java常用面试题持续积累~(参考后的个人总结,有问题请指明,非常感谢)
一、什么是字符串常量池(存放的是对象的引用[存放了地址],对象存在堆内存中)
1、 JVM为了减少字符串对象的重复创建,维护了一个特殊的内存,这段内存就被称为字符串常量池或者字符串字面量池。
2、工作原理:当出现字面量形式的字符串对象时,JVM会首先对这个对象进行检查,如果字符串常量池中存在相同内容的字符串对象的引用,则将这个引用返回,否则就创建新的字符串对象,并将这个对象的引用放入字符串常量池,并返回该对象的引用。当使用new创建字符串对象时,不管字符串常量池中是否有相同内容的对象的引用,都会创建一个新的对象。[字面量形式:String str = "str"。new形:String str = new String("str")]
3、当使用new创建对象后,可以调用intern()方法把这个对象的引用存到字符串常量池中。
实例:String str = "xisan"; String str1 = new String("xisan"); String str2 = str1.intern(); str2 == str;[返回了true]
intern()详解:调用该方法后,首先会检查字符串常量池中是否有该对象(str1)的引用,如果没有,就将引用存入字符串常量池中并且返回给变量(str2),如果有就直接把引用返回给变量(str2)。
4、优点:减少了相同内容字符串的创建,节省了空间。缺点:牺牲了CPU计算时间(查找是否有引用)来换取空间。
二、String为什么是不可变的
1、jdk1.7版本中, String内部只剩下了两个变量,value[]和hash,一个用来存储字符,一个用来存储哈希值的缓存。存储字符的value[],是final类型,不可改变的,因此String一旦初始化,就不可改变了。
2、replace、toLowerCase等方法来改变String对象的值,其实是重新创建了一个新的String对象并且将引用返回给变量,原来的String对象还存在。
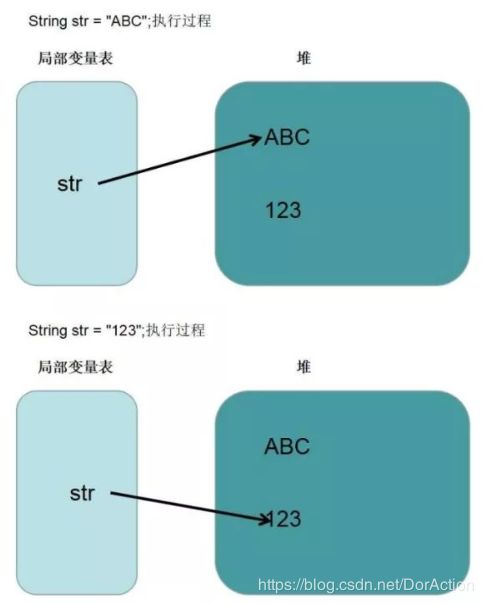
三、String s = new String("xyz");究竟产生了几个对象,从JVM角度谈谈?
1、当字符串常量池中没有"xyz"的时候,会创建两个对象,一个是字符串对象xyz,另外一个是new出来的String对象。
2、当字符串常量池中有"xyz"的时候,只会创建一个由new出来的String对象,至于"xyz",常量池会返回一个引用。
四、String拼接字符串效率低,你知道原因吗?
String中拼接使用"+"的时候,每做一次"+"就会产生一个StringBuilder对象,然后append后就丢掉这个StringBuilder对象,下次"+"就会再次产生一个StringBuilder对象,重复操作到运算结束。如果直接采用StringBuilder对象进行字符串的append的话,我们可以节省和销毁对象的时间。
五、i++是线程安全的吗?如何解决线程安全性?
每个线程都有自己的工作内存,对于操作共享变量的时候,需要从主内存load下来到自己的工作内存,等完成对共享变量的操作后在save到主内存中。
从上面就可以看出问题了,因为多线程去同时去访问的这个共享变量"i"的话,其他线程操作完变量后,还没save到主内容,别的线程就访问到了原来的"i"的值,那这样原本操作的"i"的值就没被读取到了,就产生了脏数据,由此可见,i++不是线程安全的。(扩展:volatile关键字 不能解决这个问题,因为它只保证了可见性并不保证原子性。多个线程同时读取这个共享变量的值,就算保证其他线程修改的可见性,也不能保证线程之间读取到同样的值然后相互覆盖对方的值的情况)
解决方案:1、对i++操作加上同步锁,可以通过synchronize或者ReentrantLock来提供同步,但是个人觉得用synchronize这个更好一些吧,大多数人在用都比较熟悉。
2、使用支持原子性操作的类,如 java.util.concurrent.atomic.AtomicInteger,它使用的是CAS(转:https://blog.csdn.net/qq_32998153/article/details/79529704) 算法,效率优于第 1 种。因为传统的锁机制需要陷入内核态,造成上下文切换,但是一般持有锁的时间很短,频繁的陷入内核开销太大,所以随着机器硬件支持CAS后,java推出基于compare and set机制的AtomicInteger,实际上就是一个CPU循环忙等待。因为持有锁时间一般较短,所以大部分情况CAS比锁性能更优。最初是没有CAS,只有陷入内核态的锁,这种锁当然也需要硬件的支持。后来硬件发展了,有了CAS锁,把compare 和 set 在硬件层次上做成原子的,才有了CAS锁。
六、浅析volatile关键字(先说下java内存)
1、java内存模型规定所有变量都存在放主内存中,每个线程执行的时候,都会去主内存中拷贝一份到自己的工作内存中,然后去对这些变量进行操作。所以多线程之间需要通过去访问主内存来获取变量,那么每个线程修改后的变量就应该及时存储到主内存中,这就是volatile关键字需要解决的事情。(图片copy了其他博客的)

2、volatile关键字就是为了解决上面说的,数据一致性的问题。简单说明就是上图的线程A修改了变量"i"的值后,会直接刷新主内存中的变量"i"的值。当线程B在对变量"i"读取的时候,发现变量"i"是volatile关键字修饰的变量,就放弃从工作内存中读取而直接去主内存中读取,这样就保证了数据的一致性了。
3、第2点说了volatile可以保证数据一致性,但是,在多线程中会出现这种情况,当存在i++这类操作的时候,由于这类操作不是原子性(要么成功,要么失败,不会存在执行过程被中断)的,如果线程A执行i++的时候发生了阻塞,这个变量"i"的值还没刷新到主内存中去,这个时候线程B也执行了i++这个操作并且执行成功了,但是它执行的时候从主内存中拿到的"i"的值,并不是线程A执行过后的值,这样就产生了脏读。这个时候的解决方法就是使用同步关键字synchronize或者ReentrantLock来保证数据正确性了。
七、从字节码角度深度解析 i++ 和 ++i 线程安全性原理?
当线程启动的时候,jvm会分配一块内存当做该线程的java栈,每个栈由一系列的栈帧组成。每个栈帧对应一个方法,当线程执行方法时,就是栈帧出栈,入栈的过程。每个栈帧包含三部分数据:本地变量(参数+方法内的变量)、操作数栈和其他数据,本文主要涉及本地变量和操作数栈。
1、i++(图从其他博客截图而来:https://blog.csdn.net/hotchange/article/details/79844565)

从上图很明显看出,变量"i"到最后会被覆盖成原来的值。
2、++i

