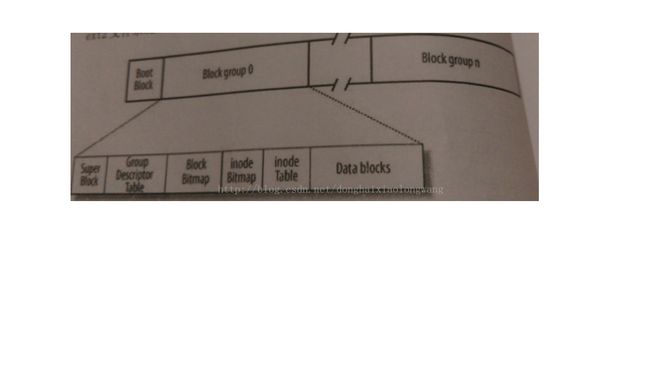
上图就是文件系统的结构,文件系统中最小的存储单位是块(Block),格式化时默认大小1024字节(有很多是4096字节),当然可以指定其它值。图中最前面的是Boot Block启动块(存储磁盘分区信息和启动信息),之后是Super Block超级块(存储分区的文件系统信息,例如块大小,文件系统版本号,上次MOUNT时间等,超级块在若干块组前都有一份拷贝),快组描述符表(存储块组描述符,有多少块组就有多少块组描述符,主要存储从哪里开始是INODE表,从哪里是数据块开始,有多少空闲inode和数据块,块组描述符表也在各个块组中都有拷贝),之后是块位图Block Bitmap,(描述块组中那些块空闲,那些已经被用了。它的大小是一个块,它的每个位都表示一个块是否被用,1表示已经用了)。
一个分区分成多少块组,假设分区大小s块(s kb),一个块组最多有8b个块(b为块大小),那么块组个数=s/8b。
之后是inode位图:(大小为1个块,用来表示inode表中的inode使用情况)
之后是inode表(存储inode节点,每个文件都有1个inode节点,存储该文件的文件类型、权限、文件大小、创建修改访问时间)ls命令查看的信息都是在inode中保存的。一个inode
节点128个字节。(默认一个块组是有多少8k就有多少inode)。
之后是数据块(用于存储文件的数据),文件的存储规则:

下图就是超级块的样子:

下图是块组描述符的样子:

块组描述符表示的信息:


最后图片的最后划线的那行表示已用inode11个,第2个inode是根目录的inode,第11个是lost+found的inode。
根目录的inode样子如下图:

根目录的数据块如下图:

数据块寻址:


一句话每个文件都有一个inode节点,每个节点中都保存着这个文件都用到了数据块中的那些块(可以是连续的也可以是不连续的),我们通过文件的inode就可以找到该文件的内容(数据块)。
举例说明找磁盘文件的过程:以根目录为例(目录也是文件,只是特殊的文件)简述寻找过程,找到根目录的inode节点(节点2),-》inode节点的Block[0]指向数据块位置,找到根目录的数据块位置-》找到数据块中的文件名的记录(就是我们要找的文件名假设为123)-》根据这条记录的信息找到123这个文件的inode-》再根据123文件的inode节点中的Block[],
找到123文件的数据块-》123后边如果还有要找的文件查找过程以此类推。
下边是Linux内核VFS子系统的图:每个PCB(进程控制块,内核中进程的代表)中都有一份文件描述符表,它里边存储着很多文件描述符,每个描述符都指向代表该文件的file结构体,我们经常在文件操作是打开函数得到的就是一个文件描述符。文件描述符所指向的结构体中的f_op指针指向的就是操作这个文件的系统服务例程(就是内核磁盘的驱动),结构体中的d_entry指针指向的就是某目录的“目录项缓存”(他是个结构体,成员有这个文件的inode的指针还有一些其他成员,主要用于寻找该目录下的其他目录或文件——想一下找文件的过程,缓存目录项的方法只是减少了读盘的次数,利用缓存手段可以减少读盘次数,但是知识方便了访问过的文件,对于为访问过的文件还得读磁盘)。
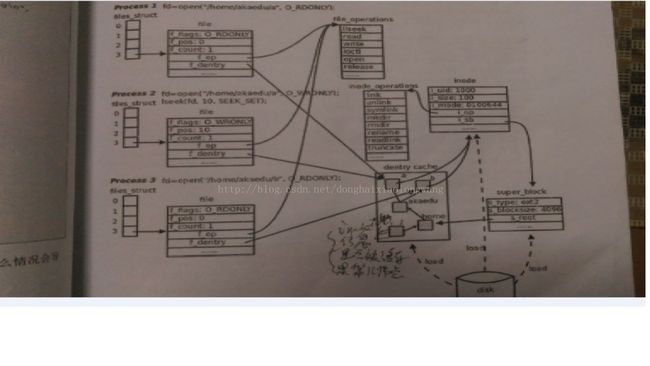
之前的问题请自行在这个原理介绍中查找。如有那些理解有误请帮忙指出,共同进步。
8、了解内容
windows系统安装支持 UEFI+GPT、MBR+BIOS。
Linux系统支持UEFI+GPT、MBR+BIOS、MBR+GPT。
操作系统的启动是有一定顺序的,传统的启动方式(详细的启动流程请自行google)大致是BIOS上电自检->加载MBR->加载磁盘上的内核,操作系统这样启动是需要硬件支持的,即MBR+BIOS。传统的MBR转变成了GPT。操作系统的启动当然也需要改变。这里不是介绍操作系统的安装,有兴趣的话可以自己去研究下。