1. ADFA-LD数据集简介
ADFA-LD数据集是澳大利亚国防学院对外发布的一套主机级入侵检测数据集合,包括Linux和Windows,是一个包含了入侵事件的系统调用syscall序列的数据集(以单个进程,一段时间窗口内的systemcall api为一组)
ADFA-LD数据已经将各类系统调用完成了特征化,并针对攻击类型进行了标注,各种攻击类型见下表
| 攻击类型 | 数据量 | 标注类型 |
| Trainning | 833 | normal |
| Validation | 4373 | normal |
| Hydra-FTP | 162 | attack |
| Hydra-SSH | 148 | attack |
| Adduser | 91 | attack |
| Java-Meterpreter | 125 | attack |
| Meterpreter | 75 | attack |
| Webshell | 118 | attack |
ADFA-LD数据集的每个数据文件都独立记录了一段时间内的系统调用顺序,每个系统调用都用数字编号(定义在unisted.h中)
/* * This file contains the system call numbers, based on the * layout of the x86-64 architecture, which embeds the * pointer to the syscall in the table. * * As a basic principle, no duplication of functionality * should be added, e.g. we don't use lseek when llseek * is present. New architectures should use this file * and implement the less feature-full calls in user space. */ #ifndef __SYSCALL #define __SYSCALL(x, y) #endif #if __BITS_PER_LONG == 32 || defined(__SYSCALL_COMPAT) #define __SC_3264(_nr, _32, _64) __SYSCALL(_nr, _32) #else #define __SC_3264(_nr, _32, _64) __SYSCALL(_nr, _64) #endif #define __NR_io_setup 0 __SYSCALL(__NR_io_setup, sys_io_setup) #define __NR_io_destroy 1 __SYSCALL(__NR_io_destroy, sys_io_destroy) #define __NR_io_submit 2 __SYSCALL(__NR_io_submit, sys_io_submit) #define __NR_io_cancel 3 __SYSCALL(__NR_io_cancel, sys_io_cancel) #define __NR_io_getevents 4 __SYSCALL(__NR_io_getevents, sys_io_getevents) /* fs/xattr.c */ #define __NR_setxattr 5 __SYSCALL(__NR_setxattr, sys_setxattr) #define __NR_lsetxattr 6 __SYSCALL(__NR_lsetxattr, sys_lsetxattr) #define __NR_fsetxattr 7 __SYSCALL(__NR_fsetxattr, sys_fsetxattr) #define __NR_getxattr 8 __SYSCALL(__NR_getxattr, sys_getxattr) #define __NR_lgetxattr 9 __SYSCALL(__NR_lgetxattr, sys_lgetxattr)
0x1: 包含的攻击类型
1. Hydra-FTP:FTP暴力破解攻击 2. Hydra-SSH:SSH暴力破解攻击 3. Adduser 4. Meterpreter:the uploads of Java and Linux executable Meterpreter payloads for the remote compromise of a target host 5. Webshell:privilege escalation using C100 webshell
0x2:数据集特征分析
在进行特征工程之前,我们先尝试对训练数据集进行一个简要的分析,尝试从中发现一些规律辅助我们进行后续的特征工程
1. syscall序列长度
序列长度体现了该进程从开始运行到最后完成攻击/被攻击总共调用的syscall次数,通过可视化不同类别label数据集的Trace length的概率密度曲线(PDF)
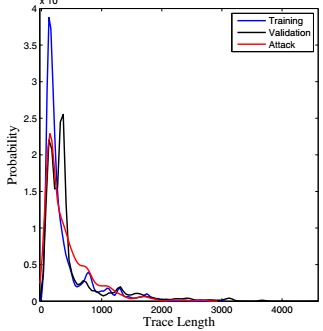
可以看到,Trace length大致分布在【100:500】区间,但是我们并没有找到明显的分界线/面来区分这些不同的label样本,这说明Trace length可能不会是一个好的特征
2. 从词模型角度看样本集中不同类别label的数据中是否存在公共模式
这一步本质上是在考虑样本数据集是否线性可分,即样本中包含的规律真值是否足够明显,只有数据集本身是线性可分的,才有可能通过算法建模分析
样本集中的syacall本质上就是一个词序列,我们将其2-gram处理,统计词频直方图

我们发现,在Adduser类别中,“168 168”、“168 265”这2个2-gram序列出现的频次最高,而在Webshell类别中,“5 5”、“5 3”这2个2-gram出现的频次最高。这从一定程度上表明两类数据集在2-gram词频这个层面上是线性可分的
Relevant Link:
Evaluating host-based anomaly detection system:A preliminary analysis of ADFA-LD https://www.unsw.adfa.edu.au/australian-centre-for-cyber-security/cybersecurity/ADFA-IDS-Datasets/
1. 如何进行特征工程
由syscall api组成的token set本质上是由词组成的词序列,我们可以通过词模型的方式对样本进行特征工程
0x1:词袋模型 - 基本单元是单个词(即1-gram),以词频作为向量化的值空间,
Bag-of-words model (BoW model) 最早出现在自然语言处理(Natural Language Processing)和信息检索(Information Retrieval)领域.。该模型忽略掉文本的语法和语序等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的。BoW使用一组无序的单词(words)来表达一段文字或一个文档
首先给出两个简单的文本文档如下:
John likes to watch movies. Mary likes too.
John also likes to watch football games.
基于上述两个文档中出现的单词,构建如下一个词典 (dictionary):
{"John": 1, "likes": 2,"to": 3, "watch": 4, "movies": 5,"also": 6, "football": 7, "games": 8,"Mary": 9, "too": 10}
上面的词典中包含10个单词, 每个单词有唯一的索引(注意索引的排序先后无意义), 那么每个文本我们可以使用一个10维的向量来表示。如下:
[1, 2, 1, 1, 1, 0, 0, 0, 1, 1] [1, 1,1, 1, 0, 1, 1, 1, 0, 0]
该向量与原来文本中单词出现的顺序没有关系,而是词典中每个单词(无论该单词是否在该样本中出现)在文本中出现的频率
scikit-learn中使用CountVectorizer()实现词袋特征的提取,CountVectorizer在一个类中实现了标记和计数:
# -*- coding:utf-8 -*- from sklearn.feature_extraction.text import CountVectorizer if __name__ == '__main__': vectorizer = CountVectorizer() corpus = [ 'This is the first document.', 'This is the second second document.', 'And the third one.', 'Is this the first document?', ] X = vectorizer.fit_transform(corpus) # 显示根据语料训练出的词袋 print vectorizer.vocabulary_ # 显示原始语料经过词袋编码后的向量矩阵 print X.toarray()
稀疏性
大多数文档通常只会使用语料库中所有词的一个子集,因而产生的矩阵将有许多特征值是0(通常99%以上都是0)。例如,一组10,000个短文本(比如email)会使用100,000的词汇总量,而每个文档会使用100到1,000个唯一的词。
为了能够在内存中存储这个矩阵,同时也提供矩阵/向量代数运算的速度,sklearn通常会使用稀疏表来存储和运算特征
训练集覆盖度问题
词袋模型的vocab词表在训练期间就确定下来了,因此,在训练语料中没有出现的词在后续调用转化方法时将被完全忽略:
vectorizer.transform(['Something completely new.']).toarray() array([[0, 0, 0, 0, 0, 0, 0, 0, 0]]...)
这会在一定程度上影响词袋模型的泛化能力
0x2:TF-IDF term weighting - 在词频的基础上加上了权重的概念
在大文本语料中,一些词语出现非常多(比如:英语中的“the”, “a”, “is” ),它们携带着很少量的信息量。我们不能在分类器中直接使用这些词的频数,这会降低那些我们感兴趣但是频数很小的term。我们需要对feature的count频数做进一步re-weight成浮点数,以方便分类器的使用,这一步通过tf-idf转换来完成。


如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。

可以看到,词的在单个样本里的频数和在整体语料库中的频数互相调和,动态决定了改词的权重
scikit-learn中使用TfidfTransformer()实现了TF-IDF逆文档特征提取
# -*- coding:utf-8 -*- from sklearn.feature_extraction.text import TfidfVectorizer if __name__ == '__main__': vectorizer = TfidfVectorizer(min_df=1) corpus = [ 'This is the first document.', 'This is the second second document.', 'And the third one.', 'Is this the first document?', ] tfidf = vectorizer.fit_transform(corpus) # 显示原始语料经过TF-IDF编码后的向量矩阵 print tfidf.toarray() ''' [[ 0. 0.43877674 0.54197657 0.43877674 0. 0. 0.35872874 0. 0.43877674] [ 0. 0.27230147 0. 0.27230147 0. 0.85322574 0.22262429 0. 0.27230147] [ 0.55280532 0. 0. 0. 0.55280532 0. 0.28847675 0.55280532 0. ] [ 0. 0.43877674 0.54197657 0.43877674 0. 0. 0.35872874 0. 0.43877674]] '''
TF-IDF和词袋模型一样,将原始样本抽象成了一个定长的向量,所不同的在词袋中的词频被替换成了TF-IDF权重
0x3:N-Gram模型 - 在词频模型基础上考虑多词上下文结构
一组unigrams(即词袋)无法捕捉短语和多词(multi-word)表达,我们可以用n-gram来对词进行窗口化组合,在n-gram的基础上进行词频向量化
CountVectorizer类中同样实现了n-gram,或者说n-gram只是词频模型的一个参数选项
# -*- coding:utf-8 -*- from sklearn.feature_extraction.text import CountVectorizer if __name__ == '__main__': vectorizer = CountVectorizer(min_df=1, analyzer='word', ngram_range=(2, 3)) corpus = [ 'This is the first document.', 'This is the second second document.', 'And the third one.', 'Is this the first document?', ] tfidf = vectorizer.fit_transform(corpus) # n-gram词表 print vectorizer.get_feature_names() # 显示原始语料经过n-gram编码后的向量矩阵 print tfidf.toarray() ''' [u'and the', u'and the third', u'first document', u'is the', u'is the first', u'is the second', u'is this', u'is this the', u'second document', u'second second', u'second second document', u'the first', u'the first document', u'the second', u'the second second', u'the third', u'the third one', u'third one', u'this is', u'this is the', u'this the', u'this the first'] [[0 0 1 1 1 0 0 0 0 0 0 1 1 0 0 0 0 0 1 1 0 0] [0 0 0 1 0 1 0 0 1 1 1 0 0 1 1 0 0 0 1 1 0 0] [1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0] [0 0 1 0 0 0 1 1 0 0 0 1 1 0 0 0 0 0 0 0 1 1]] '''
0x4:Word2Vec词向量嵌入模型 - 不考虑词频而是从词之间相似性在高维空间上的距离层面抽取特征
word2vec的训练过程是在训练一个浅层神经网络,将训练集中的每个词都映射到一个指定维度的向量空间中
# -*- coding:utf-8 -*- import warnings warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim') import gensim import os if __name__ == '__main__': modelpath = "./word2vec.test.txt" if os.path.isfile(modelpath): # 导入模型 print "load modeling..." model = gensim.models.Word2Vec.load(modelpath) else: # 用LineSentence把词序列转为所需要的格式 corpus = [ ['This', 'is', 'the', 'first', 'document.'], ['This', 'is', 'the', 'second', 'second', 'document.'], ['And', 'the', 'third', 'one.'], ['Is', 'this', 'the', 'first', 'document?'] ] # 将词嵌入到一个100维的向量空间中 model = gensim.models.Word2Vec(corpus, min_count=1, size=100) # 保存模型 model.save(modelpath) print model['This'] ''' load modeling... [ 4.21720184e-03 -4.96086199e-03 3.77745135e-03 2.94174161e-03 -1.84197503e-03 -2.94078956e-03 1.41434965e-03 -1.12752395e-03 3.44854128e-03 -1.56023342e-03 2.58653867e-03 2.33289364e-04 3.44703044e-03 -2.01581535e-03 4.42115450e-03 -2.88038654e-03 -2.38809455e-03 -4.50134743e-03 -1.49860769e-03 7.91519240e-04 4.98433039e-03 1.85355416e-03 2.31889612e-03 -1.69523829e-03 -3.30593879e-03 4.40168194e-03 -4.88520879e-03 2.60615419e-03 6.49481721e-04 -2.49359757e-03 -3.32681416e-03 2.01359508e-03 3.97601305e-03 6.56171120e-04 3.81603022e-03 2.93262041e-04 -2.28614034e-03 -2.23138509e-03 -2.07091100e-03 -2.18214374e-03 -1.24846201e-03 -4.72204387e-03 1.10300467e-03 2.74274289e-03 3.69609370e-05 2.28803046e-03 1.93586131e-03 -3.52792139e-03 6.02113956e-04 -4.30466002e-03 -1.68499397e-03 4.44801664e-03 3.73569527e-03 -2.87452945e-03 -4.44274070e-03 1.91680994e-03 3.03726265e-04 -2.60479492e-03 3.86350509e-03 -3.56708956e-03 -4.24962817e-03 -2.64985068e-03 4.89832275e-03 4.93438961e-03 -8.93970719e-04 -4.92232037e-04 -2.22921767e-03 -2.13925354e-03 3.71658040e-04 2.85526551e-03 3.21991998e-03 3.41509795e-03 -4.62498562e-03 -2.23036925e-03 4.81000589e-03 3.47611774e-03 -4.62327013e-03 -2.20024776e-05 4.42962535e-03 2.17637443e-03 1.95589405e-03 3.56489979e-03 2.77884956e-03 -1.01689191e-03 -3.14383302e-03 1.79978073e-04 -4.77676420e-03 4.18598717e-03 -2.46347464e-03 -4.86065960e-03 2.29529128e-03 2.09548216e-06 4.92842309e-03 4.01797617e-04 -4.82031086e-04 1.20579556e-03 2.56112689e-04 -1.17955834e-03 -4.68734046e-03 3.14474717e-04] '''
可以看到,word2vec向量化的基本单位是词,每个词都被映射成了一个指定维度的向量,而所有词组成一个词序列(句子)就成了一个向量矩阵(词个数 x 指定的word2vec嵌入维度)。但是机器学习的算法要求的输入都是一个一维张量,因此,我们还需要进行一次特征处理,即用词向量表对原始语料进行特征编码,编码的方式有很多种,例如
1. 将所有词向量相加,取每个维度的均值作为向量值 2. 在TF-IDF的基础上进行方式1
可以看到,和词袋模型相比,样本语料(一段词序列)进行word2vec emberdding之后的的向量维度是词空间的维度(例如我们本例代码中指定的100维),但是词袋模型编码后的向量维度是词袋的大小,大都数情况下词向量模型编码后的维度小于词袋模型
# -*- coding:utf-8 -*- import warnings warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim') import gensim from collections import Counter, defaultdict from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizer import os import numpy as np class MeanEmbeddingVectorizer(object): def __init__(self, word2vec): self.word2vec = word2vec self.dim = len(word2vec.itervalues().next()) def fit(self): return self # 遍历输入词序列中的每一个词,取其在此项量表中的向量,如果改词不在词向量词表中(即训练集中未出现),则填0 def transform(self, X): return np.array([np.mean([self.word2vec[w] for w in words if w in self.word2vec] or [np.zeros(self.dim)], axis=0) for words in X ]) # and a tf-idf version of the same class TfidfEmbeddingVectorizer(object): def __init__(self, word2vec): self.word2vec = word2vec self.word2weight = None self.dim = len(word2vec.itervalues().next()) def fit(self, X): tfidf = TfidfVectorizer(analyzer=lambda x: x) tfidf.fit(X) # if a word was never seen - it must be at least as infrequent # as any of the known words - so the default idf is the max of # known idf's max_idf = max(tfidf.idf_) self.word2weight = defaultdict( lambda: max_idf, [(w, tfidf.idf_[i]) for w, i in tfidf.vocabulary_.items()]) return self # 在词向量的基础上乘上TF-IDF的词权重 def transform(self, X): return np.array([np.mean([self.word2vec[w] * self.word2weight[w] for w in words if w in self.word2vec] or [np.zeros(self.dim)], axis=0) for words in X ]) corpus = [ ['This', 'is', 'the', 'first', 'document.'], ['This', 'is', 'the', 'second', 'second', 'document.'], ['And', 'the', 'third', 'one.'], ['Is', 'this', 'the', 'first', 'document?'] ] if __name__ == '__main__': modelpath = "./word2vec.test.txt" model = None if os.path.isfile(modelpath): # 导入模型 print "load modeling..." model = gensim.models.Word2Vec.load(modelpath) else: # 将词嵌入到一个100维的向量空间中 model = gensim.models.Word2Vec(corpus, min_count=1, size=100) # 保存模型 model.save(modelpath) print "word emberding vocab: ", model.wv.vocab.keys() # 生成词向量词表 words_vocab = dict() for key in model.wv.vocab.keys(): nums = map(float, model[key]) words_vocab[key] = np.array(nums) meanVectorizer = MeanEmbeddingVectorizer(words_vocab) # fit()可以忽略 # 将训练语料通过词向量表编码成一个行向量(取均值) corpusVecs = meanVectorizer.transform(corpus) for i in range(len(corpus)): print corpus[i] print corpusVecs[i] print "" tfidfVectorizer = TfidfEmbeddingVectorizer(words_vocab) tfidfVectorizer.fit(corpus) # 将训练语料通过词向量表编码成一个行向量(在TF-IDF基础上取均值) corpusVecs = tfidfVectorizer.transform(corpus) for i in range(len(corpus)): print corpus[i] print corpusVecs[i] print "" # print words_vocab ''' load modeling... [ 4.21720184e-03 -4.96086199e-03 3.77745135e-03 2.94174161e-03 -1.84197503e-03 -2.94078956e-03 1.41434965e-03 -1.12752395e-03 3.44854128e-03 -1.56023342e-03 2.58653867e-03 2.33289364e-04 3.44703044e-03 -2.01581535e-03 4.42115450e-03 -2.88038654e-03 -2.38809455e-03 -4.50134743e-03 -1.49860769e-03 7.91519240e-04 4.98433039e-03 1.85355416e-03 2.31889612e-03 -1.69523829e-03 -3.30593879e-03 4.40168194e-03 -4.88520879e-03 2.60615419e-03 6.49481721e-04 -2.49359757e-03 -3.32681416e-03 2.01359508e-03 3.97601305e-03 6.56171120e-04 3.81603022e-03 2.93262041e-04 -2.28614034e-03 -2.23138509e-03 -2.07091100e-03 -2.18214374e-03 -1.24846201e-03 -4.72204387e-03 1.10300467e-03 2.74274289e-03 3.69609370e-05 2.28803046e-03 1.93586131e-03 -3.52792139e-03 6.02113956e-04 -4.30466002e-03 -1.68499397e-03 4.44801664e-03 3.73569527e-03 -2.87452945e-03 -4.44274070e-03 1.91680994e-03 3.03726265e-04 -2.60479492e-03 3.86350509e-03 -3.56708956e-03 -4.24962817e-03 -2.64985068e-03 4.89832275e-03 4.93438961e-03 -8.93970719e-04 -4.92232037e-04 -2.22921767e-03 -2.13925354e-03 3.71658040e-04 2.85526551e-03 3.21991998e-03 3.41509795e-03 -4.62498562e-03 -2.23036925e-03 4.81000589e-03 3.47611774e-03 -4.62327013e-03 -2.20024776e-05 4.42962535e-03 2.17637443e-03 1.95589405e-03 3.56489979e-03 2.77884956e-03 -1.01689191e-03 -3.14383302e-03 1.79978073e-04 -4.77676420e-03 4.18598717e-03 -2.46347464e-03 -4.86065960e-03 2.29529128e-03 2.09548216e-06 4.92842309e-03 4.01797617e-04 -4.82031086e-04 1.20579556e-03 2.56112689e-04 -1.17955834e-03 -4.68734046e-03 3.14474717e-04] '''
值得注意的是:采用均值的方式可以解决待编码的句子的长度不同问题,通过均值化保证了不会应为句子的长度导致向量化后量纲不一致。均值的方式比fix length and padding的方式要合理
0x5:Doc2Vec句向量嵌入模型 - 将一段词序列直接抽象成一个固定长度的行向量
Doc2Vec 或者叫做 paragraph2vec, sentence embeddings,是一种非监督式算法,可以获得 sentences/paragraphs/documents 的向量表达,是 word2vec 的拓展。
学出来的向量可以通过计算距离来找 sentences/paragraphs/documents 之间的相似性,或者进一步可以给文档打标签
# -*- coding:utf-8 -*- import warnings warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim') import gensim gensimLabeledSentence = gensim.models.doc2vec.LabeledSentence import os # 用文档集合来训练模型 class LabeledLineSentence(object): def __init__(self, doc_list, labels_list): self.labels_list = labels_list self.doc_list = doc_list def __iter__(self): for idx, doc in enumerate(self.doc_list): # 在 gensim 中模型是以单词为单位训练的,所以不管是句子还是文档都分解成单词 yield gensimLabeledSentence(words=doc.split(), tags=[self.labels_list[idx]]) corpus = [ 'This is the first document.This is the first document.This is the first document.This is the first document.This is the first document.', 'This is the second second document.This is the second second document.This is the second second document.This is the second second document.', 'And the third one.And the third one.And the third one.And the third one.And the third one.', 'Is this the first document?Is this the first document?Is this the first document?Is this the first document?Is this the first document?', 'This is the first document.This is the first document.This is the first document.This is the first document.This is the first document.', 'This is the second second document.This is the second second document.This is the second second document.This is the second second document.', 'And the third one.And the third one.And the third one.And the third one.And the third one.', 'Is this the first document?Is this the first document?Is this the first document?Is this the first document?Is this the first document?', 'This is the first document.This is the first document.This is the first document.This is the first document.This is the first document.', 'This is the second second document.This is the second second document.This is the second second document.This is the second second document.', 'And the third one.And the third one.And the third one.And the third one.And the third one.', 'Is this the first document?Is this the first document?Is this the first document?Is this the first document?Is this the first document?' ] corpus_label = [ 'normal', 'normal', 'normal', 'bad', 'normal', 'normal', 'normal', 'bad', 'normal', 'normal', 'normal', 'bad' ] if __name__ == '__main__': modelpath = "./doc2vec.test.txt" model = None if os.path.isfile(modelpath): # 导入模型 print "load modeling..." model = gensim.models.Doc2Vec.load(modelpath) # 测试模型 print model['normal'] else: # 载入样本集 it = LabeledLineSentence(corpus, corpus_label) # 训练 Doc2Vec,并保存模型 model = gensim.models.Doc2Vec(size=300, window=10, min_count=5, workers=11, alpha=0.025, min_alpha=0.025) model.build_vocab(it) for epoch in range(10): model.train(it, total_examples=model.corpus_count, epochs=model.iter) model.alpha -= 0.002 # decrease the learning rate model.min_alpha = model.alpha # fix the learning rate, no deca model.train(it, total_examples=model.corpus_count, epochs=model.iter) model.save(modelpath)
Relevant Link:
http://scikit-learn.org/stable/modules/feature_extraction.html http://blog.csdn.net/u010213393/article/details/40987945 http://www.ruanyifeng.com/blog/2013/03/tf-idf.html http://d0evi1.com/sklearn/feature_extraction/ http://scikit-learn.org/stable/modules/feature_extraction.html http://blog.csdn.net/sinsa110/article/details/76855428 http://cloga.info/2014/01/19/sklearn_text_feature_extraction http://blog.csdn.net/jerr__y/article/details/52967351 http://www.52nlp.cn/中英文维基百科语料上的word2vec实验 http://nadbordrozd.github.io/blog/2016/05/20/text-classification-with-word2vec/ https://github.com/nadbordrozd/blog_stuff/blob/master/classification_w2v/benchmarking.ipynb https://rare-technologies.com/doc2vec-tutorial/ http://www.jianshu.com/p/854a59b93e09 http://cs.stanford.edu/~quocle/paragraph_vector.pdf http://blog.csdn.net/lenbow/article/details/52120230
2. 基于KNN(K-Nearest Neighbor K近邻) 检测Webshell
0x1:基于词袋模型特征
# -*- coding:utf-8 -*- import re from sklearn.feature_extraction.text import CountVectorizer from sklearn.model_selection import cross_val_score import os import numpy as np from sklearn.neighbors import KNeighborsClassifier def load_one_flle(filename): x = [] with open(filename) as f: line = f.readline() line = line.strip('\n') return line def load_adfa_training_files(rootdir): x = [] y = [] list = os.listdir(rootdir) for i in range(0, len(list)): path = os.path.join(rootdir, list[i]) if os.path.isfile(path): x.append(load_one_flle(path)) y.append(0) return x, y def dirlist(path, allfile): filelist = os.listdir(path) for filename in filelist: filepath = os.path.join(path, filename) if os.path.isdir(filepath): dirlist(filepath, allfile) else: allfile.append(filepath) return allfile def load_adfa_webshell_files(rootdir): x = [] y = [] allfile=dirlist(rootdir,[]) for file in allfile: if re.match(r"\.\./data/ADFA-LD/Attack_Data_Master/Web_Shell_\d+\\UAD-W*", file): x.append(load_one_flle(file)) y.append(1) return x, y if __name__ == '__main__': x1, y1 = load_adfa_training_files("../data/ADFA-LD/Training_Data_Master/") # 训练集(normal) x2, y2 = load_adfa_webshell_files("../data/ADFA-LD/Attack_Data_Master/") # 训练集(attack) x3, y3 = load_adfa_training_files("../data/ADFA-LD/Validation_Data_Master/") # 验证集(normal) # 训练集黑白样本混合 x_train = x1 + x2 y_train = y1 + y2 x_validate = x3 + x2 y_validate = y3 + y2 # 词袋模型,仅统计单个词出现的频数 vectorizer = CountVectorizer(min_df=1) vecmodel = vectorizer.fit(x_train) # 按照训练的词表训练vocab词汇表 x_train = vecmodel.transform(x_train).toarray() # 生成训练集词频向量 x_validate = vecmodel.transform(x_validate).toarray() # 按照同样的标准生成验证机词频向量 # 根据训练集生成KNN模型 clf = KNeighborsClassifier(n_neighbors=4).fit(x_train, y_train) scores = cross_val_score(clf, x_train, y_train, n_jobs=-1, cv=10) # 反映KNN模型训练拟合的程度 print "Training accurate: " print scores print np.mean(scores) # Make predictions using the validate set # print x_train.shape # print x_validate.shape y_pre = clf.predict(x_validate) print "Predict result: ", y_pre # 预测的准确度 print "Prediction accurate: %2f" % np.mean(y_pre == y_validate)

对验证集能到达93的准确度
0x2:基于TF-IDF模型特征
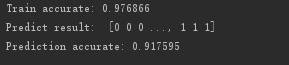
# -*- coding:utf-8 -*- import re from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import cross_val_score import os import numpy as np from sklearn.neighbors import KNeighborsClassifier def load_one_flle(filename): x = [] with open(filename) as f: line = f.readline() line = line.strip('\n') return line def load_adfa_training_files(rootdir): x = [] y = [] list = os.listdir(rootdir) for i in range(0, len(list)): path = os.path.join(rootdir, list[i]) if os.path.isfile(path): x.append(load_one_flle(path)) y.append(0) return x, y def dirlist(path, allfile): filelist = os.listdir(path) for filename in filelist: filepath = os.path.join(path, filename) if os.path.isdir(filepath): dirlist(filepath, allfile) else: allfile.append(filepath) return allfile def load_adfa_webshell_files(rootdir): x = [] y = [] allfile = dirlist(rootdir, []) for file in allfile: if re.match(r"\.\./data/ADFA-LD/Attack_Data_Master/Web_Shell_\d+\\UAD-W*", file): x.append(load_one_flle(file)) y.append(1) return x, y if __name__ == '__main__': x1, y1 = load_adfa_training_files("../data/ADFA-LD/Training_Data_Master/") # 训练集(normal) x2, y2 = load_adfa_webshell_files("../data/ADFA-LD/Attack_Data_Master/") # 训练集(attack) x3, y3 = load_adfa_training_files("../data/ADFA-LD/Validation_Data_Master/") # 验证集(normal) # 训练集黑白样本混合 x_train = x1 + x2 y_train = y1 + y2 x_validate = x3 + x2 y_validate = y3 + y2 # TF-IDF模型 vectorizer = TfidfVectorizer(min_df=1) vecmodel = vectorizer.fit(x_train) # 按照训练集训练vocab词汇表 print "vocabulary_: " print vecmodel.vocabulary_ x_train = vecmodel.transform(x_train).toarray() x_validate = vecmodel.transform(x_validate).toarray() print "x_train[0]: ", x_train[0] print "x_validate[0]: ", x_validate[0] # 根据训练集生成KNN模型 clf = KNeighborsClassifier(n_neighbors=4).fit(x_train, y_train) # 反映KNN模型训练拟合的程度 y_train_pre = clf.predict(x_train) print "Train result: ", y_train_pre print "Train accurate: %2f" % np.mean(y_train_pre == y_train) # Make predictions using the validate set # print x_train.shape # print x_validate.shape y_valid_pre = clf.predict(x_validate) print "Predict result: ", y_valid_pre # 预测的准确度 print "Prediction accurate: %2f" % np.mean(y_valid_pre == y_validate)
0x3:基于N-gram模型特征
# -*- coding:utf-8 -*- import re from sklearn.feature_extraction.text import CountVectorizer from sklearn.model_selection import cross_val_score import os import numpy as np from sklearn.neighbors import KNeighborsClassifier def load_one_flle(filename): x = [] with open(filename) as f: line = f.readline() line = line.strip('\n') return line def load_adfa_training_files(rootdir): x = [] y = [] list = os.listdir(rootdir) for i in range(0, len(list)): path = os.path.join(rootdir, list[i]) if os.path.isfile(path): x.append(load_one_flle(path)) y.append(0) return x, y def dirlist(path, allfile): filelist = os.listdir(path) for filename in filelist: filepath = os.path.join(path, filename) if os.path.isdir(filepath): dirlist(filepath, allfile) else: allfile.append(filepath) return allfile def load_adfa_webshell_files(rootdir): x = [] y = [] allfile=dirlist(rootdir,[]) for file in allfile: if re.match(r"\.\./data/ADFA-LD/Attack_Data_Master/Web_Shell_\d+\\UAD-W*", file): x.append(load_one_flle(file)) y.append(1) return x, y if __name__ == '__main__': x1, y1 = load_adfa_training_files("../data/ADFA-LD/Training_Data_Master/") # 训练集(normal) x2, y2 = load_adfa_webshell_files("../data/ADFA-LD/Attack_Data_Master/") # 训练集(attack) x3, y3 = load_adfa_training_files("../data/ADFA-LD/Validation_Data_Master/") # 验证集(normal) # 训练集黑白样本混合 x_train = x1 + x2 y_train = y1 + y2 x_validate = x3 + x2 y_validate = y3 + y2 # n-gram模型 vectorizer = CountVectorizer(min_df=1, analyzer='word', ngram_range=(2, 3)) vecmodel = vectorizer.fit(x_train) x_train = vecmodel.transform(x_train).toarray() x_validate = vecmodel.transform(x_validate).toarray() # 根据训练集生成KNN模型 clf = KNeighborsClassifier(n_neighbors=4).fit(x_train, y_train) scores = cross_val_score(clf, x_train, y_train, n_jobs=-1, cv=10) # 反映KNN模型训练拟合的程度 print "Training accurate: " print scores print np.mean(scores) # Make predictions using the validate set y_pre = clf.predict(x_validate) print "Predict result: ", y_pre # 预测的准确度 print "Prediction accurate: %2f" % np.mean(y_pre == y_validate)

0x4:基于Word2Vec模型
# -*- coding:utf-8 -*- import re from sklearn.model_selection import cross_val_score from sklearn.neighbors import KNeighborsClassifier import warnings warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim') import gensim from collections import Counter, defaultdict from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizer import os import numpy as np class MeanEmbeddingVectorizer(object): def __init__(self, word2vec): self.word2vec = word2vec self.dim = len(word2vec.itervalues().next()) def fit(self): return self # 遍历输入词序列中的每一个词,取其在此项量表中的向量,如果改词不在词向量词表中(即训练集中未出现),则填0 def transform(self, X): return np.array([np.mean([self.word2vec[w] for w in words if w in self.word2vec] or [np.zeros(self.dim)], axis=0) for words in X ]) def load_one_flle(filename): x = [] with open(filename) as f: line = f.readline() x = line.strip('\n').split() return x def load_adfa_training_files(rootdir): x = [] y = [] list = os.listdir(rootdir) for i in range(0, len(list)): path = os.path.join(rootdir, list[i]) if os.path.isfile(path): x.append(load_one_flle(path)) y.append(0) return x, y def dirlist(path, allfile): filelist = os.listdir(path) for filename in filelist: filepath = os.path.join(path, filename) if os.path.isdir(filepath): dirlist(filepath, allfile) else: allfile.append(filepath) return allfile def load_adfa_webshell_files(rootdir): x = [] y = [] allfile=dirlist(rootdir,[]) for file in allfile: if re.match(r"\.\./data/ADFA-LD/Attack_Data_Master/Web_Shell_\d+\\UAD-W*", file): x.append(load_one_flle(file)) y.append(1) return x, y if __name__ == '__main__': x1, y1 = load_adfa_training_files("../data/ADFA-LD/Training_Data_Master/") # 训练集(normal) x2, y2 = load_adfa_webshell_files("../data/ADFA-LD/Attack_Data_Master/") # 训练集(attack) x3, y3 = load_adfa_training_files("../data/ADFA-LD/Validation_Data_Master/") # 验证集(normal) # 训练集黑白样本混合 x_train = x1 + x2 y_train = y1 + y2 x_validate = x3 + x2 y_validate = y3 + y2 modelpath = "./word2vec.test.txt" model = None if os.path.isfile(modelpath): # 导入模型 print "load modeling..." model = gensim.models.Word2Vec.load(modelpath) else: # 将词嵌入到一个100维的向量空间中 model = gensim.models.Word2Vec(x_train, min_count=1, size=100) # 保存模型 model.save(modelpath) print "word emberding vocab: ", model.wv.vocab.keys() # 生成词向量词表 words_vocab = dict() for key in model.wv.vocab.keys(): nums = map(float, model[key]) words_vocab[key] = np.array(nums) meanVectorizer = MeanEmbeddingVectorizer(words_vocab) # 将训练语料通过词向量表编码成一个行向量(取均值) x_trainVecs = meanVectorizer.transform(x_train) #for i in range(len(x_train)): # print x_train[i] # print x_trainVecs[i] # print "" # 将验证语料通过词向量表编码成一个行向量(取均值) x_validateVecs = meanVectorizer.transform(x_validate) #for i in range(len(x_train)): # print x_validate[i] # print x_validateVecs[i] # print "" # 根据训练集生成KNN模型 clf = KNeighborsClassifier(n_neighbors=4).fit(x_trainVecs, y_train) scores = cross_val_score(clf, x_trainVecs, y_train, n_jobs=-1, cv=10) # 反映KNN模型训练拟合的程度 print "Training accurate: " print scores print np.mean(scores) # Make predictions using the validate set y_pre = clf.predict(x_validateVecs) print "Predict result: ", y_pre # 预测的准确度 print "Prediction accurate: %2f" % np.mean(y_pre == y_validate)

https://arxiv.org/pdf/1611.01726.pdf - LSTM-BASED SYSTEM-CALL LANGUAGE MODELING AND ROBUST ENSEMBLE METHOD FOR DESIGNING HOST-BASED INTRUSION DETECTION SYSTEMS http://www.internationaljournalssrg.org/IJCSE/2015/Volume2-Issue6/IJCSE-V2I6P109.pdf - Review of A Semantic Approach to Host-based Intrusion Detection Systems Using Contiguous and Dis-contiguous System Call Patterns http://www.ijirst.org/articles/IJIRSTV1I11121.pdf - A Host Based Intrusion Detection System Using Improved Extreme Learning Machine
Copyright (c) 2017 LittleHann All rights reserved