1. 针对机器学习/深度神经网络“记忆能力”的讨论
0x1:数据规律的本质是能代表此类数据的通用模式 - 数据挖掘的本质是在进行模式提取
数据的本质是存储信息的介质,而模式(pattern)是信息的一种表现形式。在一个数据集中,模式有很多不同的表现形式,不管是在传统的机器学习训练的过程,还是是深度学习的训练过程,本质上都是在进行模式提取。
而从信息论的角度来看,模式提取也可以理解为一种信息压缩过程,通过将信息从一种形式压缩为另一种形式。压缩的过程不可避免会造成信息丢失。
笔者这里列举几种典型的体现模式提取思想的算法。
1. 矢量图表示法
1)像素图表示法 - 最原始的信息记录方法
像素这个概念我们都非常熟悉,像素是表示每个图像的基本单位。
传统的bmp位图亦称为点阵图像或绘制图像,是由称作像素(图片元素)的单个点组成的。这些点可以进行不同的排列和染色以构成图样。
当放大位图时,可以看见赖以构成整个图像的无数单个方块。扩大位图尺寸的效果是扩大单个像素,从而使线条和形状显得参差不齐。
同时,缩小位图尺寸也会使原图变形,因为此举是通过减少像素来使整个图像变小的。
同样,由于位图图像是以排列的像素集合体形式创建的,所以不能单独操作(如移动)局部位图。可以想象一下,位图的移动类似数组的平移,成本非常高。
2)矢量图表示法 - 记录信息不如记录生成原理
矢量图,也称为面向对象的图像或绘图图像,在数学上定义为一系列由线连接的点。
矢量文件中的图形元素称为对象。每个对象都是一个自成一体的实体,它具有颜色、形状、轮廓、大小和屏幕位置等属性。
矢量图使用直线和曲线来描述图形,这些图形的元素是一些点、线、矩形、多边形、圆和弧线等等,它们都是通过数学公式计算获得的。
例如一幅花的矢量图形实际上是由线段形成外框轮廓,由外框的颜色以及外框所封闭的颜色决定花显示出的颜色。
矢量图最大的好处是“存储成本小”,因为矢量图并不需要存储原始文件的所有像素信息,而只要存储有限的用于生成原始像素图像的生成算法即可(颇有机器学习模型参数的感觉),因此,矢量图可以无限放大而不会增加额外的存储成本。
2. K-mean聚类
1)聚类前的数据集(原始信息)是怎么样的?

2)聚类后得到的压缩后信息是怎么样的?

原始数据集经过K-mean之后,得到的压缩后信息为 N 个聚类中心,N 由算法操作者决定。
3)Kmeans压缩后信息如何代表原始的信息?
聚类得到的 N 个聚类中心就是 K-means模型的模型参数。
从某种程度上来说,这个 N 个聚类中心就可以代表原始的样本信息。
训练得到的Kmeans模型可以用于新样本的标注(预测),当输入待检测样本的时候,Kmeans根据一定的搜索算法,搜索已知的聚类中心,将待检测样本打标为最靠近的那个类别。
这样,Kmeans通过 N 个聚类中心,实现了原始信息的模式提取,或者说核心信息压缩。
3. 线性回归模型学习
一个典型的例子。
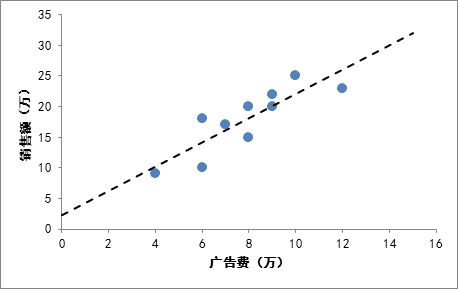
在一元线性回归的场景中,线性回归模型通过训练得到:Y = ax + b。
通过2个参数【a,b】,对原本庞大的样本点集进行了描述。
从上面3个例子中,可以看到一个共通点,即“信息压缩”,它们的本质都是抽象出了一种形式化表达,而这种表达就代表了一种模式,这种模式可以代表原本的海量样本集中的某种形式的规律。
至于如何提取这种模式规律,以及提之后的模型规律如何被运用进行后续的新的预测,就是不同机器学习算法的变化所在了。
0x2:神经网络是如何记忆和存储数据中的模式规律的?
机器学习的神经是参考人脑神经网络的构造而创造的,那人脑神经网络又是如何识别、存储、记忆每天看到的我们所谓的有用的知识的呢?
这块内容笔者只是查询了网上的一些讨论资料,完全跨专业了,也只是看科普看了一些大概,目前业内似乎并没有一个准确的定义,很多的讨论似乎是在实验观测和理论假设猜测之上。
但是我看下来,有几个观点很多业内学者提到:
1. 记忆并不是一个直接通过bit方式存储在大脑内,而是通过一些的神经细胞的结构来存储,即结构及记忆知识,换言之,大脑并不是直接存储知识本身,而是存储知识的概念结构,也就是所谓的模式; 2. 脑内反映某外界客观物体,是由被该外界刺激激活的所有皮层细胞组成的,这些同时被激活的神经元称作“细胞集合”,假如这些细胞相互连接,细胞集合内的连接持续激活,对外界客观物体的内部反应就能作为短时程记忆始终保存,如果细胞集合能持续激活很长一段时间,那么细胞间相互连接更有效的神经元就会连接在一起,更紧密的连接就会使细胞集合再次兴奋,记忆的巩固就可能发生。换句话说,要记忆某种信息模式,就必须生成相应的神经网结构,并且通过不断的刺激使之固定下来; 3. 仅仅集团内的一部分细胞的破坏并不能消除记忆,记忆的痕迹广泛分布于细胞集合的细胞连接内。
Relevant Link:
https://arxiv.org/pdf/1706.05394.pdf http://www.360doc.com/content/17/0622/19/16619343_665595088.shtml https://www.zhihu.com/question/20264424
2. 循环神经网络RNN(Recurrent Neural Network)介绍
循环神经网络(recurrent neural network)或 RNN 是一类用于处理了序列数据的神经网络。我们这个章节来针对RNN的一些基本概念展开讨论。
0x1:共享参数思想
我们先从参数共享机制说起,这是RNN循环神经网络的一个核心特点,也是RNN能够拥有某些强大性能的原因之一。
参数共享机制使得神经网络对序列数据中的模式具备了一定的平移不变泛化能力,以及模式记忆能力。
1. 从传统全连接前馈网络的特征表征说起 - 不包含参数共享机制
不单是对DNN,传统的机器学习模型,也全都要求输入的特征向量是一个定长的vector。
对这种定长的 feature vector,不同的特征维度之间是正交独立的,即打乱顺序是不会影响最后的检测结果。所以开发者在进行特征工程的时候,并不需要考虑特征之间的序列关系,只要把特征“堆”到一起即可。
传统的全连接前馈网络会给每个输入特征分配一个单独的参数,不同特征对应的参数是单独调整的。
需要注意的是,在NLP场景中,传统机器学习算法经常和词袋编码结合使用。词袋编码虽然不具备共享参数能力,但是因为词袋编码本身就就丢弃原始文本中的时序信息,即词袋特征对原始文本中的序列顺序变化并不敏感,因此从某种程度上来说,词袋编码具备一定的对时序文本中特征平移的泛化能力。
2. 卷积网络的共享参数 - 感知域平移参数共享
一种捕获文本中相同单词在不同位置的特征的方法是,在 1 维时间序列上使用卷积。
这种卷积方法是时延神经网络的基础 (Lang and Hinton, 1988; Waibel et al., 1989; Lang et al., 1990)。
卷积操作允许网络跨时间共享参数,但是浅层的。卷积的输出是一个序列,其中输出中的每一项是相邻几项输入的函数。
参数共享的概念体现在每个时间步中使用的相同卷积核。
3. RNN中使用参数共享机制实现特征位置平移不变性
从多层网络到循环网络,循环网络吸收了20世纪80年代机器学习和统计模型早期思想的优点:在模型的不同部分共享参数。参数共享使得RNN模型能够扩展到不同长度的序列样本并进行泛化。
如果我们在每个时间点都有一个单独的参数,不但不能泛化到训练时没有见过的序列长度,也不能在时间上共享不同序列长度和不同位置的统计强度。当信息的特定部分会在序列内多个位置出现时,这样的共享尤为重要。
例如,考虑这两句话:“I went to Nepal in 2009’’ 和 “In 2009, I went to Nepal.”。
如果我们让一个机器学习模型读取这两个句子,并提取叙述者去Nepal的年份,无论 “2009年’’ 是作为句子的第六个单词还是第二个单词出现,我们都希望模型能认出 “2009年’’ 作为相关资料片段。
相比传统DNN网络,循环神经网络在几个时间步内共享相同的权重,不需要分别学习句子每个位置的所有语言规则。
相比于CNN卷积网络,循环神经网络以不同的方式共享参数。输出的每一项是前一项的函数。输出的每一项对先前的输出应用相同的更新规则(参数共享)而产生。这种循环方式导致参数通过很深的计算图共享。
此外, 需要注意的是,所谓的时间序列不必是字面上现实世界中流逝的时间。有时,它仅表示序列中的位置。RNN 也可以应用于跨越两个维度的空间数据(如图像)
当应用于涉及时间的数据, 并且将整个序列提供给网络之前就能观察到整个序列时,该网络可具有关于时间向后的连接。
笔者思考:RNN和CNN这种神经网络具备参数共享机制,可以对特征的位置平移实现泛化能力,那是不是就意味着RNN全面优于传统机器学习算法呢?笔者认为答案是否定的!
因为并不是所有的数学建模场景中,特征都呈现时序关系的。总体上来说,特征工程得到的特征分为两大类:1)正交独立的特征集,例如说描述一个桌子的一组物理参数;2)时序特征,例如某人发出的一段声音的声纹信号。
对于正交独立的特征集,时序模型就不一定能发挥其本身的作用,甚至还会起反效果。正交独立的特征集更适合使用传统机器学习模型进行概率分布/模型参数的训练评估。
在具体的AI项目中,我们会遇到各种各样的具体问题,首先要思考的是,从哪些角度入手进行特征工程,如果是正交独立特征集,选择哪些特征?如果是时序特征,选取什么数据抽取时序特征?
4. 参数共享的假设前提
在循环网络中使用的参数共享的前提是相同参数可用于不同时间步的假设。也 就是说,假设给定时刻 t 的变量后,时刻 t + 1 变量的条件概率分布是 平稳的 (stationary),这意味着之前的时间步与下个时间步之间的关系并不依赖于 t。
0x2:RNN网络具备的时序记忆能力
在很多项目场景中,针对当前样本的判断不单单仅限于当前样本,而需要结合历史的样本进行时序依赖判断。
以突显识别举例来说(实际上RNN并不局限于图像时序数据):
如果我们看到一个沙滩的场景,我们应该在接下来的帧数中增强沙滩活动:如果图像中的人在海水中,那么这个图像可能会被标记为“游泳”;如果图像中的人闭着眼睛躺在沙滩上,那么这个图像可能会被标记为“日光浴”。
如果如果我们能够记得Bob刚刚抵达一家超市的话,那么即使没有任何特别的超市特征,Bob手拿一块培根的图像都可能会被标记为“购物”而不是“烹饪”。
因此,我们希望让我们的模型能够跟踪事物的各种状态:
-
在检测完每个图像后,模型会输出一个标签,这个标签对应该图像的识别结果(即RNN每个时间步输出的 y 值)。同时模型对世界的认识也会有所更新(更新隐状态)。例如,模型可能会学习自主地去发现并跟踪相关的信息,如位置信息(场景发生的地点是在家中还是在沙滩上?)、时间(如果场景中包含月亮的图像,模型应该记住该场景发生在晚上)和电影进度(这个图像是第一帧还是第100帧?)
-
在向模型输入新的图像时,模型应该结合它收集到的历史信息,对当前的输入图片进行更合理的综合判断。
循环神经网络(RNN),它不仅能够完成简单地图像输入和事件输出行为,还能保持对世界的记忆(给不同信息分配的权重),以帮助改进自己的分类功能。
0x3: RNN的图灵完备性
"循环"两个字,表达了RNN的核心特征, 即系统的输出会保留在网络里和系统下一刻的输入一起共同决定下一刻的输出。这就把动力学的本质体现了出来, 循环正对应动力学系统的反馈概念,可以刻画复杂的历史依赖。
另一个角度看也符合著名的图灵机原理。 即此刻的状态包含上一刻的历史,又是下一刻变化的依据。
这其实包含了可编程神经网络的核心概念,即当你有一个未知的过程,但你可以测量到输入和输出, 你假设当这个过程通过RNN的时候,它是可以自己学会这样的输入输出规律的, 而且因此具有预测能力。 在这点上说, RNN是图灵完备的。
下面列举了一些可能的图灵操作规则:

1. 图1即CNN的架构 2. 图2是把单一输入转化为序列输出,例如把图像转化成一行文字 3. 图三是把序列输入转化为单个输出,比如情感测试,测量一段话正面或负面的情绪 4. 图四是把序列转化为序列,最典型的是机器翻译 5. 图5是无时差(注意输入和输出的"时差")的序列到序列转化, 比如给一个录像中的每一帧贴标签(每一个中间状态都输出一个output)
0x4:长期依赖的挑战
学习循环网络长期依赖的数学挑战在于“梯度消失”和“梯度爆炸”。根本问题是,经过许多阶段传播后的梯度倾向于消失(大部分情况)或爆炸(很少,但对优化过程影响很大)。
即使我们假设循环网络是参数稳定的(可存储记忆,且梯度不爆炸),但长期依赖的困难来自比短期相互作用指数小的权重(涉及许多 Jacobian 相乘)。
循环网络涉及相同函数的多次组合,每个时间步一次。这些组合可以导致极端非线性行为,如下图所示:

当组合许多非线性函数(如这里所示的线性 tanh 层)时,得到的结果是高度非线性的。
在大多数情况下,导数不是过大,就是过小,以及在增加和减小之间的多次交替。
此处,我们绘制从 100 维隐藏状态降到单个维度的线性投影,绘制于 y 轴上。x 轴是 100 维空间中沿着随机方向的初始状态的坐标。因此,我们可以将该图视为高维函数的线性截面。曲线显示每个时间步之后的函数,或者等价地,转换函数被组合一定次数之后。

是一个非常简单的、缺少非线性激活函数和输入 x 的循环神经网络。这种递推关系本质上描述了幂法。它可以被简化为:

而当 W 符合下列形式的特征分:

其中 Q 正交,循环性可进一步简化为

特征值提升到 t 次后,导致幅值不到一的特征值衰减到零,而幅值大于一的特征值就会激增。任何不与最大特征向量对齐的 h(0) 的部分将最终被丢弃。
1. 多时间尺度的策略
处理长期依赖的一种方法是设计工作在多个时间尺度的模型,使模型的某些部分在细粒度时间尺度上操作并能处理小细节;而其他部分在粗时间尺度上操作,并能把遥远过去的信息更有效地传递过来。
这种循环网络的依赖链是在时间单元间“跳跃的”,类似于我们常常会将不同感知域的CNN Filter进行Stacking以获得综合的效果,多时间尺度的目的也是一样,希望同时兼顾短程依赖和长程依赖的序列特征模式。
细粒度时间尺度不用特殊设计,就是原始的RNN结构。粗时间尺度需要特殊设计,目前存在多种同时构建粗细时间尺度的策略。
1)在时间轴增加跳跃连接
增加从遥远过去的变量到目前变量的直接连接是得到粗时间尺度的一种方法。使用这样跳跃连接的想法可以追溯到Lin et al. (1996),紧接是向前馈网络引入延迟的想法 (Lang and Hinton, 1988)。但其实增加跳跃的本质就是引入延时,本该被传入邻接时间步的输出被延迟传入了之后 N 步时间步中。
在普通的循环网络中,循环从时刻 t 的单元连接 到时刻 t + 1 单元。构造较长的延迟循环网络是可能的。
对于梯度爆炸和梯度消失问题,引入了 d 延时的循环连接可以减轻这个问题。因为引入 d 延时后,导数指数减小的速度变为 τ/d相关,而不是 τ。
既然同时存在延迟连接和单步连接,梯度仍可能成 t 指数爆炸,只是问题会有所缓解。
2)渗漏单元
获得导数乘积接近 1 的另一方式是设置线性自连接单元,并且这些连接的权重接近 1。
我们对某些 v 值应用更新![]() 累积一个滑动平均值 μ(t), 其中 α 是一个从 μ(t−1) 到 μ(t) 线性自连接的例子。
累积一个滑动平均值 μ(t), 其中 α 是一个从 μ(t−1) 到 μ(t) 线性自连接的例子。
当 α 接近 1 时,滑动平均值能记住过去很长一段时间的信息,而当 α 接近 0,关于过去的信息被迅速丢弃。
线性自连接的隐藏单元可以模拟滑动平均的行为。这种隐藏单元称为渗漏单元(leaky unit)。
d 时间步的跳跃连接可以确保单元总能被 d 个时间步前的那个值影响。使用权重接近 1 的线性自连接是确保该单元可以访问过去值的不同方式。
线性自连接通过调节实值 α 更平滑灵活地调整这种效果,比整数的跳跃长度更“柔顺”。
我们可以通过两种基本策略设置渗漏单元使用的时间常数。
1. 一种策略是手动将其固定为常数,例如在初始化时从某些分布采样它们的值; 2. 另一种策略是使时间常数成为自由变量,并学习出来;
3)删除连接
处理长期依赖另一种方法是在多个时间尺度组织 RNN 状态的想法。
一个根本的理论是:信息在较慢的时间尺度上更容易长距离流动。这很容易理解,如果时间尺度很小,信息在每个时间步要迅速的被决策是保留还是舍弃,以及保留和舍弃的比例。时间尺度变慢,意味着决策的次数减少,信息保留的概率就增大了。
这个想法与之前讨论的时间维度上的跳跃连接不同:
1. 该方法涉及主动删除长度为 1 的连接并用更长的连接替换它们。以这种方式修改的单元被迫在长时间尺度上运作; 2. 而通过时间跳跃连接是添加边,收到这种新连接的单元,可以学习在长时间尺度上运作,但也可以选择专注于自己其他的短期连接;
0x5:长短期记忆和门控RNN
像渗漏单元一样,门控 RNN 想法也是基于生成通过时间的路径,其中导数既不消失也不发生爆炸。
渗漏单元通过手动选择常量的连接权重或参数化的连接权重来达到这一目的。门控 RNN 将其推广为在每个时间步都可能改变的连接权重。
渗漏单元允许网络在较长持续时间内积累信息(诸如用于特定特征或类的线索)。然而,一旦该信息被使用了,让神经网络遗忘旧的状态可能是有帮助的。
例如,如果一个序列是由子序列组成,我们希望渗漏单元能在各子序列内积累线索,但是当进入新的子序列前可以忘记旧的子序列的线索信息,我们需要一种忘记旧状态的机制。
我们希望神经网络学会决定何时清除状态,而不是手动决定。这就是门控 RNN 要做的事。
1. LSTM
引入自循环的巧妙构思,以产生梯度长时间持续流动的路径是初始长短期记忆 (long short-term memory, LSTM)模型的核心贡献。
其中一个关键扩展是使自循环的权重视上下文而定,而不是固定的。
我们前面说过,RNN的核心思想就是参数共享,LSTM也同样遵守这个核心思想,所不同的是,LSTM并不是从头到尾参数一直共享,而是在某个“时间区间”内进行共享,在整个时间步链路上权重会动态调整。
在这种情况下,即使是具有固定参数的 LSTM,累积的时间尺度也可以因输入序列而改变,因为时间常数是模型本身的输出。
2. LSTM的核心思想
1. 允许网络动态地控制时间尺度,即信息在时间步链条上的存活时间是动态控制的; 2. 允许网络动态控制不同单元的遗忘行为;
Relevant Link:
https://blog.csdn.net/cf2suds8x8f0v/article/details/79244587 https://blog.csdn.net/qq_36279445/article/details/72724649
3. 循环神经网络计算图(Computational Graph)
本章我们将计算图的思想扩展到包括循环。
这些周期代表了变量自身的值在未来某一时间步会对自身值的影响。这样的计算图允许我们定义循环神经网络。
0x1:计算图定义
我们使用图中的每一个节点来表示一个变量。
变量可以是标量、向量、矩阵、张量、或者甚至是另一类型的变量。
为了形式化我们的图形,我们还需引入操作(operation)这一概念。操作是指一个或多个变量的简单函数。
我们的图形语言伴随着一组被允许的操作。我们可以通过将多个操作复合在一起来描述更为复杂的函数。
如果变量 y 是变量 x 通过一个操作计算得到的,那么我们画一条从 x 到 y 的有向边。我们有时用操作的名称来注释输出的节点,当上下文很明确时,有时也会省略这个标注。
1. 不同操作对应的计算图举例

使用 × 操作计算 z = xy 的图

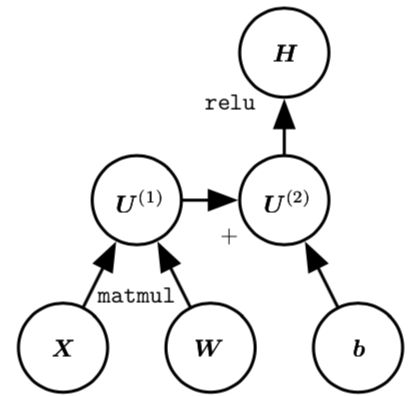
表达式 H = max{0, XW + b} 的计算图,在给定包含小批量输入数据的设计矩阵 X 时,它计算整流线性单元激活的设计矩阵 H。
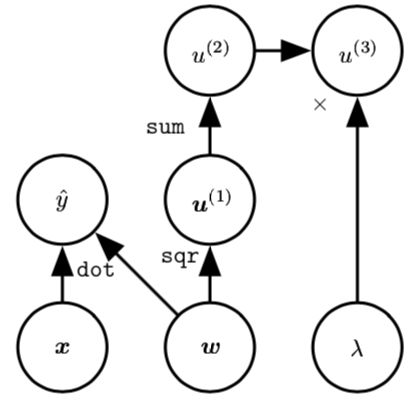
对变量实施多个操作也是可能的。该计算图对线性回归模型的权重 w 实施多个操作。这个权重不仅用于预测 yˆ,也用于权重衰减罚项 λ∑ w2。这就是所谓的结构化风险评估。
0x2:展开RNN计算图
计算图是形式化一组计算结构的方式,如那些涉及将输入和参数映射到输出和损失的计算。我们对展开(unfolding)递归或循环计算得到的重复结构进行解释,这些重复结构通常对应于一个事件链。展开(unfolding)这个计算图将更好地可视化深度网络结构中的参数共享。
1. 动态系统的经典形式计算图
例如,考虑下式:
 ,其中,
,其中,![]() 称为系统的状态。
称为系统的状态。
s 在时刻 t 的定义需要参考时刻 t-1 时同样的定义,因此上式是循环的。
对有限时间步 τ, τ - 1 次应用这个定义可以展开这个图。例如 τ = 3,我们对上式进行展开,可以得到:

以这种方式重复应用定义,展开等式,就能得到不涉及循环的表达式。
现在我们可以使用传统的有向无环图(和HMM一样都是有向无环图概率图模型)呈现上式的表达。

每个节点表示在某个时刻 t 的状态,并且函数 f 将 t 处的状态映射到 t + 1 处的状态。所有时间步都使用相同的参数(用于参数化 f 的相同 θ 值)
2. 存在外部驱动信号的动态系统的计算图
作为另一个例子,让我们考虑由外部信号![]() 驱动的动态系统:
驱动的动态系统:
![]()
从公式上看,当前状态包含了整个过去序列的信息。但是这个历史信息是有损的。
当训练循环网络根据过去预测未来时,网络通常要学会使用 h(t) 作为过去序列的有损摘要。
此摘要一般而言一定是有损的,因为其映射任意长度的序列![]() 到一固定长度的向量 h(t)。
到一固定长度的向量 h(t)。
根据不同的训练准则,摘要可能选择性地精确保留过去序列的某些方面。
例如,如果在统计语言建模中使用RNN,通常给定前一个词预测下一个词,可能没有必要存储时刻 t 前输入序列中的所有信息,而仅仅存储足够预测句子其余部分的信息(类似HMM)。
最苛刻的情况是我们要求 h(t) 足够丰富,并能大致恢复输入序列,如自编码器框架。
上面公式可以用两种不同的方式绘制,如下图:

1)回路图表示法
一种方法是为可能在模型的物理实现中存在的部分赋予一个节点,如生物神经网络。在这个观点下,网络定义了实时操作的回路,如上图左侧,其当前状态可以影响其未来的状态。
我们使用 回路图的黑色方块表明在时刻 t 的状态到时刻 t + 1 的状态单个时刻延迟中的相互作用。
2)展开表示法
另一个绘制 RNN 的方法是展开的计算图,其中每一个组件由许多不同的变量表示,每个时间步一个变量,表示在该时间点组件的状态。每个时间步的每个变量绘制为计算图的一个独立节点,如上图右侧。
我们所说的展开是将左图中的回路映射为右图中包含重复组件的计算图的操作。目前,展开图的大小取决于序列长度。
3. 展开计算图的优点
我们可以用一个函数 g(t) 代表经 t 步展开后的循环:

函数 g(t) 将全部的过去序列![]() 作为输入来生成当前状态,但是展开的循环架构允许我们将 g(t) 分解为函数 f 的重复应用。因此,展开过程引入两个主要优点:
作为输入来生成当前状态,但是展开的循环架构允许我们将 g(t) 分解为函数 f 的重复应用。因此,展开过程引入两个主要优点:
1. 无论序列的长度,学成的模型始终具有相同的输入大小,因为它指定的是从一种状态到另一种状态的转移,而不是在可变长度的历史状态上操作 2. 我们可以在每个时间步使用相同参数的相同转移函数 f
这两个因素使得学习在所有时间步和所有序列长度上操作单一的模型 f 是可能的,而不需要在所有可能时间步学习独立的模型 g(t)。
学习单一的共享模型允许泛化到训练集中未出现的序列长度,并且估计模型所需的训练样本远远少于不带参数共享的模型。
循环神经网络可以通过许多不同的方式建立。就像几乎所有函数都可以被认为是前馈网络,本质上任何涉及循环的函数都可以被认为是一个循环神经网络。
Relevant Link:
《深度学习》花书
4. 循环神经网络逻辑图结构
基于之前讨论的图展开和参数共享的思想,可以设计各种循环神经网络。
读者朋友需要注意的是,循环神经网络不是特指一定具体的算法实现,循环神经网络是特指一整类具备某些特性的神经网络结构,注意要和TensorFlow/theano中的RNN实现类区分开来。
循环神经网络从大的分类来说可以分为以下几种:
1. 从序列到序列的神经网络:即每个时间步都有输出; 3. 从序列到向量的神经网络:即读取整个序列后产生单个输出,即整个循环网络可以压缩为一个拥有唯一输出的循环递归函数; 3. 从向量到序列的神经网络:输入单个向量,在每个时间步都有输出;
在遵循以上设计模型的原则之下,RNN可以进行各种结构上的变种,使之具备相应新的能力和性能。
我们学习RNN,就是要重点理解不同结构之间的区别和原理,理解不同的网络拓朴结构是如何影响信息流的传递和依赖。至于具体网络内部的激活函数是用tang还是relu,其实倒还不是那么重要了。
0x1:经典RNN结构 - 时间步之间存在“隐藏神经元”循环连接
1. 逻辑流程图 - 将输入序列映射到等长的输出序列
下图是该循环神经网络的逻辑流程图:

计算循环网络(将 x 值的输入序列映射到输出值 o 的对应序列) 训练损失的计算图;
RNN输入到隐藏的连接由权重矩阵 U 参数化;
隐藏到隐藏的循环连接由权重矩阵 W 参数化以及隐藏到输出的连接由权重矩阵 V 参数化;
其中每个节点现在与一个特定的时间实例相关联
任何图灵可计算的函数都可以通过这样一个有限维的循环网络计算,在这个意义上公式![]() 代表的循环神经网络是万能的。
代表的循环神经网络是万能的。
RNN 经过若干时间步后读取输出,这与由图灵机所用的时间步是渐近线性的,与输入长度也是渐近线性的。
RNN 作为图灵机使用时,需要一个二进制序列作为输入,其输出必须离散化以提供二进制输出。利用单个有限大小的特定 RNN 计算所有函数是可能的。
RNN 可以通过激活和权重(由无限精度的有理数表示)来模拟无限堆栈。
2. 一个具体的网络结构 - 指定特定的激活函数
再次强调,循环神经网络的结构和具体的激活函数和损失函数是不存在强关联的,网络可以选择任何激活函数。
为了能够更好地公式化地描述上图网络结构,我们指定特定的模型参数。
激活函数:双曲正切激活函数;
输出形式:假定输出是离散的,如用于预测词或字符的RNN。表示离散变量的常规方式是把输出 o 作为每个离散变量可能值的非标准化对数概率;
损失函数。应用 softmax 函数后续处理后,获得标准化后概率的输出向量 yˆ;
RNN从特定的初始状态 h(0) 开始前向传播。从 t = 1 到 t = τ 的每个时间步,我们应用以下更新方程:

这个循环网络将一个输入序列映射到相同长度的输出序列。
与 x 序列配对的 y 的总损失就是所有时间步的损失之和。例如,L(t) 为给定的 x(1),...,x(t) 后y(t) 的负对数似然,则

其中, 需要读取模型输出向量 yˆ(t) 中对应于 y(t) 的项。
需要读取模型输出向量 yˆ(t) 中对应于 y(t) 的项。
0x2:导师驱动过程循环网络 - 时间步之间存在”目标值单元“和”隐藏神经元”连接的循环连接
1. 逻辑流程图 - 将输入序列映射到等长的输出序列
导师驱动过程循环神经网络,它仅在一个时间步的目标单元值和下一个时间步的隐藏单元间存在循环连接。逻辑流程如下:

从本质上理解,这种导师驱动的循环神经网络,就是将多个单神经元感知机按照序列的方式串联起来,相邻神经元感知机之间存在2阶的依赖关系。
2. 导师驱动循环网络的优缺点
1)缺点
因为缺乏隐藏到隐藏的循环连接,所以它不能模拟通用图灵机。本质原因在于,隐藏神经元中保存和传递的是高阶维度特征,隐藏神经元之间循环连接使得这种高阶维度特征得以传播和记忆。
而目标值单元和隐藏神经元相连的网络结构,它要求目标值单元捕捉用于预测未来的关于过去的所有信息。
但是因为目标值单元(输出单元)明确地训练成匹配训练集的目标,它们不太能捕获关于过去输入历史的必要信息,除非用户知道如何描述系统的全部状态,并将它作为训练目标的一部分。
2)优点
反过来说,消除隐藏到隐藏循环的优点在于,任何基于比较时刻 t 的预测和时刻 t 的训练目标的损失函数中的所有时间步都解耦了。因此训练可以并行化,即在各时刻 t 分别计算梯度。因为训练集提供输出的理想值,所以没有必要先计算前一时刻的输出。
3. 导师驱动过程训练(teacher forcing)
由输出反馈到模型而产生循环连接的模型可用导师驱动过程(teacher forcing) 进行训练。
训练模型时,导师驱动过程在时刻 t + 1 接收真实值 y(t) 作为输入。我们可以通过检查两个时间步的序列得知这一点:

在这个例子中,同时给定迄今为止的 x 序列和来自训练集的前一 y 值,我们可 以看到在时刻 t = 2 时,模型被训练为最大化 y(2) 的条件概率。
因此最大似然在训练时指定正确反馈,而不是将自己的输出反馈到模型。
我们使用导师驱动过程的最初动机是为了在缺乏隐藏神经元到隐藏神经元连接的模型中避免通过时间反向传播。
0x3:时间步之间存在“隐藏神经元”循环连接,且网络只有唯一的单向量输出
1. 逻辑流程图 - 将输入序列映射为固定大小的向量

关于时间展开的循环神经网络,在序列结束时具有单个输出。
这样的网络可以用于概括序列并产生用于进一步处理的固定大小的表示。在结束处可能存在目标(如此处所示),或者通过更下游模块的反向传播来获得输出 o(t) 上的梯度。
0x4:基于上下文的RNN建模 - 隐藏神经元之间存在循环连接,且”目标值单元“和”隐藏神经元“之间存在连接
一般情况下,RNN 允许将图模型的观点扩展到不仅代表 y 变量的联合分布也能表示给定 x 后 y 条件分布。
需要重点理解的一点是,输入序列 x 的方式的不同,会造成RNN的效果和性能的很大差别。某种程度上甚至可以说,RNN网络中结构的一个调整,可能就是一个完全不同的新算法了,这也是深度神经网络强大而复杂的一面了。
1. 在每个时间步将完整的 x序列 输入网络中 - 输入序列 x 和输出序列 y 不一定要等长 - 将固定大小的向量映射成一个序列
网络结构如下图所示:

输入 x 和每个隐藏单元向量 h(t) 之间 的相互作用是通过新引入的权重矩阵 R 参数化的。乘积 x⊤R 在每个时间步作为隐藏单元的一个额外输入。
我们可以认为 x 的选择(确定 x⊤R 的值),是有效地用于每个隐藏单元的一个新偏置参数。权重与输入保持独立。
将固定长度的向量 x 映射到序列 Y 上每个时间步的 RNN上。这类 RNN 适用于很多任务如图像标注, 其中单个图像作为模型的输入,然后产生描述图像的词序列。观察到的输出序列的每个元素 y(t) 同时用作输入(对于当前时间步)和训练期间的目标(对于前一时间步)。
笔者思考:这种结构能用于图注任务的原理非常的直观,图注的注解序列的每一个词都应该和整张图片有关,所以需要在每个时间步都输入完整的 x 序列,同时,图注注解序列的单词之间也存在依赖推导关系,因为 y(t) 需要传入下一个时间步。
2. 将 x序列 依次输每个时间步中 - 输入序列 x 和输出序列 y 等长 - 将输入序列映射为等长的输出序列
RNN 可以接收向量序列 x(t) 作为输入,而不是仅接收单个向量 x 作为输入。
接受向量序列的RNN的条件概率分布公式为: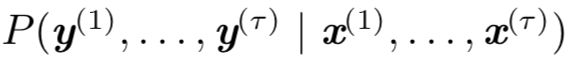

0x5:双向RNN
传统的前馈RNN网络都有一个 ‘‘因果’’ 结构,意味着在时刻 t 的状态只能从过去的序列x(1),...,x(t−1) 以及当前的输入x(t) 捕获信息。
然而,在许多应用中,我们要输出的 y(t) 的预测可能依赖于整个输入序列。
例如,在语音识别中,由于协同发音,当前声音作为音素的正确解释可能取决于未来几个音素,甚至潜在的可能取决于未来的几个词,因为词与附近的词之间的存在语义依赖,如果当前的词有两种声学上合理的解释,我们可能要在更远的未来(和过去)寻找信息区分它们。这在手写识别和许多其他序列到序列学习的任务中也是如此。
双向循环神经网络(或双向 RNN)为满足这种需要而被发明。他们在需要双向信息的应用中非常成功,如手写识别,,语音识别以及生物信息学。
顾名思义,双向RNN结合时间上从序列起点开始移动的RNN和另一个时间上从序列末尾开始移动的RNN。下图展示了典型的双向 RNN
1. 逻辑流程图 - 将输入序列映射到等长的输出序列

其中 h(t) 代表通过时间向前移动的子 RNN 的状态,g(t) 代表通过时间向后移动的子 RNN 的状态。因此在每个点 t,输出单元 o(t) 可以受益于输入 h(t) 中关于过去的相关概要以及输入 g(t) 中关于未来的相关概要。
这允许输出单元 o(t) 能够计算同时依赖于过去和未来且对时刻 t 的输入值最敏感的表示,而不必指定 t 周围固定大小的窗口。
0x6:基于编码 - 解码的序列到序列结构
这一小节,我们将讨论RNN如何将一个输入序列映射到不等长的输出序列。这在许多场景中都有应用,如语音识别、机器翻译或问答,其中训练集的输入和输出序列的长度通常不相同。
我们经常将RNN的输入称为“上下文”。我们希望产生此上下文的表示C。这个上下文C可能是一个概括输入序列 X = (x(1) , . . . , x(nx ) ) 的向量或者向量序列,即神经网络的隐层高维度向量。
实际上,输入长度和输出长度不一致的神经网络并不罕见,DNN和CNN中这种情况都非常常见(例如将图像输入得到手写数字输出),实现这一能力的核心思想就是增加 1 个及以上的隐层,对于RNN也是一样的,隐层起到信息压缩和解压缩的承上启下作用。
这种架构称为编码-解码或序列到序列架构。如下图所示:

这个结构实际上是由两个RNN结构拼接组成的。
(1) 编码器(encoder)或读取器(reader)或输入 (input) RNN 处理输入序列。编码器输出上下文C(通常是最终隐藏状态的简单函数),C表示输入序列的语义概要;
(2) 解码器(decoder)或写入器 (writer)或输出 (output) RNN 则以固定长度的向量(即上下文C)为条件产生输出序列 Y = (y(1),...,y(ny))。
在序列到序列的架构中,两个 RNN 共同训练以最大化 logP(y(1),...,y(ny) | x(1),...,x(nx))(训练集中所有 x 和 y 对的损失)。
编码器 RNN 的最后一个状态 hnx 通常被当作输入的表示 C 并作为解码器 RNN 的输入。
0x7:LSTM
LSTM逻辑图如下所示:

LSTM 循环网络除了外部的 RNN 循环外,还具有内部的 “LSTM 细胞’’ 循环(自环),因此 LSTM 不是简单地向输入和循环单元的仿射变换之后施加一个逐元素的非线性。
与普通的循环网络类似,每个单元有相同的输入和输出,但也有更多的参数和控制信息流动的门控单元系统。
最重要的组成部分是状态单元 s(t),与之前讨论的渗漏单元有类似的线性自环。然而,此处自环的权重(或相关联的时间常数)由遗忘门 (forget gate) f(t) 控制。而渗漏单元需要设计者实现手工决定。一个是数据驱动,一个是经验驱动。
遗忘门函数 f(t) 由 sigmoid 单元将权重设置为 0 和 1 之间的值:
其中 x(t) 是当前输入向量,ht 是当前隐藏层向量,ht 包含所有 LSTM 细胞的输出。 bf , Uf , Wf 分别是偏置、输入权重和遗忘门的循环权重。
LSTM 细胞内部状态以如下方式更新: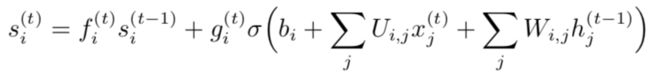
其中 b, U, W 分别是 LSTM 细胞中的偏置、输入权重和遗忘门的循环权重。外部输入门 (external input gate) 单元 g(t) 以类似遗忘门(使用sigmoid获得一个 0 和 1 之
间的值)的方式更新,但有自身的参数:
LSTM 细胞的输出 h(t) 也可以由输出门 (output gate) q(t) 关闭(使用sigmoid单元作为门控):

其中 bo, Uo, Wo 分别是偏置、输入权重和遗忘门的循环权重。
LSTM 网络比简单的循环架构更易于学习长期依赖
笔者思考:LSTM从数学公式上并没有什么特别的地方,这是相比于原始的RNN公式加入了一些额外的函数,使得联合优化过程更复杂了,当然也带来的额外的好处。LSTM的核心思想就是在隐状态的循环传递中插入了一个“门控函数”,该门控函数具备“放行”和“阻断”这两种能力,而具体是否要放行以及放行多少由输入和输出进行BP联合训练。
进一步扩展,我们甚至可以将门控函数改为一个“信号放大函数”,使其成为一个具备新能力的RNN网络,所有的功能背后都是数学公式以及该公式具备的线性和非线性能力。
0x8:GRU(门控循环单元)
GRU 与 LSTM 的主要区别是,单个门控单元同时控制遗忘因子和更新状态单元的决定。更新公式如下:
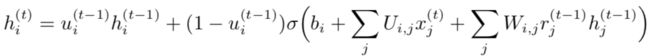
其中 u 代表 ”更新门”,r 表示 “复位门“。它们的值定义如下:
 和
和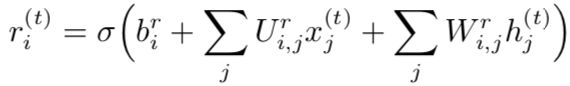
复位和更新门能独立地 ‘‘忽略’’ 状态向量的一部分。
1. 更新门像条件渗漏累积器一样,可以线性门控任意维度,从而选择将它复制(在 sigmoid 的一个极端)或完全由新的 ‘‘目标状态’’ 值(朝向渗漏累积器的收敛方向)替换并完全忽略它(在另一个极端)。 2. 复位门控制当前状态中哪些部分用于计算下一个目标状态,在过去状态和未来状态之间引入了附加的非线性效应。
围绕这一主题可以设计更多的变种。例如复位门(或遗忘门)的输出可以在多个隐藏单元间共享。或者,全局门的乘积(覆盖一整组的单元,例如整一层)和一个局部门(每单元)可用于结合全局控制和局部控制。但不管怎样,读者朋友需要明白的是,这些本质上都是数学公式上的增加和变化,在核心架构上,GRU和我们之前讨论的RNN单元公式是类似的。
5. 循环神经网络概率图结构
从概率模型的角度来看,我们可以将深度神经网络的输出解释为一个概率分布,并且我们通常使用与分布相关联的交叉熵来定义损失。
需要注意的是,是否将上一时间步的某种形式输出作为当前时间步的输入(即是否存在序列依赖),以及取多少步的历史时间步输出作为当前时间步的输入,会对网络模型的性能和效果造成非常大的变化,我们这个小节来尝试讨论下这个话题。
0x1:序列时间步之间输入输出独立
将整个序列 y 的联合分布分解为一系列单步的概率预测是捕获关于整个序列完整联合分布的一种方法。
当我们不把过去时间步的 y 值反馈给下一步作为预测的条件时,那么该有向图模型模型不包含任何从过去 y(i) 到当前 y(t) 的边。在这种情况下,输出 y 与给定的 x 序列是条件独立的。
朴素贝叶斯NB算法中的朴素贝叶斯假设本质上就属于这种情况。
0x2:序列时间步之间有限步(阶)输入输出依赖
许多概率图模型的目标是省略不存在强相互作用的边以实现统计和计算的效率。
例如经典的Markov假设, 即图模型应该只包含从 {y(t−k), . . . , y(t−1)} 到 y(t) 的边(k阶马尔科夫),而不是包含整个过去历史的边。
然而,在一些情况下,我们认为整个过去的输入会对序列的下一个元素有一定影响。当我们认为 y(t) 的分布可能取决于遥远过去 (在某种程度) 的 y(i) 的值,且 无法通过 y(t−1) 捕获 y(i) 的影响时,RNN 将会很有用。
笔者思考:在实际项目中,我们对序列依赖的长度的需求是需要仔细思考的,并不是所有情况下都需要针对超长序列提取模式记忆。例如在webshell检测场景中,我们往往更关注”短程语法句式模式“,因为恶意代码的主题功能往往在5步之内就会完成,我们需要捕获的也就是这些短程的序列模式。
0x3:历史时间步长序列输入输出依赖
RNN 被训练为能够根据之前的历史输入估计下一个序列元素 y(t) 的条件分布,条件概率公式如下:
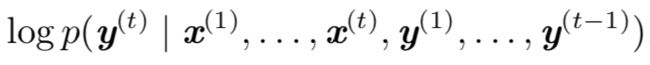
可以看到,RNN遵循的是一种长序列依赖假设。
举一个简单的例子,让我们考虑对标量随机变量序列 Y = {y(1),...,y(τ)} 建模的 RNN,也没有额外的输入 x(实际大多数情况是存在输入 x 的)。在时间步 t 的输入仅仅是时间步 t − 1 的输出:
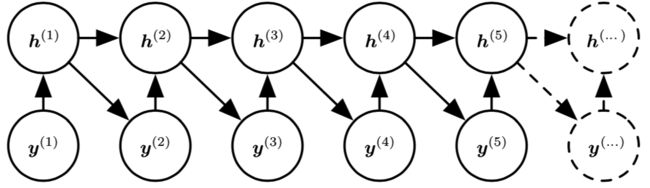
这个例子中的 RNN 定义了关于 y 变量的有向图模型。我们使用链式法则参数化这些观察值的联合分布:

其中当 t = 1 时竖杠右侧显然为空。因此,根据这样一个模型,一组值 {y(1),...,y(τ)} 的负对数似然为:
 ,其中,
,其中,![]()
”该RNN中每一时间步都参考了历史上所有历史时间步的输出“,这句话有点抽象不好理解,为了更好地讨论这句话的概念,我们将计算图展开为完全图:
我们将RNN视为定义一个结构为完全图的图模型,且能够表示任何一对 y 值之间的直接联系。即每一个时间步之间都存在某种联系。这预示着 RNN 能对观测的联合分布提供非常有效的参数,如下图:
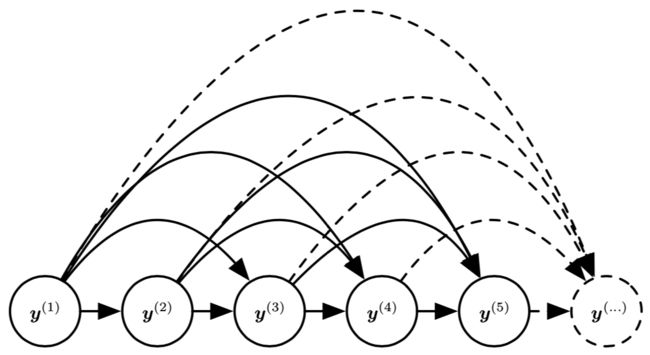
序列 y(1), y(2), . . . , y(t), . . . 的全连接图模型。给定先前的值,每个过去的观察值 y(i) 可 以影响一些 y(t)(t > i) 的条件分布。
当序列中每个元素的输入和参数的数目越来越多,根据此图直接参数化图模型可能是非常低效的。RNN 可以通过高效的参数化(参数共享机制)获得相同的全连接。
但是全连接带来一个严重的问题,参数膨胀。
假设我们用表格表示法来表示离散值上任意的联合分布,即对每个值可能的赋值分配一个单独条目的数组,该条目表示发生该赋值的概率。如果 y 可以取 k 个不同的 值,表格表示法将有 O(kτ ) 个参数。
但是 RNN 由于使用参数共享机制,RNN 的参数数目为 O(1) 且是序列长度的函数。我们可以调节 RNN 的参数数量来控制模型容量,但不用被迫与序列长度成比例。
下式展示了所述 RNN 通过循环应用相同的函数,以及在每个时间步的相同参数 θ,有效地参数化的变量之间的长期联系:
同时在 RNN 图模型中引入状态变量,尽管它是输入的确定性函数,但它有助于我们获得非常高效的参数化。
序列中的每个阶段(对于 h(t) 和 y(t) )使用相同的结构(每个节点具有相同数量的输入),并且可以与其他阶段共享相同的参数。
在图模型中结合 h(t) 节点可以用作过去和未来之间的中间量,从而将它们解耦。遥远过去的变量 y(i) 可以通过其对 h 的影响来影响变量 y(t)。
6. 循环神经网络的梯度计算
循环神经网络中,关于各个参数计算这个损失函数的梯度是计算成本很高的操作。
通过将RNN的计算图展开后可以清楚地看到,梯度计算涉及执行一次前向传播,接着是由右到左的反向传播。运行时间是 O(τ),并且不能通过并行化来降低,因为前向传播图是固有循序的,每个时间步只能一前一后地计算。前向传播中的各个状态必须保存,直到它们反向传播中被再次使用,因此内存代价也是 O(τ)。
应用于展开图且代价为 O(τ) 的反向传播算法称为通过时间反向传播(back-propagation through time, BPTT),隐藏单元之间存在循环的网络非常强大但训练代价也很大。
0x1:举例说明BPTT计算过程
以文章之前讨论的例子为例计算梯度:
计算图的节点包括参数 U, V, W, b 和 c,以及以 t 为索引的节点序列 x(t), h(t), o(t) 和 L(t)。
对于每一个节点 N,我们需要基于 N 后面的节点的梯度,递归地计算梯度 ∇NL。我们从紧接着最终损失的节点开始往回递归:

在这个导数中,我们假设输出 o(t) 作为 softmax 函数的参数,我们可以从 softmax函数可以获得关于输出概率的向量 yˆ。我们也假设损失是迄今为止给定了输入后的真实目标 y(t) 的负对数似然。对于所有 i, t,关于时间步 t 输出的梯度 ∇o(t) L 如下:

我们从序列的末尾开始,反向进行计算。在最后的时间步 τ, h(τ) 只有 o(τ) 作为后续节点,因此这个梯度很简单:
![]()
然后,我们可以从时刻 t = τ − 1 到 t = 1 反向迭代,通过时间反向传播梯度,注意h(t)(t < τ) 同时具有 o(t) 和 h(t+1) 两个后续节点。因此,它的梯度由下式计算:
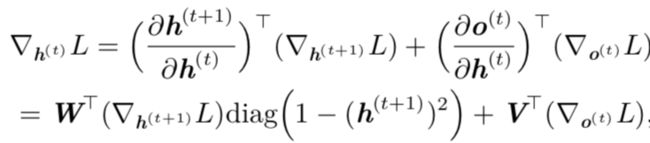
其中 diag 1−(h(t+1))2 表示包含元素 1−(h(t+1))2 的对角矩阵。这是关于时刻 t+1 与隐藏单元 i 关联的双曲正切的Jacobian。
一旦获得了计算图内部节点的梯度,我们就可以得到关于参数节点的梯度。
因为参数在许多时间步共享,我们必须在表示这些变量的微积分操作时谨慎对待。我们希望使用 bprop 方法计算计算图中单一边对梯度的贡献。然而微积分中的 ∇Wf 算子,计算 W 对于 f 的贡献时将计算图中的所有边都考虑进去了。为了消除这种歧义,我们定义只在 t 时刻使用的虚拟变量 W(t) 作为 W 的副本。然后,我们可以使用 ∇W(t) 表示权重在时间步 t 对梯度的贡献。
使用这个表示,计算节点内部参数的梯度可以由下式给出:

因为计算图中定义的损失的任何参数都不是训练数据 x(t) 的父节点,所以我们不需要计算关于它的梯度。
7. 循环神经网络的具体应用
0x1:基于RNN+LSTM的模型自动编写古诗
1. 语料数据
一共四万多首古诗,每行一首诗。
2. 样本预处理
这里我们采用one-hot的形式,基于当前的诗句文件统计出一个字典,这样诗句中的每个字都能用向量来表示。当然,也可以采用emberding方式进行词向量嵌入。
# *-* coding:utf-8 *-* puncs = [']', '[', '(', ')', '{', '}', ':', '《', '》'] def preprocess_file(Config): # 语料文本内容 files_content = '' with open(Config.poetry_file, 'r', encoding='utf-8') as f: for line in f: # 每行的末尾加上"]"符号代表一首诗结束 for char in puncs: line = line.replace(char, "") files_content += line.strip() + "]" # 统计整个预料的词频 words = sorted(list(files_content)) words.remove(']') counted_words = {} for word in words: if word in counted_words: counted_words[word] += 1 else: counted_words[word] = 1 # 去掉低频的字 erase = [] for key in counted_words: if counted_words[key] <= 2: erase.append(key) for key in erase: del counted_words[key] del counted_words[']'] wordPairs = sorted(counted_words.items(), key=lambda x: -x[1]) words, _ = zip(*wordPairs) # word到id的映射 word2num = dict((c, i + 1) for i, c in enumerate(words)) num2word = dict((i, c) for i, c in enumerate(words)) word2numF = lambda x: word2num.get(x, 0) return word2numF, num2word, words, files_content
3. 生成序列数据
RNN是序列到序列的有监督模型,因此我们需要定义每个时间步的输入x,以及每个时间步的输出目标值y。
我们给模型学习的方法是,给定前六个字,生成第七个字,所以在后面生成训练数据的时候,会以6的跨度,1的步长截取文字,生成语料。
比如“我要吃香蕉”,现在以3的跨度生成训练数据就是("我要吃", “香”),("要吃香", "蕉")。跨度为6的句子中,前后每个字都是有关联的。如果出现了]符号,说明]符号之前的语句和之后的语句是两首诗里面的内容,两首诗之间是没有关联关系的,所以我们后面会舍弃掉包含]符号的训练数据。
def data_generator(self): '''生成器生成数据''' i = 0 while 1: x = self.files_content[i: i + self.config.max_len] # max_len跨度作为x y = self.files_content[i + self.config.max_len] # max_len+1 的那个跟随词作为y puncs = [']', '[', '(', ')', '{', '}', ':', '《', '》', ':'] if len([j for j in puncs if j in x]) != 0: # x中出现诗句停止符,丢弃该x i += 1 continue if len([j for j in puncs if j in y]) != 0: # y刚好是诗句停止符,丢弃该y i += 1 continue y_vec = np.zeros( shape=(1, len(self.words)), dtype=np.bool ) y_vec[0, self.word2numF(y)] = 1.0 # y是one-hot编码,对应出现的那个词为true,其他为false x_vec = np.zeros( shape=(1, self.config.max_len), dtype=np.int32 ) for t, char in enumerate(x): x_vec[0, t] = self.word2numF(char) yield x_vec, y_vec i += 1
x表示输入,y表示输出,输入就是前六个字,输出即为第七个字。再将文字转换成向量的形式。
4. 构建模型
def build_model(self): '''建立模型''' # 输入的dimension input_tensor = Input(shape=(self.config.max_len,)) embedd = Embedding(len(self.num2word) + 2, 300, input_length=self.config.max_len)(input_tensor) lstm = Bidirectional(GRU(128, return_sequences=True))(embedd) # dropout = Dropout(0.6)(lstm) # lstm = LSTM(256)(dropout) # dropout = Dropout(0.6)(lstm) flatten = Flatten()(lstm) dense = Dense(len(self.words), activation='softmax')(flatten) self.model = Model(inputs=input_tensor, outputs=dense) optimizer = Adam(lr=self.config.learning_rate) self.model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
双向lstm之后用flattern和DNN进行压平和整合,最后softmax得到单个向量的输出。
5. 训练模型
def train(self): '''训练模型''' number_of_epoch = len(self.words) // self.config.batch_size if not self.model: self.build_model() self.model.fit_generator( generator=self.data_generator(), verbose=True, steps_per_epoch=self.config.batch_size, epochs=number_of_epoch, callbacks=[ keras.callbacks.ModelCheckpoint(self.config.weight_file, save_weights_only=False), LambdaCallback(on_epoch_end=self.generate_sample_result) ] )
6. 每轮epoch训练结果,进行一次成果展示
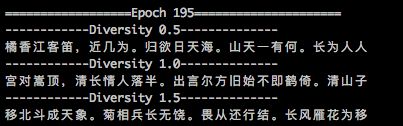
def generate_sample_result(self, epoch, logs): '''训练过程中,每个epoch打印出当前的学习情况''' # if epoch % 5 != 0: # return print("\n==================Epoch {}=====================".format(epoch)) for diversity in [0.5, 1.0, 1.5]: print("------------Diversity {}--------------".format(diversity)) start_index = random.randint(0, len(self.files_content) - self.config.max_len - 1) generated = '' sentence = self.files_content[start_index: start_index + self.config.max_len] # 随机截取一段6词序列作为待预测x generated += sentence for i in range(20): # 循环20次,即生成一句20个词的诗句 x_pred = np.zeros((1, self.config.max_len)) for t, char in enumerate(sentence[-6:]): x_pred[0, t] = self.word2numF(char) preds = self.model.predict(x_pred, verbose=0)[0] # 得到y预测结果 print "preds: ", preds next_index = self.sample(preds, diversity) # 从y中选择概率最大的词编码 next_char = self.num2word[next_index] # 翻译回可读汉字 generated += next_char sentence = sentence + next_char print(sentence)
下图展示了训练初期和训练一段时间之后,RNN的诗句生成效果

训练一段时间后:
Relevant Link:
https://www.ioiogoo.cn/2018/02/01/%E7%94%A8keras%E5%AE%9E%E7%8E%B0rnnlstm%E7%9A%84%E6%A8%A1%E5%9E%8B%E8%87%AA%E5%8A%A8%E7%BC%96%E5%86%99%E5%8F%A4%E8%AF%97/ https://github.com/LittleHann/poetry_generator_Keras
0x2:基于LSTM生成城市名称
RNN具备记忆性,在经过大量训练后可以学习到时序数据的潜在规律,并且可以使用这种规律随机生成新的序列。
1. 如何给RNN输入训练样本
RNN可以学习到数据中的时序规律,但是作为模型设计者,我们需要明确地定义:该样本集中时序规律的形式是什么。
例如笔者在项目中遇到的一些典型场景:
1. 你有一段时序向量数据,并且拥有对这个时序向量数据的一个 0/1 label,即二分类问题,这在安全攻防场景中很常见; 2. 你有一个预料库,该语料库中包含了各种句子。你希望让RNN从中学习到隐藏的”句式、语法模式“。我们知道,语言对话是由词/句/短语/段落组成的,我么可以采取”滑动窗口“的方式,逐段地将整个句子分成多个【X(可能长度为7), Y(可能长度为1)】的训练样本,通过让RNN学习 X序列 和紧随其后的 Y 字符的序列特征,等效地让RNN学会语料库中的”句式、语法模式“; 3. 同理,基于图像生成标注的道理也是类似的(同2);
2. 数据集
Abbeville
Abbotsford
Abbott
Abbottsburg
Abbottstown
Abbyville
Abell
Abercrombie
Aberdeen
Aberfoil
Abernant
Abernathy
Abeytas
Abie
Abilene
Abingdon
Abington
Abiquiu
Abita Springs
Abo
Aboite
Abraham
Abram
Abrams
Absarokee
Absecon
Academy
Accokeek
Accomac
Accord
Ace
Aceitunas
Acequia
Achille
Achilles
Ackerly
Ackerman
Ackley
Ackworth
Acme
Acomita Lake
Acra
Acree
Acton
Acworth
Acy
Ada
Adair
Adair Village
Adairsville
Adairville
Adams
Adams Center
Adams City
Adamstown
Adamsville
Adario
Addicks
Addie
Addieville
Addington
Addis
Addison
Addy
Addyston
Adel
Adelaide
Adelanto
Adelino
Adell
Adelphi
Adelphia
Aden
Adena
Adgateville
Adin
Adjuntas
Admire
Adna
Adona
Adrian
Advance
Adwolf
Ady
Aetna
Affton
Afton
Agar
Agate
Agate Beach
Agawam
Agency
Agnes
Agness
Agnew
Agnos
Agoura
Agra
Agricola
Agua Dulce
3. 训练代码
from __future__ import absolute_import, division import os from six import moves import ssl import tflearn from tflearn.data_utils import * path = "../data/US_Cities.txt" maxlen = 20 file_lines = open(path, "r").read() X, Y, char_idx = string_to_semi_redundant_sequences(file_lines, seq_maxlen=maxlen, redun_step=3) print "X[0]", X[0] print "len(X[0])", len(X[0]) print "Y[0]", Y[0] print "char_idx", char_idx g = tflearn.input_data(shape=[None, maxlen, len(char_idx)]) g = tflearn.lstm(g, 512, return_seq=True) g = tflearn.dropout(g, 0.5) g = tflearn.lstm(g, 512) g = tflearn.dropout(g, 0.5) g = tflearn.fully_connected(g, len(char_idx), activation='softmax') g = tflearn.regression(g, optimizer='adam', loss='categorical_crossentropy', learning_rate=0.001) m = tflearn.SequenceGenerator(g, dictionary=char_idx, seq_maxlen=maxlen, clip_gradients=5.0, checkpoint_path='model_us_cities') for i in range(40): seed = random_sequence_from_string(file_lines, maxlen) m.fit(X, Y, validation_set=0.1, batch_size=128, n_epoch=1, run_id='us_cities') print("-- TESTING...") print("-- Test with temperature of 1.2 --") print(m.generate(30, temperature=1.2, seq_seed=seed)) print("-- Test with temperature of 1.0 --") print(m.generate(30, temperature=1.0, seq_seed=seed)) print("-- Test with temperature of 0.5 --") print(m.generate(30, temperature=0.5, seq_seed=seed))
4. 实验结果

0x3:基于LSTM生成JSP WEBSHELL样本
1. 样本集
我们收集了131个大小在4096bytes内的JSP webshell文件,这批样本作为训练语料库。
需要特别注意的一点是,每个文件之间理论上应该是一个独立的样本集,最合理的做法是单独从每个文件中以ngram方式提取序列。
我们这里为了简单起见,把所有文件concat到一个整体的字符串中,进行向量化,读者朋友在实际项目中要注意这点。
2. webshell词法模式提取原理
采集滑动窗口进行词模式提取,窗口越小,提取到的词模式特定空间就越大,描述能力就越强,相对的,训练难度也越大,举例说明:
php
eval($_POST['op']);
?>
采用step_size = 2的滑动窗口进行词模式提取:
EOF< -> ?
p
?p -> h
...
ev -> a
va -> l
al -> (
...
$_ -> P
..
?> -> EOF
3. 生成(预测)过程
RNN是一种sequence to sequence的神经网络,因此我们需要给模型提供一个种子seed字符,作为启动字符,选择这个字符的原则也很简单,选择对应编程语言开头的第一个字母。
这里我们简述过程
1. step_1: 输入 START<,prediect后进行softmax得到"?" 2. step_2: 在上一步的基础上,输入"",prediect后进行softmax得到"换行"或者"空格" 3. ... 4. 循环到直接网络输出EOF或者达到开发者设定的filesize 5. 最终得到的序列就是一个目标webshell序列
4. 实验代码
from __future__ import absolute_import, division import os from six import moves import ssl import tflearn from tflearn.data_utils import * DataDir = "../data/jsp_hash" maxlen = 20 shelllen = 4096 step_size = 2 file_lines = "" rootDir = DataDir for file in os.listdir(rootDir): if file == '.DS_Store': continue print file path = os.path.join(rootDir, file) file_content = open(path, "r").read() file_lines += file_content X, Y, char_idx = string_to_semi_redundant_sequences(file_lines, seq_maxlen=maxlen, redun_step=step_size) print "X[0]", X[0] print "len(X[0])", len(X[0]) print "Y[0]", Y[0] print "char_idx", char_idx g = tflearn.input_data(shape=[None, maxlen, len(char_idx)]) g = tflearn.lstm(g, 512, return_seq=True) g = tflearn.dropout(g, 0.5) g = tflearn.lstm(g, 512) g = tflearn.dropout(g, 0.5) g = tflearn.fully_connected(g, len(char_idx), activation='softmax') g = tflearn.regression(g, optimizer='adam', loss='categorical_crossentropy', learning_rate=0.001) m = tflearn.SequenceGenerator(g, dictionary=char_idx, seq_maxlen=maxlen, clip_gradients=5.0, checkpoint_path='model_us_cities') for i in range(40): seed = random_sequence_from_string(file_lines, maxlen) m.fit(X, Y, validation_set=0.2, batch_size=128, n_epoch=5, run_id='webshell generate') print("-- GENERATING...") print("-- Test with temperature of 1.2 --") print(m.generate(shelllen, temperature=1.2, seq_seed=seed)) print("-- Test with temperature of 1.0 --") print(m.generate(shelllen, temperature=1.0, seq_seed=seed)) print("-- Test with temperature of 0.5 --") print(m.generate(shelllen, temperature=0.5, seq_seed=seed))
3. 实验结果

0x4:GENERATING IMAGE DESCRIPTIONS
Together with convolutional Neural Networks, RNNs have been used as part of a model to generate descriptions for unlabeled images. It’s quite amazing how well this seems to work. The combined model even aligns the generated words with features found in the images.