Yolo算法--从原理到实现(二)
YOLO 训练自己的数据-darknet的实现
安装darknet
darknet官网都有很详细的步骤:https://pjreddie.com/darknet/yolov2/
如果你用的是ubuntu,可以打开终端,在终端输入以下几行代码。我自己是在ubuntu上进行的。第一行是下载darknet的包,解释一下,用darknet训练的好处就在于,你不需要过多的操心网络的结构,损失函数,等等一系列的问题,只需要下载这个包,进入这个包,然后编译。之后就是数据预处理,然后把数据丢进去,修改相应的配置文件,即可开始训练。当然你也可以通过这个github 的链接去下载这个包,然后解压。 https://github.com/pjreddie/darknet
git clone https://github.com/pjreddie/darknet
cd darknet
make在不同的电脑上,可能你每一步都会遇到问题,但有问题要耐心解决。我编译的时候也遇到了各种问题。那么接下来就是对数据集的准备和预处理了。
首先你要知道,既然是训练数据,比如说我有一张图,图片中有狗,那么你要告诉计算机,我图片的名字,我图片中有一条狗,这算是一种标签。那么对于yolo,我标签要告诉计算机的是,我这里有一条狗,狗的位置在某一个地方。具体位置告诉计算机。那么下面我们就要来得到图片和所谓的标签了。
1. 图片和标签
(1)采用jpg格式的图像,在名字上最好像使用voc一样类似000001.jpg、000002.jpg.
(2)标记信息的格式xml,命名和图片一一对应,标记内容格式与VOC中标记信息的格式类似,标注工具有labe image,某一xml中具体内容如下:(如果不知道VOC是什么,可以去百度搜索一下voc2007,voc2012等数据集的下载,然后自己下载电脑上解压,看看里面是由什么构成的)。
【注】当然你可能还会问,这个xml文件是怎么生成的?这个问题可以去百度,我知道有一种专门给图片做标记的软件叫做labelimg,当你给图片做了标记之后,会自动在图像同一个文件夹下生成一个与图片同名的后缀为.xml的文件。包含了你刚才标记的信息。xml文件画风如下:

这个voc2007或者voc2012文件夹下的文件结构大致是这样的:
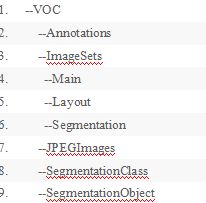
这里面用到的文件夹是Annotations、Imagesets和JPEGImages,其中Annotations中保存的都是xml文件,每一个xml文件对应一个图像,并且每个xml中存放的是标记的各个目标啊和位置信息。每一个xml对应一张图像,并且每个xml中存放的是标记的各个目标的位置和类别信息,命名与对应的原始图像一样;而ImageSets我们只需要用到Main文件夹,这里面存放的是一些文本文件,通常为train.txt、test.txt等,该文本文件里面的内容是需要用来训练或测试的图像的名字(无后缀无路径);JPEGImage文件夹中放我们已按统一规则命名好的原始图像。在ImageSets文件夹中,新建三个空文件夹Layout、Main、Segmentation,然后把写了训练或测试的图像的名字的文本拷到Main文件夹下。
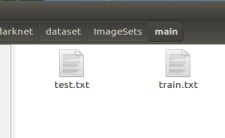
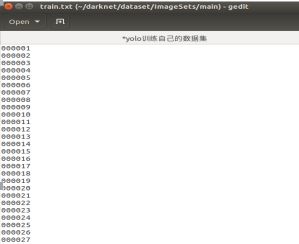
在制作标签txt 前需要得到所有图片的命名文本,一张图片的名字为一行,且训练集和验证集(train.txt,test.txt)分为两个文本文件,放在上述的Main文件夹下,形如:
生成标签txt可以参考官网提供的voc_label.py,打开之后是这个样子的一个文件。这个文件我当时改了好久,这个文件的作用就是将之前的xml文件里的关键信息提取出来,记录成txt文档的形式保存。尽量读懂这个代码,要注意对路径的修改。否则运行完之后你找不到生成的文件。
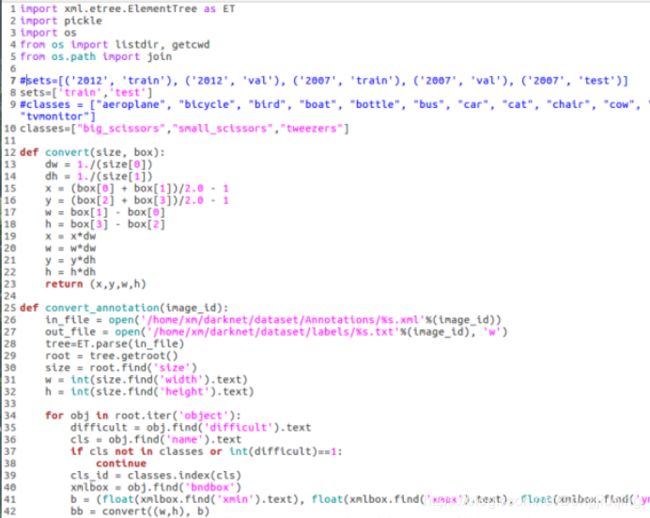
那么什么叫关键信息,就是之前论文里提到的,框位置以及类别的信息,每个txt中保存的是该图片的标签信息: 类别、x、y、w、h 。类别的信息为整数,剩下的四个数即论文中做了处理的在[0,1]之间的数。
画风如下:

当然voc_label.py还会生成另外两个txt文档,train.txt和test.txt,这两个文档包含了图片的路径,应该是这样的:
上述都准备好了,就代表我们的数据集准备工作完成了。核对一下有哪些内容:图片.jpg、标签.xml、每张图片的标签.txt、图片路径(train.txt、test.txt),并保证他们在对应的文件夹下。数据处理麻烦就麻烦在你所有的路径一定要对,否则计算机怎么能找到你的图片呢?我第一次接触这个代码时候用了一周,因为也是摸索着来的。老是报错,不是图片找不到,就是xml文件转的txt文档找不到。或者就是txt文档生成的数据错误。
那么上面就是全部的对数据进行处理的步骤了,做完以上的所有东西,下面就是修改配置文件。那么配置文件主要是包括学习率啊,batch_size啊,迭代次数啊还有就是在论文里提到的一些参数。细节如下:
在文件夹cfg中有很多.cfg文件,应该跟caffe中的prototxt文件是一个意思。这里以yolo_v2.cfg为例,我们修改名字my_yolov2.cfg。主要修改参数如下:
(1).cfg中:
网络层的最后一个卷积层(region上)中的filters需要修改,计算公式是自己数据的类别数:filters=num×(coords + 1+classes)=5×(1+4+1)=30(我这里是1类,coords设定好的是4),这个可以参考我上篇原理部分进行改。
num就是每个格子预测boundingbox的数目,coord是四个坐标,1,是置信度。classes是类别数目。那么我这fillters输出的就是这个维度,

(2)接下来修改data文件下的voc.names。打开voc.names文件可以看到有20类的名称,我们只有3类。修改成我们的类别名称,一类一行。注意:这里类别的顺序要和之前voc_label.py第10行修改类别名的顺序保持一致。
(3)修改cfg文件夹下的voc.data
- classes= 1 //类别数
- train = /home/xm/darknet/dataset/train.txt //训练样本的绝对路径文件,也就是上文通过voc_label.py生成的 train.txt
- valid = /home/xm/darknet/dataset /test.txt // 验证样本的绝对路径文件,也就是上文通过voc_label.py生成的 test.txt
- names = data/voc.names //上一步修改的voc.names文件
- backup = backup//指示训练后生成的权重放在哪
(4)修改example/darknet.c文件的第440行,将“cfg/coco.data”改为“cfg/voc.data”,如下,
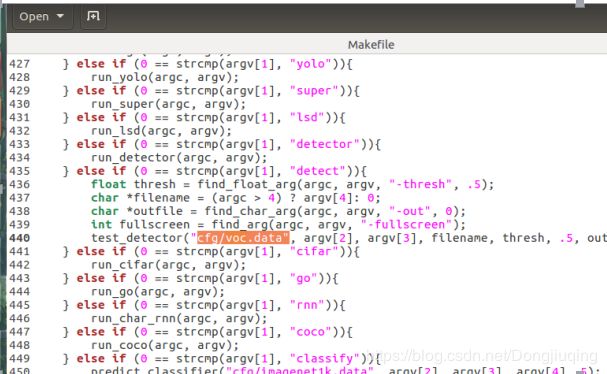
这一步如果不修改,那么你之后训练图片检测的时候得到的boundingbox显示的类名将会是coco包含文件的类名。
(5)如果需要调用gpu、opencv则在Makefile文件中修改:
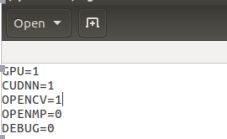
上述修改并保存后,在终端输入make clean 结束后再输入make,make 结束不报错就可以进行训练了。
(6)如果想修改迭代次数等修改.cfg中的max_batches。其他参数可以在网上查找yolo源码解析。
训练
训练命令为:
./darknet detector train cfg/my_voc.data cfg/ my_yolov2.cfg
也可以在官网上找到一些预训练的模型作为参数初始值,下载预训练模型放在darknet文件夹下,这里使用的是官网的预训练模型darknet19_448.conv.23做初始化,则训练命令为:
./darknet detector train cfg/my_voc.data cfg/ my_yolov2.cfg darknet19_448.conv.23
训练好的模型存放在darknet /backup文件中。
当然上面这几条命令和下面的测试命令中都是有相对路径,并且包含了具体文件的。因此你要用实际在你自己电脑上匹配的那个文件的名字。因为我不知道你是不是改了文件名。
测试
在终端输入:
./darknet detect cfg/yolov2.cfg backup/yolov2_final.weights data/2.jpg
结果:
