centos6.5/Hadoop3.1.1环境搭建(完全分布式集群模式)
一、系统环境配置及设置要求
1、安装VMware Workstation 12 Pro
网上下载虚拟软件自行安装
2、安装虚拟机系统CentOS 6.5
网络适配器按如下设置,这样能保证网络互通

3、虚拟机准备好三台服务器
对应的IP和hostname要求如下
192.168.160.193 master
192.168.160.194 worker1
192.168.160.195 worker2
4、更改每台主机的hostname
切换到root用户,vi /etc/sysconfig/network
HOSTNAME后面的值改为想要设置的主机名。

5、更改每台主机的hosts文件、关闭防火墙
修改hosts:
切换root用户, vi /etc/hosts
每个主机的hosts文件第一行添加这三条IP和hostname对应关系
192.168.160.193 master
192.168.160.194 worker1
192.168.160.195 worker2
同时把每个主机hosts文件最后localhost两行注释掉

关闭防火墙:
[root@master]# vi /etc/selinux/config
设置 /etc/selinux/config 文件中的 SELINUX="disabled " ,然后重启。
或者
开启:[root@master]# chkconfig iptables on
关闭:[root@master]# chkconfig iptables off
完成以上设置后,输入命令reboot,重启服务器
6、实现本机和每台主机之间免登陆操作
实现本机免登陆:
每台主机通过ssh-keygen -t rsa命令生成密钥
[zengms@master ~]$ ssh-keygen -t rsa 一直回车
[zengms@master ~]$ pwd
/home/zengms
[zengms@master ~]$ cd ~/.ssh
[zengms@master .ssh]$ pwd
/home/zengms/.ssh
[zengms@master .ssh]$
.ssh目录下会生成.ssh/id_rsa、id_rsa.pub两个文件,分别为私钥,公钥
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
chmod 600 authorized_keys 设置权限
先验证本机免登陆:ssh localhost(第一次需要输入密码)——如提示yes/no,输入yes
操作完成后,后续再通过ssh localhost登录就不需要人输入密码可直接登录
[zengms@master ~]$ ssh localhost
Last login: Wed Apr 24 01:48:23 2019 from 192.168.160.1
[zengms@master ~]$
验证成功
实现主机之间相互免登陆:
思路:将worker1、worker2主机authorized_keys文件中的密钥信息复制到master主机的authorized_keys文件中并保存
[zengms@master ~]$ cd ~/.ssh
[zengms@master .ssh]$ vi authorized_keys

最终master主机的authorized_keys文件中包含三台主机的所有密钥,把master主机的authorized_keys文件拷贝并覆盖worker1、worker2主机上的authorized_keys即可;
[zengms@master ~]$ ssh zengms@worker1
Last login: Wed Apr 24 01:48:26 2019 from 192.168.160.1
[zengms@worker1 ~]$
验证成功,同理其他主机也可以完成相互免登陆
7、安装lrzsz
软件主要是用来方便上传文件,这个看个人需要,有的喜欢用ftp相关工具
每台主机切换root用户运行如下命令安装:
yum -y install lrzsz
可以正常使用rz、sz命令上传、下载数据了。
使用方法:
上传文件
# rz filename
下载文件
# sz filename
二、java和hadoop环境搭建
1、安装64位java8
这边java安装采用全局配置,即采用root操作
官网下载java(下载前需要先接受协议):https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
上传安装文件jdk-8u45-linux-x64.tar.gz,至目录/opt/java/jdk-8u45-linux-x64.tar.gz,并解压tar -xzvf jdk-8u45-linux-x64.tar.gz
配置环境变量(root用户编辑),打开vi /etc/profile配置文件,把如下代码添加到末尾处
export JAVA_HOME=/opt/java/jdk1.8.0_45
export JRE_HOME=/opt/java/jdk1.8.0_45/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
执行profile文件让文件生效:source /etc/profile
检查java是否安装成功:java -version
java version "1.8.0_45"
Java(TM) SE Runtime Environment (build 1.8.0_45-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
2、安装Hadoop
apache 官网下载(http://hadoop.apache.org/)hadoop-3.1.1.tar.gz
上传到 服务器/home/zengms/tools/hadoop-3.1.1.tar.gz
解压tar -xzvf hadoop-3.1.1.tar.gz ——解压到指定目录(这边解压到/home/zengms/install/hadoop-3.1.1目录)
配置当前用户的hadoop环境(注:环境变量可在 ~/.bash_profile(只对当前用户有效 ) 或者 /etc/profile(对所有用户有效) 中配置)
编辑~/.bash_profile文件,添加一下代码(这里设置在当前用户下)
PATH=$PATH:$HOME/bin
export PATH
export JAVA_HOME=/opt/java/jdk1.8.0_45
export HADOOP_HOME=/home/user0/install/hadoop-3.1.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行profile文件让文件生效:source ~/.bash_profile
检查hadoop版本 hadoop version
Hadoop 3.1.1
Source code repository https://github.com/apache/hadoop -r 2b9a8c1d3a2caf1e733d57f346af3ff0d5ba529c
Compiled by leftnoteasy on 2018-08-02T04:26Z
Compiled with protoc 2.5.0
From source with checksum f76ac55e5b5ff0382a9f7df36a3ca5a0
This command was run using /home/user0/install/hadoop-3.1.1/share/hadoop/common/hadoop-common-3.1.1.jar
三、hadoop集群设置
三个结点:一个主节点master两个从节点
| Ip地址 | 主机名 | Namenode | Secondary namenode | Datanode | Resource Manager |
NodeManager |
| 192.168.160.193 | master | Y | Y | N | Y | N |
| 192.168.160.194 | worker1 | N | N | Y | N | Y |
| 192.168.160.195 | worker2 | N | N | Y | N | Y |
由于hadoop集群需要在每一个节点上进行相同的配置,因此先在master节点上配置,其他节点按相同配置就行。
1、修改/hadoop-env.sh配置文件
cd home/user0/install/hadoop-3.1.1/etc/hadoop/
vi hadoop-env.sh
export JAVA_HOME=/opt/java/jdk1.8.0_45 ——必须是绝对路径
执行source hadoop-env.sh使其生效
2、修改workers
修改/home/zengms/install/hadoop-3.1.1/etc/hadoop目录下的workers文件
[zengms@master hadoop]$ pwd
/home/zengms/install/hadoop-3.1.1/etc/hadoop
[zengms@master hadoop]$ vi workers
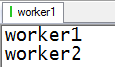
删除workers中的localhost,添加worker1和worker2


3、core-site.xml配置
4、hdfs-site.xml配置
5、mapred-site.xml配置
<--配置MapReduce运行框架-->
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
6、yarn-site.xml配置
配置完成,启动集群验证
三、运行hadoop集群
1、在master主机上格式化namenode
hdfs namenode -format
start-dfs.sh
start-yarn.sh
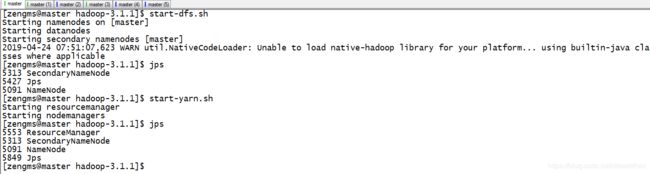

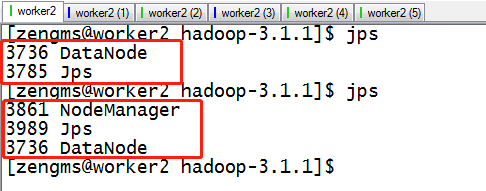
集群搭建完成。
可以通过hdfs可视化端口 9870,访问地址:http://192.168.160.192:9870
可以通过yarnh可视化端口8088,访问地址:http://192.168.160.192:8088
四、部署遇到的问题
hadoop 在启动的时候报下面的错误:
2012-09-18 13:42:38,901 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.160.193:9000. Already tried 0 time(s).
2012-09-18 13:42:39,904 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.160.193:9000. Already tried 1 time(s).
2012-09-18 13:42:40,906 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.160.193:9000. Already tried 2 time(s).
2012-09-18 13:42:41,908 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.160.193:9000. Already tried 3 time(s).
2012-09-18 13:42:42,910 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.160.193:9000. Already tried 4 time(s).
2012-09-18 13:42:43,913 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.160.193:9000. Already tried 5 time(s).
2012-09-18 13:42:44,916 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.160.193:9000. Already tried 6 time(s).
2012-09-18 13:42:45,919 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.160.193:9000. Already tried 7 time(s).
2012-09-18 13:42:46,922 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.160.193:9000. Already tried 8 time(s).
2012-09-18 13:42:47,925 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.160.193:9000. Already tried 9 time(s).
org.apache.hadoop.ipc.Client: Retrying connect to server异常的解决
检查发现是DataNode一直连接不到NameNode。
检查各个节点在etc/hosts中的配置是否有127.0.1.1 xxxxxx。如果有把其屏蔽或者删除,重启各节点即可。
原因:127.0.1.1是debian中的本地回环。这个造成了hadoop解析出现问题。这个设置应该是在做伪分布式的hadoop集群的时候,留下来的。