第三章 Webdriver API简介
Selenium 2.0主要的特性就是与WebDriverAPI的集成。WebDriver旨在提供一个更简单,更简洁的编程接口以及解决一些Selenium-RC API的限制。Selenium-Webdriver更好的支持页面本身不重新加载而页面的元素改变的动态网页。WebDriver的目标是提供一个良好设计的面向对象的API,提供了对于现代先进web应用程序测试问题的改进支持。
3.1 Webdriver API
Web应用程序的测试主要是基于调用Webdriver API来模拟用户操作,然后判断操作结果是否与预期的一致,从而达到自动化测试的目的。所以熟悉Webdriver的API的使用很重要,也是我们在做自动化测试的先决条件。
Webdriver API网上有官方文档,不过由于种种原因吧,官网不太容易打开。所以我们可以在百度中去搜索相关的文档,结果也非常多。不同语言的API有点儿不太一样,由于我们采用的是Python作为脚本语言,所以建议看出Python版的,推荐以下两个网页:
(1)selenium_webdriver(python)第一版:http://wenku.baidu.com/link?url=PDcKQYNL-iVRlahMunWoY1BDMw5vyUvv-AFCtC6eUCfG0R5XdC0SnBCHdp742uY6riA25FdBfaUtL-N2uZiXj6PXxIyRGcI-bV1QEYSZHGW
(2)虫师的翻译:http://www.cnblogs.com/fnng/archive/2013/06/16/3138283.html
这两篇文档刚好是一个人的,我看了一下写的比较详细,大家就去自行学习一下吧。
关于WebdriverAPI的一点儿说明:
Ø API只是一些儿封闭的方法,大致浏览一下,知道有哪儿些API,完成什么操作即可,没有必要花很多时间去学习,边用边学。
Ø API的学习要灵活,最好把同类的操作放到一起比较一下。因为在编写测试用例的过程中,不仅仅只有一种方法可以达到预期的结果。
Ø 要会使用Eclipse的联想功能。在写测试用例的时候,如果一时想不起来用什么方法了,可以利用联想功能进行查询。
本章我们就不详细讲解这些儿API的使用方法了,重点将放到页面元素的定位及检查点的设置,这些儿是体现一个自动化测试工程师水平的重点。
3.2 页面元素定位
自动化测试是模拟用户对页面元素进行操作的,所以在操作之前,需要先定位到要操作的页面元素。如果页面元素都定位不到,其他的操作将无从谈起。而对页面元素定位技巧,随着经验的增加,将会越来越精准。而在此,我们将从基础谈起,然后再逐步加深!
3.2.1 WebElement对象提供的各种定位元素策略
下面我们先来讲解一下WebElement对象提供的各种常用的定位元素策略:
Ø 通过ID定位元素:
ID:driver.find_element_by_id(
示例:当一个页面元素如下,明显包含id属性,而且属性值是固定的时候,可以使用这个定位方法。
Ex: driver. find_element_by_id(“nav”)
Ø 通过Name定位元素:
Name:driver.find_element_by_name(
示例:当一个页面元素如下,明显包含name属性,而且属性值是固定的时候,可以使用这个定位方法。
Ex: driver. find_element_by_name(“username”)
Ø 通过ClassName定位元素:
className:driver. find_element_by_class_name(
示例:当一个页面元素如下,明显包含name属性,而且属性值是固定的时候,可以使用这个定位方法。
Ex: driver.find_element_by_class_name(“bx-wrapper”)
Ø 通过TagName定位元素:
tagName:driver.find_element_by_tag_name(
示例:当一个页面元素如下,这是一个form元素,如果本页中只有一个form,可以使用这个定位方法。
<form wx-validator="" method="get" action="/deals" autocomplete="off">
form>
Ex: driver.find_element_by_tag_name(“form”)
Ø 通过LinkText定位元素:
linkText:driver.find_element_by_link_text(
示例:当一个页面元素如下,明显是一个超级链接,可以使用这个定位方法。
Ex: driver.find_element_by_link_text(“cheese”)
Ø 通过PartialLinkText定位元素:
partialLinkText:driver.find_element_by_partial_link_text(
示例:当一个页面元素如下,明显是一个超级链接,但是超级链接显示的文字比较长的时候,可以使用这个定位方法,通过部分文字定位。
Ex: driver.find_element_by_link_text(“cheese”)
Ø 通过CSS定位元素:
css:driver.find_element_by_css_selector(
示例:当一个页面元素如下,这个可以使用CSS定位。
……
Ex:driver. find_element_by_css_selector(“#div.m-right.clearfix span.z-Login”)
Ø 通过Xpath定位元素:
xpath:driver.find_element_by_xpath(
示例:当一个页面元素如下,div中嵌套h3,h3中嵌套a标签,现在我们要定位这个a标签的元素。现在我们采用xpath定位方法:
Ex:driver. find_element_by_xpath(“//div[@class=’ lev_Box lev_Box_noborder’]/h3/a”)
以上是WebElement对象提供的定位方法,这八种方法是最基本的。不过大家要有这样的一个共识,元素定位不只是有一种方法能定位到。一个页面元素可以通过很多种方法来定位,要选择一个比较恰当的方法,这就需要一些儿技巧和经验了。
3.2.2 定位方法的选择
页面元素的定位,是页面自动化测试过程中的首要任务及重中之重。如果连元素都定位不到,再好的测试框架,高超的编程技巧,也无法完成自动化测试用例的编写。所以本节我们就从最基本的开始,当我们欲定位一个页面元素的时候,应该如何选择定位方法。
为了简单期间,我们就以百度为例,来讲解页面元素定位方法选择的思路。现有一个测试用例如下:
测试步骤:
(1) 打开百度首页,输入“自动化测试”。
(2)百度一下,检测搜索结果
分析:
(1)打开百度没有任何问题,直接调用WebDriver API就行了。可是要输入“自动化测试”,我们首先要定位到输入框架,然后再能输入要查询的关键字。
(2)百度一下,要定位到“百度一下”按钮,才能执行单击操作。检测搜索结果的时候,需要在查询结果页定位查询到的网页标题或是内容,才能检测。
好了,目前我们明白自动化要做的内容了,就可以着手去编写自动化测试用例。至于如何编写是以后章节的内容,本节我们主要关注元素定位的部分。现在我们按如下步骤进行定位:
第一步:用火狐打开百度首页。
我们之所以有火狐打开百度,是想利用在第二章我们讲到的火狐的插件来定位元素。
第二步,用Firebug查找定位的元素。
Firebug想必大家已经会使用了,我们打开firebug,利用“点击查看页面中的元素”按钮,点击输入框,则firebug会以选中状态显示输入框在HTML中的标签。如图3.2.2.1 所示:

图3.2.2.1选中状态显示输入框
第三步,分析选择定位方法。
我们先分析一下这个标签的特点:
Ø 这是一个input标签,所以说TagName是input,通过我们查看网页源码,发现不是只有一个这样的标签,所以不能用find_element_by_tag_name来定位。
Ø 分析标签的属性,发现标签中具有我们特别感兴趣的属性class,name,id,这三个属性可以用来定位,而autocomplete,maxlength,value经过分析是不可用的,所以舍弃。
Ø 假如标签不存上面的三个属性,我们就考虑一下能否用Xpath和CSS。
方法:从此标签向上查找,遇到一个它的上级标签,就去找有没有唯一的属性,如果有,从此层往下写Xpath或Css,如果没有,接着向上层查找。
本标签的上一级标签是span,span有Class属性,但其值中有空格,不能使用Xpath(原因见下节),但可以使用Css,Css的定位方法是:input#kw.s_ipt。
Ø Xpath定位方法,我们接着上面继续向上查找,再上一级是form标签,这个标签有id,name,class属性,比较适合用来定位,所以从此层开始写Xpath是://form[@id=’form’]/span/input或//form[@name=’f’]/span/input或//form[@class=’fm’]/span/input。
Ø 这个标签不是超级链接,所以不能用link相关的定位方法。
第四步,编写定位代码
针对该标签,我们现在把能用的定位方法全部写下来:
Ø id: driver. find_element_by_id(“kw”)
Ø name: driver. find_element_by_name(“wd”)
Ø class: driver. find_element_by_class_name(“s_ipt”)
Ø css: driver.find_element_by_css_selector(“input#kw.s_ipt”)
Ø xpath:driver.find_element_by_xpath(“//input[@id=’kw’]”)
由此可见一个页面元素的定位方法是相当多的,我们可是根据需要选择。然后再放到代码中去调试,如果不行,就换另外的办法。原则就是越简单的定位方法越好,因为这样的定位方法受到网站改版的影响也越小。
第五步,工具使用定位
经过上面四步我们已经可以定位页面上的元素了,不过这都是通过我们人工来查看的,然后手动编写的代码。有没有更加简单的方法来定位呢?答案是Yes,就是我们前面提到的FireBug和SeleniumIDE。下面我们简单地介绍一下使用方法:
(1) Firebug提取元素的Xpath,Css路径。
元素的id,name,class属性一目了然,直接可以使用,如果元素没有这几个属性,就需要用Xpath和Css路径定位了。但是这两个路径不太容易写出来,所以Firebug提供了方法。
首先,我们用Firebug找到要定位的元素。然后右击这个元素在Firebug中的位置,从弹出的菜单中选择“复制Xpath”,“复制最简Xpath”或是“复制CSS路径”。最后将复制到的内容粘贴出来,这就是对应页面元素的xpath或是Css路径。如图3.2.2.2所示:
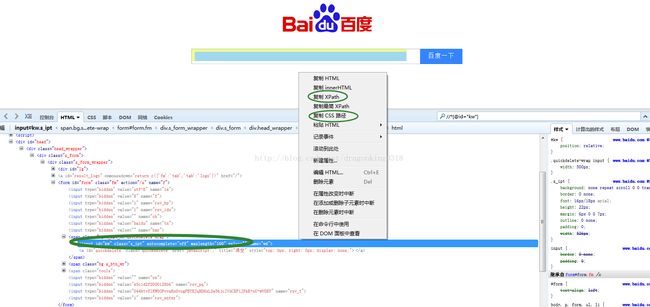
图3.2.2.2提取页面元素的CSSor Xpath路径
(2) Selenium IDE验证提取的路径是否正确。
通过Firebug我们可以提取出元素的Css或者Xpath的路径,可是提取的究竟对不对呢?工具有的时候也不太靠谱,所以我们要验证一下。最直接的办法就是放到测试用例中去执行一下,但是一直在执行测试用例,这样比较耗时。我们可以借助于SeleniumIDE来验证一下。
验证方法如下:
Ø 用FireBug提取出要定位的元素的Xpath或者Css路径。
Ø 打开SeleniumIDE界面,右击界面“Insertnew command”。
Ø 将复制的路径粘贴到IDE的Target文本框中,如果复制的是Css路径,需要在复制的路径前加上“Css=”。
Ø 单击Find按钮,此时Firebug中显示的要定位的元素会标黄显示,表示定位正确。如图3.2.2.3所示:
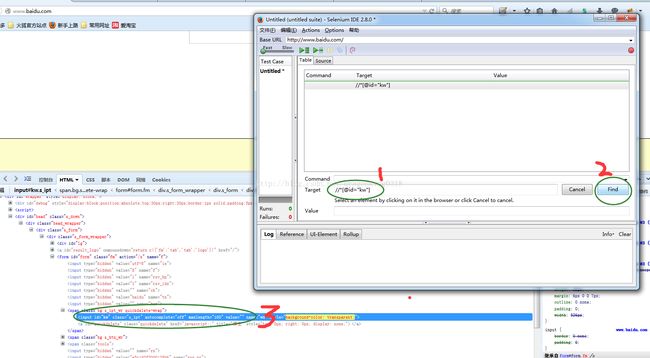
图3.2.2.3 验证定位元素正确的情况
Ø 如果复制的路径不对,则IDE会在log区以红色的信息提示定位不到。如图3.2.2.4所示:
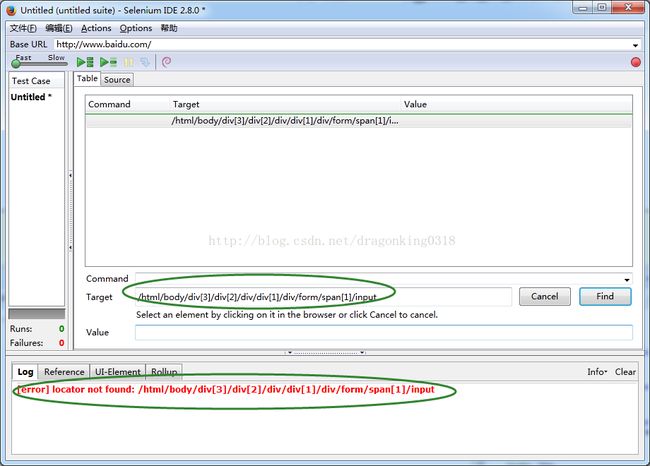
图3.2.2.4 验证定位元素定位不到的情况
注意:
Firebug提交的路径一般都是从页面起始位置标签开始,一直提取到要定位的元素,是相对路径,容易受到网页变化的影响。不建议直接使用,只可以作为参考。
Selenium IDE验证定位方法,不仅仅可以验证Firebug复制的路径,还可以验证我们自己编写的路径,比用代码验证方便快捷。这种验证方法是我的最爱,节省了不省时间。
3.2.3 Xpath定位方法深入探讨
相比cssSelector,xpath是我比较常用的一种定位元素的方式,因为它很方便,缺点是,消耗系统性能。如果Xpath使用的比较好,几乎可以定位到任何页面元素,而且受页面变化影响较小。
(1)常用的Xpath定位方法及其特点
Ø 使用绝对路径定位元素。
例如:driver.find_element_by_xpath ("/html/body/div/form/input")。
特点:这个路径是从网页起始标签开始一直到要定位的元素的路径,如果要定位的元素在页面最下面,则这个Xpath路径会非常长。如果在要定位的元素与页面开始之间的元素有任何增减,元素定位就会失败。
Ø 使用相对路径定位元素。
例如:driver.find_element_by_xpath ("//input") 返回查找到的第一个符合条件的元素。
特点:相对路径一般只会包含与被定位元素最近的几层元素有关,相对路径写的好的话,页面变动影响最小,而且定位准确。
Ø 使用索引定位元素,索引的初始值为1,注意与数组等区分开。
例如:driver.find_element_by_xpath ("//input[2]")返回查找到的第二个符合条件的元素。
特点:如果一个页面中有多个相似的元素,或是一个层下面有多个同样的元素的时候,需要用索引的方法来定位,否则无法区分。
Ø 结合属性值来定位元素。
例如:driver. find_element_by_xpath ("//input[@id='username']");
driver. find_element_by_xpath ("//img[@alt='flowr']");
特点:属性定位也是比较常用的方法,如果元素中没有常见的id,name,class等直接有方法可调用的属性,也可以查找元素中是否有其他能唯一标识元素的属性,如果有,就可以用此方法定位。
Ø 使用逻辑运算符,结合属性值定位元素,and与or。
例如:driver. find_element_by_xpath ("//input[@id='username' and@name='userID']");
特点:多个属性值联合定位,更能准确定位到元素。并且如果多个相同标签的元素,如果其包含的属性值有不同的,也可以用这个方法区分开来。
Ø 使用属性名来定位元素。
例如:driver. find_element_by_xpath ("//input[@button]")
特点:此方法可以区分同一种标签,含有不同属性名的元素。定位相对简单一些儿,但也同样存在着无法区分同种标签含有同种属性名的多个元素,这个时候要配合索引定位才行。
Ø 类似于cssSlector,使用部分属性值匹配元素.
例如:
(a)starts-with()
driver. find_element_by_xpath ("//input[stars-with(@id,'user')]")
(b)ends-with()
driver. find_element_by_xpath ("//input[ends-with(@id,'name')]")
(c)contains()
例如:driver. find_element_by_xpath ("//input[contains(@id,"ernam")]")
特点:此方法更加灵活,可以定位属性值不太规律,或是部分变动,中间有空格的情况。注:如果属性值中间包含空格,Webdriver定位的时候容易出错,时而能定位到时而定位不到,所以应该避免用含用空格的属性值定位。可以采用此方法,进行部分属性值定位。
Ø 使用任意属性值匹配元素。
例如:driver. find_element_by_xpath ("//input[@*='username']")
特点:此方法相当于模糊查询,只要欲定位的标签,如input中任何属性值等于‘username’,就能匹配成功。缺点,可能会匹配含有这个属性值的其他元素,所以我们在定位的时候要查看一下这个元素值在页面中是否唯一。
(2)运用Xpath定位元素的思路
当我们在做自动化测试的时候,欲对一个页面元素定位,通过上面我们讲到的选择定位方法筛选后,决定用Xpath定位了,此时我们应该怎么写Xpath呢?请按以下步骤来分析:
(a)先看一个这个元素是否有明显的,唯一的属性值。如果有,我们就用相对路径加属性值定位,这是最简单准确的定位方法。如://input[@alog-alias=’search’]。
(b)如果要定位的元素,不符合上面的特症,元素属性要么是动态的,要么就是不能区分这个元素的,还有就是属性值中间有空格的情况,都无法定位。所以从此元素开始,向他的上一层查找。
(c)当遇到了一个符合条件的元素时,对其写Xpath,然后在Selenium IDE中验证是否能定位到该元素。如://div[@type=’good’],在Selenium IDE中验证能定位到这个div。
(d)然后从这个元素开始,一级级往下写,真到要定位的元素为止。如果你比较肯定写的是正确的,可以写完后再验证,如果不肯定,就写一层,用Selenium IDE验证一下,以确保安全。如://div[@type=’good’]/div/input
(e)当Selenium IDE定位成功后,再放到测试用例中去调试运行。虽然Selenium IDE能定位到的代码也能定位到,不过还有因为延迟,操作顺序等会影响代码定位的因素存在。
3.2.4 元素定位不到的原因及解决办法
在我们编写自动化测试用例的过程中,经常会遇到元素定位不到的现象,有的时候我们用Selenium IDE检查的时候也能在Firebug中看到,可是运行代码的时候,总是提示元素找不到。经过我以往和经验和大家在网上的讨论,我总结了以下几种情况:
(1)定位属性值是动态变化的情况
现象:在我们定位元素的时候,发现有id, name或其他的属性存在,于是就用相应的定位方法去定位。可是运行的时候提示定位不到,然后我们再去查看元素的时候,发现属性值和我们写代码的时候不一样了。
原因:通常产生这种情况的原因就是你使用的属性值是动态变化的,主要表现有属性值是一串数据,或是字符加一串数据等情况。页面加载一次变化一次,每次都不相同。
解决办法:我们应尽量避免用这样的属性值去定位,而采用这个元素下的其他固定不变的属性值。或是向上层查找,采用Xpath定位。
(2)Iframe中的元素定位出错的情况
现象:我们在定位元素的时候,查看网页源码,发现有iframe存在。可是我们没有做特殊处理,而是直接用通用的定位方法,name ,id, xpath或者CSS来定位。用Selenium IDE验证能查找到元素,可是运行测试用例的时候,总是元素找不到。
原因:在我们运行测试脚本的时候,代码获取的是页面的句柄,而iframe在句柄中是当成一个元素来处理的。脚本是没有办法自己去iframe中去定位元素的,所以当搜索完页面时,发现找不到要定位的元素,就当错误处理。
解决办法:当需要定位iframe中的元素的时候,先将句柄切换到iframe中(driver.switchTo().frame("framename");),然后再去定位,就能定位到要测试的元素。
(3)不同页面或iframe切换时元素定位情况
现象:当我们在编写测试用例的时候,会遇到打开一个新页面,或是切换到一个新的iframe中,然后再去定位元素进行操作。但是我们的定位方法写的没有问题,而且在Selenium IDE中也验证通过,可是代码运行的时候还是会提示找不到元素。
原因:其实这个和定位iframe中元素的情况是一样的,在打开一个页面或是切换到一个iframe的时候,driver获取的是当前页面或是iframe的句柄。当你的操作切换到新的页面或是iframe的时候,如果代码不去做相应的切换,查找元素的时候还会在原来的句柄下查找,当然会出现查找不到的情况。
解决办法:当操作切换页面或是iframe的时候,我们的测试脚本也要做相应的切换,选择新打开的页面或是切换到新的iframe下。然后再去定位的时候,就会在新页面或是iframe下定位了。
(4)Xpath编写出错的情况
现象:如果我们对一个元素编写了对应的Xpath,然后在没有通过Selenium IDE进行验证的情况吧,就去编写代码执行测试用例。会出现查找不到元素的情况,或是页面发生了变化,导致Xpath路径有了变化,也会查找不到元素。
原因:主要的问题就是Xpath编写出错了,或是页面有改动。不管是增加了新的模块或是隐藏的div,都会影响Xpath路径的。
解决办法:将代码中的Xpath拷出来,放到Selenium IDE中进行验证。如果出错了,就做相应的修改。这个也是代码维护中当遇到的问题,被测试对象变化,导致测试用例的修改。
(5)操作速度过快,被定位的元素没有加载出来的情况
现象:在测试用例运行过程中,会出现被定位的元素有的时候能定位的到,有的时候却定位不到的现象。而我们去页面上验证我们的定位方法的时候,没有一点儿问题,显示不是定位方法写错了。
原因:这种情况多半是因为测试用例执行到代码的时候,被定位元素没有加载出来造成的。网速原因,执行代码的机器原因,都会造成加载比程序执行的慢的情况。
解决办法:在我们定位元素之前,评估一下页面的加载情况,如果有加载慢的地方,需要添加一定等待时间self.sleep(5000),等上几秒后再去定位操作。
(6)定位页面嵌入式元素的情况
现象:在页面中会有一些儿嵌入式元素,如object,播放器等。这个时候,我们对其操作的时候,是无法定位到上面的元素的。
原因:嵌入式元素对webdriver来说是一个元素,不管里面包含多少元素,都无法操作。对于object对象,网上有说要对相应的Flash重新编译,添加相应的代码或是控件才能定位。但这样一样又不安全了,所以嵌入式对象一直是自动化测试的盲区。
解决办法:嵌入式对象如果是简单的单击操作,可是用模拟鼠标单击相应的区域,就能完成操作。如果是输入操作,我们可以先模拟点击输入区,然后模拟键盘进行输入。除此之外,好像也没有什么好的办法。
(7)firefox安全性报错的情况
现象:firefox安全性强,不允许跨域调用出现报错,错误描述:uncaught exception: [Exception... "Componentreturned failure code: 0x80004005 (NS_ERROR_FAILURE) [nsIDOMNSHTMLDocument.execCommand]"nsresult: "0x80004005 (NS_ERROR_FAILURE)" location:
原因:这是因为firefox安全性强,不允许跨域调用。
解决办法:Firefox 要取消XMLHttpRequest的跨域限制的话,第一
是从 about:config 里设置 signed.applets.codebase_principal_support= true;(地址栏输入about:config 即可进行firefox设置)。
第二就是在open的代码函数前加入类似如下的代码:
try {netscape.security.PrivilegeManager.enablePrivilege("UniversalBrowserRead");
}
catch (e)
{
alert("PermissionUniversalBrowserRead denied.");
}
对错误进行处理。
3.3 检查点的设置
自动化测试不像手工测试,在执行测试用例的过程中,我们可以随时看到结果,然后能判断正确与否。而自动化测试对应的就是检查点,如果不设置检查点,只有测试步骤的自动化测试是没有任何作用的。因为执行步骤执行完了,结果不是我们想要的时候,测试用例也是正确的。所以检查点才是自动化测试执行成功或是失败的检验标准,而检查点的设置是发现Bug的关键。
3.3.1 常用的检测点设置方法
我们通过了一系列的操作后,就需要检查测试执行的结果,常用的就是Assert相关的函数。下面我们谈一下最常用的两种方法:
(1)手工设置检测点
在我们测试用例执行完成之后,对测试结果进行检测。我们还是个例子来说明一下:
例子:在众筹网上喜欢一个项目,在进行了一系列的喜欢操作后,我们要检测操作是否成功。
Ø 进入到“喜欢的项目”列表页,检查是否有刚刚喜欢的项目。
Ø 我们可以直观地看到有喜欢的项目,可是怎么用程序判断呢?如图3.3.1.1所示:
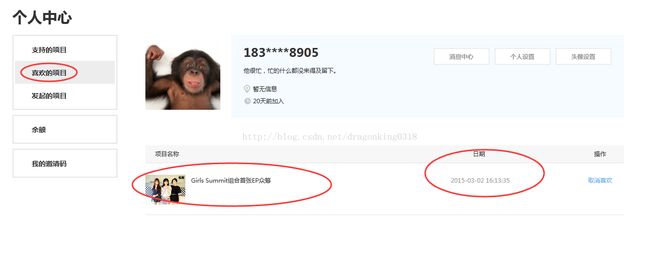
图3.3.1.1 检查喜欢的项目
Ø 我们要先定位项目名称“Girls Summit组合首张EP众筹”对应的Xpath:“//div[@class='m-location']/table/tbody/tr[2]/td/div/div/p/a”,然后获取这个元素对应的Text。
Ø 将获取到的Text与“GirlsSummit组合首张EP众筹”字符串进行assertEquals(),如果相同,则说明喜欢成功。否则,喜欢操作失败。
Ø 同样方法验证一下日期是不是今天,如果不是,可能是先前喜欢的操作,测试用例仍然失败。
(2)Selenium IDE设置检测点
我们也可以用Selenium IDE录制测试用例,在操作完成后,需要添加检测点,此时只要利用Selenium IDE提供的“Show all Available Commands”菜单选择合适的检测点即可。
例如:同样是上面的那个喜欢项目操作的例子,我们的设置步骤如下:
Ø 进入到“喜欢的项目”列表页,检查是否有刚刚喜欢的项目。
Ø 如图3.3.1.2所示,右击项目名称,选择“Show all Available Commands”菜单,然后在打开的子菜单中选择合适的Assert菜单。
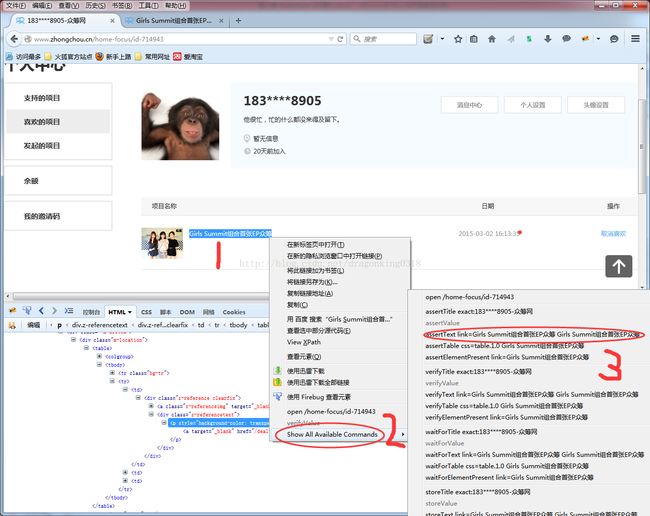
图3.3.1.2 selenium IDE设置检测点
Ø 然后Selenium IDE中就会出现相应的assert命令,如图3.3.1.3所示:
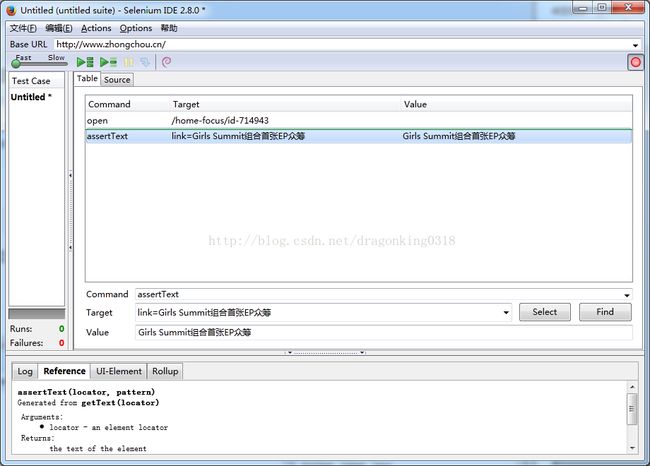
图3.3.1.3 Selenium IDE记录Assert操作
Ø 转化成相应的编码,如python,就可以直接拷到测试用例中使用。转化后的编码如:self.assertEqual(u"GirlsSummit组合首张EP众筹",driver.find_element_by_link_text(u"Girls Summit组合首张EP众筹").text)
3.3.2 检测点设置技巧
正如我们上面所说的,好的检测点是发现Bug的关键。但是并不是说检测点设置的越多越好,因为检测点会消耗机器资源,测试用例出错的时候增加排查难度。所以如何设置检测点呢?通常可以参考如下方法:
(1)根据测试用例的侧重点设置检测点
每个测试用例都有测试的重点,比如说,我们测试登录的时候,登录是否成功,就需要检测。但是在我们测试喜欢项目的时候,需要先登录,这个时候登录就不需要设置检测点了,因为在登录测试用例中已经测试过了。
(2)设置检测点要全面
我们在编写测试用例的时候,一定要全面了解测试操作影响了哪些儿方面。对影响到的地方,都设置一下检测点,防止出现遗漏的地方。
(3)设置检测点要灵活
设置检测点的时候,我们通常会比较一下实际的结果和预期结果是否相同。可是有些儿时候,我们不能简单地进行是否相等来判断。比如说:检测图片的时候,可能会检测图片是否显示;有的检测对象在某些儿页面会换行或是添加空格,与预期有变化,这个时候我们可以判断是否包含关键字即可。灵活使用各种判断函数,才能使自动化测试用例更加健壮。
3.3.3 检测点设置中常见的错误
在测试过程中,我们编写了测试用例,设置了检测点,可是在测试用例投入使用的过程中,我们不得不反复修改测试用例。因为测试用例总是通不过,维护成本很高。虽然这一部分是因为被测对象变化造成的,还有一部分原因是检测点设置的不对。所以常见的检测点设置中的错误如下:
(1)检测动态变化的元素
检测点不能随着操作而变化,比如说翻页。我们想要测试翻页是否成功,就不能去检测第二页第一个元素是否是某个项目。因为如果项目增加的话,第二页第一个元素的项目可能会变化。应该先取一下第一个位置的项目名称,然后翻页,再判断现在第一个位置的项目是不是和刚刚获取的项目名称相同,如果不同,就证明翻页成功。
(2)遗漏检测点
在一个测试用例中,我们要检测所有影响到的地方。如喜欢项目操作,如果我们只检测我的喜欢项目列表中有没有刚刚喜欢的项目,这是不够的。还要检测一下这个项目的喜欢数据是否+1,喜欢项目的入口是否变成已喜欢等相关检测点。
(3)检测点设置过多
既然你说了,检测点是检测Bug的关键,我们就在每一步操作后添加检测点。这样做也是多余的,虽然检测点多了,更加安全一点儿,但是过多的检测点儿影响测试用例运行。而且测试用例如果出错了,我们去定位错误的时候,也非常困难,或是一个测试用例出错会导致相关的测试用例无法执行。
(4)忘记设置检测点或是检测点不是测试重点
新手写自动化测试用例的时候,往往会写了每一步的测试操作代码,没有添加对应的检测点或是检测点设置不正确。明明是登录操作,操作完成之后却检测页面显示是否正确,这样会不管操作成功与否,测试用例都不会报错,使自动化测试用例失去了意义。
(5)检测需要刷新才有反映的元素
在测试的时候,有些儿元素在操作完成后需要刷新一下页面才能显示出操作的结果。手工测试的时候,一般会触发刷新操作,可是自动化的时候,如果不刷新,就不符合预期结果。所以我们要添加刷新页面的代码,然后再去检测。
这几种是常见的错误,当然也会有一些儿比较奇葩的检测点设置错误的情况。在此也不能一下列举了,遇到问题,要多尝试几种方法,会在网上搜索解决办法,这也是学习自动化测试必备的技能。