本文翻译自http://taligarsiel.com/Projects/howbrowserswork1.htm
注:原文有些罗嗦的内容直接隐去了,有兴趣的可以阅读原文。
还有一篇翻译过的:http://ux.sohu.com/topics/50972d9ae7de3e752e0081ff。 我想再翻译一遍,原因是,一是为了学习,翻译是个不错的途径;二是,也加入一些自己的理解。
介绍
浏览器基本结构
浏览器主体组件有:
1. 用户界面(User Interface): 包括工具栏、前进/后退按钮、书签菜单等;
2. 浏览器引擎(Browser engine):查询和管理渲染引擎的接口;
3. 渲染引擎(Rendering engine):负责显示请求内容。如,如果你请求的是HTML,它负责解析HTML和CSS并将解析结果显示在屏幕上。
4. 网路(Networking):执行网络请求,如HTTP请求等;
5.UI backend : 负责绘制基本的组件,如combo box和窗口。它只提供一个简单接口,各个平台要实现这些接口;
6. Javascript 解析器
7. 数据存储(Data Storage) 这是一个持久层,浏览器需要存储各类数据,如cookies。HTML5定义了浏览器中的数据库"web databadse"。

图1. 浏览器主组件
Chrome浏览器与其他浏览器不同,它是渲染引擎多进程的,每个网页在分离的进程中渲染。一个标签一个进程(虽然实际情况并不是这样,但是基本上可以这么理解)。
渲染引擎(The rendering engine)
渲染引擎,自然是用来渲染了(废话)。 默认情况下,渲染引擎可以显示HTML, XML文档和图片。也可以通过插件显示别的内容。例如PDF。本章不讨论插件,重点讨论HTNMl和图片的渲染。
各浏览器的渲染引擎
Firfox使用Gecko-Mozilia官方引擎。Safari和Chrome都使用Webkit。
主流程
渲染引擎从网络获取内容后开始工作。下面是它的主要工作流。

(解析HTML以构造DOM-> 渲染树构造 -> 布局渲染树 -> 绘制渲染树)
渲染引擎首先将解析HTML,将标签转换位DOM的节点树,这颗树成为”内容树“。同时还要解析风格,包括外部的CSS文件和内部的style元素。
这些风格定义信息和HTML的可见元素将床另外一棵树:渲染树。
渲染树包括矩形区域信息和可见属性,如颜色和位置。矩形区域将以正确的次序显示在屏幕上。
然后,渲染引擎进入布局过程。此过程将计算每个节点在屏幕上正确的坐标。然后是绘制,遍历渲染树上每个节点并绘制到UI backed层。
为了提升用户体验,渲染引擎会尽力尽早的显示出内容。不会等到HTML下载完成并解析和布局后。
主流程实例
Webkit的主流程:

Mozilla Gecko渲染引擎的主流程:

上两图说明Webkit和Gecko使用的技术明显不同,但是基本流程一样。
Gecko将可见元素组成的树为Frame树。每个元素都是一个frame。wekbit则使用"Render Tree"这个概念,它由"Render Objects"。Webkit使用"layout"描述元素定位,而Gecko则使用"Reflow"。 Webkit将DOM节点创建对应的"Render Tree"节点的过程为“Attachment"。
除此之外,Gecko在HTML和DOM树增加了一个额外层--“content sink",它是创建DOM元素的类工程。
HTML解析器
HTML解析器的功能是将HTML源码解析为一个解析树。
DOM
DOM即Document Object Model. 以对象化的方式保存HTML文档信息,并为javascript提供对外访问接口。
例如,
w3c也将它标准化了, http://www.w3.org/DOM/DOMTR. HTML的定义,参阅 http://www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
解析算法
通常的文本解析是不能满足HTML的解析要求的。why?
1. 语法较为宽松
2. 浏览器历来对不规范的语法采取包容的态度
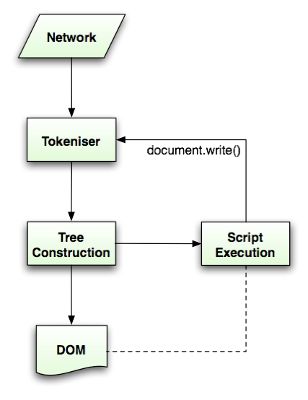
3. 解析过程是可重入的。通常的源码都不会在解析过程中发生变化。但是HTML却可以,如包含"document.write"的脚本,就可以增加新的源码,改变解析输入的内容。
所以,HTML使用特有的解析方法。它包括两个部分 tokenization和 tree construction。
tokenization是词法分析器,将输入流转换为标记(token。这个过程,就好比将字符串流分成单词,每个单词按照它的含义创建出对应的对象。这个对象就是token,这个过程就是tokenization)。 这些token包括:开始标记(Start tag token),结束标记(end tag token),属性名(attribute name)和属性值(attribute value)。
tokenizer识别token,将token交割tree constructor,然后取下个字符,继续下个token的识别,直到输入流的结尾。
tokenization 算法
tokenization算法的输出是HTML token。 这个算法被描述为一个状态机的。每个状态从输入流中获取一个或者多个字符,并依据输入的字符来确定下个状态。 下个状态的确定,受到当前tokenization装和tree construction状态的影响。
我们从一个简单的例子入手。
考虑如何tokenizing下面的HTML
Hello world
初始状态为 "Data state", 当 '<' 字符到来时,状态变为"Tag open state" (标签开入状态)。 收到"a-z"字符时,会创建一个"开始标签 token", 状态也会变为 "Tag name state",直到收到">"字符。 这个状态下每个字符都会添加到token name中。在我们的例子中,我们创建了一个"html" token。
当">"字符达到,当前的token就会被提交,状态也相应的回到"Data state"。 ""标签的过程也是如此。
当"html"和"body"两个token被提交后,状态进入到"Data state"。此时,收到”Hello world"中的"H"标签,将创建一个字符token,直到""的"<"字符到来。然后,我们将提交这个字符token,然后又进入到了"Tag open state"。 因为下个字符是"/",因此,它创建了一个"结束标记token",并转换到"Tag name sate",直到收到">"字符。 然后新的结束标记token被提交,状态即重回"Data state"。"