大数据量分析统计——电信经营分析项目心得
众所周知,在电信行业,通话清单数据量非常大,因为用户每次通话交换机都会产生一条数据,数据保存的方式是放在文件。如果将数据文件导入到数据库中,很容易使数据量达千万级的数据库,另由于其它基础信息会放在其它表中,如果按照传统思维,进行简单的关联统计,数据库基本将无法统计出结果,即使是用小型机来运算,得到结果也是几天后的事情了。而用户最多只能等待20秒就需要了解结果,显然传统的简单的分析统计方法是无法实现大数据量的统计分析的。那如何对如此庞大的数据库进行统计分析呢?本人下面以Oracle数据库为例进行分析。
一、分析过程概述
由于大数据量,在数据处理时,遵守的原则是,尽量将数据按各种分类分离,使得在各分类分析时,数据量最小。所以,在进行清单到报表的处理时,通常经过数据的清洗入库,分类合并得出中间结果,最后关联统计出结果数据。用户在查看报表时,已经是简单的由结果数据中查询各种数据。
二、分步详述
2.1
、清单入库
清单入库主要是将交换机上产生的通话清单导入到数据库中。如何将清单进行清洗,如何保存清单?合理的清洗,合理的保存对后期分析的速度及效率会有很大的影响。
1、 将清单分类
如电信通话清单可分为:卡类清单、公话清单、市话清单等。依据分类建立分类导入的程序。
2、 按分类建立临时库表结构
临时库表结构,用于保存初始导入的清单数据,不作数据的永久保存,只做数据清洗用途。
3、 建立分区表
分区表按照清单的分类建行建立,也就是每个清单分类都需要建立一个分区表,分区表的分区依据可以根据时间段内的数据量,以及硬件的速度,数据提取的要求等综合考虑来进行化分。原则是数据提取或进行统计运算时,速度不能太慢。我自己的经验是按月来分区保存的。
4、 清单的清洗
清单清洗时,可以有两种方式,导入前清洗和导入后清洗。导入前清洗是指自己写一个清洗程序,按照业务的要求,进行清洗,清洗后将数据导入到数据库中。导入后清洗是先将数据直接导入到数据库中,在数据库中通过存储过程来进行清洗,清洗的规则按照业务要求定义。我们采取的方法是用SQL Loader直接将文件导入数据库,在数据库中进行按业务要求过滤数据,并将初步清洗的数据导入到分区表中。
2.2
分类合并
分类合并是非常重要的一个步骤,由于清单数据中只包括电话号码、通话时长、通话费用、通话开始时间和通话结束时间,故无法以机构、业务类型、用户类型、渠道、用户性质等维度来进行统计分析。
分类合并,最重要就在于分类两个字了,而分类与业务要求的结果有着直接的联系,故在做这一步时,首先要了解业务需求,按照业务的要求进行中间结果的分类。我以某电信业务需求为例来进行下面的阐述。
如:某电信要求统计市话话务收入、市话通话时长、市话通话次数,并以上面介绍的维度进行统计。本人建立了如下中间结果表:市话话务收入、市话通话时长、市话通话次数共三个中间结果表。由于清单中同一个电话号码通常有多条记录(一个电话每天会拔打很多次),中间结果就是要根据分类来合并这些记录。如统计市话收入,SQL语句为: “select 号码,sum(费用) from 市话清单表 group by 号码”。统计市话时长,SQL语句为:“select 号码,sum(时长) from 市话清单表 group by 号码”。将按号码合并的数据分别保存到相应的分类中间表中。这时候分类的中间表的数据量则为统计日期发生拔出的电话号码的个数。分类合并过后,中间结果表的数据将比清单数据大大减少。
合并后的清单,有些要求保存起来,便于以后做统计,这时需要另建表保存清单数据,中间结果表只作为运算的桥梁,不可以长时间保存数据。一旦应用完毕,需将中间表清空。
注:如果是业务量不太大的电信局,或者是统计时要求同时出现时长、市话、次数,中间结果表可设定为一个,总之要看具体要求。原则是,中间结果表中数据量尽量少,但又要尽量满足业务的统计。另外,本人在做清单统计时,按照天做清单合并(每天晚上1点做前一天的数据合并)
2.3
关联统计
电信的基础信息表,通常是独立的保存,如:号头与机构对应表、号头与业务类型对应表、号头与渠道对应表等。通过合并后的号码清单与基础信息相关联即可得到各种统计数据。如下图:
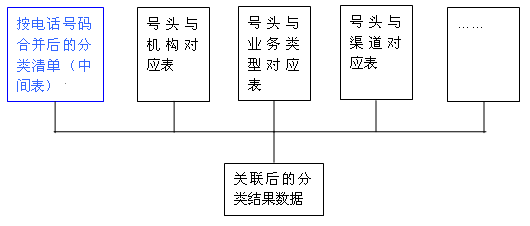
由于有了按电话号码存放的各种分类的中间结果表,再进行关联统计分析就比较方便了。按照业务需求,首先建立结果表。结果表的建立仍然是按数据量最少,统计功能满足业务需求即可的原则。按上面的例子,统计维度要求按机构、业务类型、用户类型、渠道、用户性质、日期等进行统计。一般而言,我们在查看具体的报表时,并不要求同时查看如此多的维度,可能要求查看按机构、时间段、用户类型的报表。这时,我们的结果表只需要保留机构、时间、用户类型等维度字段即可。
由中间结果到结果表运算时,处理技巧非常重要,若有多个维度需同时查看时,有时可能需要逐个关联处理,以降低数据量,逐个关联处理时,就需要再建中间表用于保存当前数据。原则是,在进行表之间关联处理时,让笛卡尔乘积数量最小。通常数量越小处理速度会越快。
注:在关联处理时,尽量不要用游标模式来进行数据处理,游标模式在大数据量时对数据处理会使得运行效率极低。一般而言,表面上需要用游标处理的时候,都可以进行分步统计,分步更新结果等方式绕开游标处理。另外根据结果的数据量来确定,是否要建分区表,或者是历史数据表,以保证查询的响应速度
在结果表中,保存了用户查询的维度及此相关数据,基本不需要再做关联即查询到用户所需数据,故这时用户查询的时间基本在1~5秒钟之内能响应出来。
三、大数据量分析统计注意点
1、 数据表一定要建索引。
2、 大数据量一定要建分区表。
3、 数据统计时要尽量避免使用游标。
4、 可以分步统计,并能降低笛卡尔乘积时,要用分步统计。
5、 多层关联时,视情况将关联后笛卡尔乘积较少的放在前面。
6、 在多关联时,如果可以转换为union模式尽量用union模式来做统计。因为union模式是数据量的加值,而不是数据量的乘积。(本人在做脚本优化时,经常碰到其它编写人员不用union模式来统计,改过后速度成倍增加)