27.1.1.3 Spark SQL 中ANTLR4的应用
27.1.1.3 Spark SQL 中ANTLR4的应用
ANTLR是一个强大的解析器生成器,可用于读取,处理,执行或翻译结构化文本或二进制文件。它广泛应用于学术界和工业界,建立各种语言,工具和框架。例如:Twitter搜索使用ANTLR进行查询解析,每天有超过2亿次查询。Hive和Pig语言,Hadoop的数据仓库和分析系统都使用ANTLR。Lex Machina使用ANTLR从法律文本中提取信息。Oracle在SQL Developer IDE及其迁移工具中使用ANTLR。NetBeans IDE使用ANTLR解析C ++。Hibernate对象关系映射框架中的HQL语言使用ANTLR构建。
除了这些大型的项目,ANTLR还可以构建各种有用的工具,如配置文件读取器,旧代码转换器,wiki标记渲染器和JSON解析器。ANTLR已经为对象关系数据库映射建立了一些工具,描述了3D可视化,将解析代码注入到Java源代码中,甚至还做了简单的DNA模式匹配示例。
从称为语法的形式语言描述中,ANTLR生成可以自动构建解析树的语言的解析器,解释语法如何匹配输入的数据结构。ANTLR还会自动生成tree walkers,以使用它们访问这些树的节点来执行特定于应用程序的代码。
ANTLR被广泛使用,ANTLR易于理解,强大,灵活,生成人们可读的输出,具有BSD许可证下的完整源代码,因此得到积极的支持。
ANTLR对解析的理论和实践做出了贡献,包括:
- linear approximate lookahead
- semantic and syntactic predicates
- ANTLRWorks
- tree parsing
- LL(*)
- Adaptive LL(*) in ANTLR v4
Terence Parr是ANTLR的发明者,自1989年以来一直在ANTLR工作,他是旧金山大学的计算机科学教授。
ANTLR做两件事:1,将语法转换为Java(或其他目标语言)的语法分析器/词法分析器的工具。2,运行期间生成解析器/词法分析器。如使用ANTLR Intellij插件或ANTLRWorks来运行ANTLR工具,生成的代码仍将需要运行时库。
我们首先需下载并安装ANTLR开发工具插件。然后,获取系统运行环境以运行生成的解析器/词法分析器。以下将在UNIX系统和Windows系统中分别安装部署antlr-4.5.3-complete.jar。
1、 UNIX系统安装部署:
0.安装Java(1.6或更高版本)
1.下载安装antlr的Jar包。
1. $ cd /usr/local/lib
2. $ curl -Ohttp://www.antlr.org/download/antlr-4.5.3-complete.jar
或者从浏览器下载:http://www.antlr.org/download.html,并将其放在位置/usr/local/lib。将antlr-4.5.3-complete.jar加到系统的CLASSPATH:
1. $ exportCLASSPATH=".:/usr/local/lib/antlr-4.5.3-complete.jar:$CLASSPATH"
3.创建ANTLR工具别名和TestRig
1. $ alias antlr4='java-Xmx500M -cp "/usr/local/lib/antlr-4.5.3-complete.jar:$CLASSPATH"org.antlr.v4.Tool'
2. $ alias grun='javaorg.antlr.v4.gui.TestRig'
2、 WINDOWS系统安装部署:
0.安装Java(1.6或更高版本)
1.从http://www.antlr.org/download/下载antlr-4.5.3-complete.jar保存到windows本地目录中,如C:\Javalib
2.将antlr-4.5-complete.jar到CLASSPATH,或者使用系统属性对话框>环境变量>创建或附加到CLASSPATH变量
1. SETCLASSPATH=.;C:\Javalib\antlr-4.5.3-complete.jar;%CLASSPATH%
2. 使用批处理文件或doskey命令为ANTLR工具和TestRig创建快捷命令:
批处理文件(系统PATH中的目录)antlr4.bat和grun.bat
1. java org.antlr.v4.Tool %*
2. java org.antlr.v4.gui.TestRig%*
或者使用doskey命令:
3. doskey antlr4=java org.antlr.v4.Tool $*
4. doskey grun =javaorg.antlr.v4.gui.TestRig $*
3、 ANTLR测试安装。
可以直接启动org.antlr.v4.Tool:
1. $ java org.antlr.v4.Tool
2. ANTLR Parser Generator Version4.5.3
3. -o ___ specify output directorywhere all output is generated
4. -lib ___ specify location of.tokens files
5. ...
或者在java上使用-jar选项:
1. $ java -jar/usr/local/lib/antlr-4.5.3-complete.jar
2. ANTLR Parser Generator Version4.5.3
3. -o ___ specify output directorywhere all output is generated
4. -lib ___ specify location of.tokens files
5. ...
4、 ANTLR 的第一个例子。
用ANTLR开发一个语法分析器可以分成3个步骤:
- · 写出要分析内容的文法。
- · 用ANTLR生成相对该文法的语法分析器的代码。
- · 编译运行语法分析器。
我们首先在临时目录中,将以下语法放在Hello.g4文件中:Hello.g4
1. // 定义一个名称为Hello的文法解析器
2. grammar Hello;
3. r : 'hello' ID ; // 匹配关键词 hello,之后跟随标识符
4. ID : [a-z]+ ; // 匹配小写的标识符
5. WS : [ \t\r\n]+ -> skip ; //忽略空格,tab符,换行符Hello.g4文件的第一行grammarHello的Hello为文法的名称,Hello与文件名一致,文件名后缀以.g4结尾。Hello.g4第二行开始是文法定义部分,文法是用扩展的巴科斯范式(EBNF1)推导式来描述的,每一行都是一个规则(rule)或叫做推导式、产生式,每个规则的左边是文法中的一个名字,代表文法中的一个抽象概念。中间用一个“:”表示推导关系,右边是该名字推导出的文法形式。
Hello.g4文法的规则定义:
· r : 'hello' ID ; 代表表达式语句,表示以'hello'开头的字符串,'hello'之后跟随的字符需符合表达式ID的规则,即任意小写字母的字符串。表达式本身是合法的语句,表达式也可以出现在赋值表达式中组成赋值语句,语句以“;”字符结束。
· ID : [a-z]+ ; 以小写形式表达的词法描述部分,ID表示变量由一个或多个小写字母组成。
· WS : [ \t\r\n]+ -> skip ; WS表示空白,它的作用是过滤掉空格、TAB符号、回车换行的无意义字符。skip的作用是跳过空白字符。接下来我们运行ANTLR工具,使用antlr4批处理文件来编译文法。
1. $ cd /tmp
2. $ antlr4 Hello.g4
3. $ javac Hello*.java然后进行测试,antlr4提供了一个可以测试文法的工具类java org.antlr.v4.gui.TestRig,使用TestRig来测试新开发的文法,使用grun批处理文件测试运行:
1. $ grun Hello r -tree
2. hello parrt
3. ^D
4. (r hello parrt)
5. (That ^D means EOF on unix;it's ^Z in Windows.) The -tree option prints the parse tree in LISP notation.
6. It's nicer to look at parsetrees visually.
7. $ grun Hello r -gui
8. hello parrt
9. ^D
使用-gui参数可以让工具类显示一个窗口来显示解析后的树形结构。运行结果如图 27- 13所示。弹出一个对话框,显示r匹配关键字hello后跟标识符parrt。
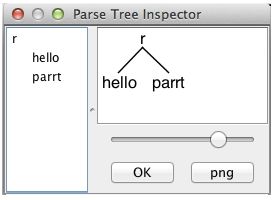
图 27- 13 antlr4运行结果示意图
Spark SQL 中ANTLR4的应用:
Spark 1.x版本使用的是scala原生的parser语法解析器,Spark2.x版本不同于Spark 1.x版本的parser语法解析器,Spark 2.x版本使用的是第三方语法解析器工具ANTLR4。
Spark2.x SQL语句的解析采用的是ANTLR 4,ANTLR 4根据spark-2.1.1\sql\catalyst\src\main\antlr4\org\apache\spark\sql\catalyst\parser\SqlBase.g4文件自动解析生成的Java类:词法解析器SqlBaseLexer和语法解析器SqlBaseParser。
SqlBaseLexer和SqlBaseParser均是使用ANTLR 4自动生成的Java类。使用这两个解析器将SQL语句解析成了ANTLR 4的语法树结构ParseTree。然后在parsePlan中,使用AstBuilder(AstBuilder.scala)将ANTLR 4语法树结构转换成catalyst表达式逻辑计划logical plan。
ANTLR4自动生成Spark SQL语法解析器Java代码SqlBaseParser类,SqlBaseParser类代码约15210行。摘录部分代码如下:
SqlBaseParser.java源码:
1. @SuppressWarnings({"all","warnings", "unchecked", "unused","cast"})
2. public class SqlBaseParser extends Parser {
3. static {RuntimeMetaData.checkVersion("4.7", RuntimeMetaData.VERSION); }
4.
5. protected static finalDFA[] _decisionToDFA;
6. protected static finalPredictionContextCache _sharedContextCache =
7. newPredictionContextCache();
8. public static final int
9. T__0=1, T__1=2,T__2=3, T__3=4, T__4=5, T__5=6, T__6=7, SELECT=8, FROM=9,
10. ……
11. public static final int
12. RULE_singleStatement= 0, RULE_singleExpression = 1, RULE_singleTableIdentifier = 2,
13. ……
14. public static final String[] ruleNames = {
15. "singleStatement","singleExpression", "singleTableIdentifier","singleDataType",
16. ……
17. private static finalString[] _LITERAL_NAMES = {
18. null,"'('", "')'", "','", "'.'","'['", "']'", "':'", "'SELECT'","'FROM'",
19. "'ADD'","'AS'", "'ALL'", "'DISTINCT'","'WHERE'", "'GROUP'", "'BY'",
20. "'GROUPING'","'SETS'", "'CUBE'", "'ROLLUP'","'ORDER'", "'HAVING'", "'LIMIT'",
21. "'AT'","'OR'", "'AND'", "'IN'", null, "'NO'","'EXISTS'", "'BETWEEN'",
22. ……
23. public SqlBaseParser(TokenStream input) {
24. super(input);
25. _interp = newParserATNSimulator(this,_ATN,_decisionToDFA,_sharedContextCache);
26. }
27. ……
28. public final StatementContext statement() throws RecognitionException {
StatementContext _localctx = new StatementContext(_ctx, getState());
enterRule(_localctx, 8, RULE_statement);
int _la;
try {
int _alt;
setState(753);
_errHandler.sync(this);
switch ( getInterpreter().adaptivePredict(_input,92,_ctx) ) {
case 1:
_localctx = new StatementDefaultContext(_localctx);
enterOuterAlt(_localctx, 1);
{
setState(192);
query();
}
break;
case 2:
_localctx = new UseContext(_localctx);
enterOuterAlt(_localctx, 2);
{
setState(193);
match(USE);
setState(194);
((UseContext)_localctx).db = identifier();
}
break;
case 3:
_localctx = new CreateDatabaseContext(_localctx);
enterOuterAlt(_localctx, 3);
{
setState(195);
match(CREATE);
setState(196);
match(DATABASE);
setState(200);
_errHandler.sync(this);
switch ( getInterpreter().adaptivePredict(_input,0,_ctx) ) {
case 1:
{
setState(197);
match(IF);
setState(198);
match(NOT);
setState(199);
match(EXISTS);
}
break;
}
setState(202);
identifier();
setState(205);
_errHandler.sync(this);
_la = _input.LA(1);
if (_la==COMMENT) {
{
setState(203);
match(COMMENT);
setState(204);
((CreateDatabaseContext)_localctx).comment = match(STRING);
}
}
setState(208);
_errHandler.sync(this);
_la = _input.LA(1);
.....
switch (_input.LA(1)) {
case SELECT:
case FROM:
case ADD:
case AS:
case ALL:
case DISTINCT:
case WHERE:
case GROUP:
case BY:
case GROUPING:
case SETS:
case CUBE:
case ROLLUP:
case ORDER:
case HAVING:
case LIMIT:
case AT:
case OR:
case AND:
case IN:
case NOT:
case NO:
case EXISTS:
case BETWEEN:
case LIKE:
case RLIKE:
case IS:
case NULL:
case TRUE:
case FALSE:
case NULLS:
case ASC:
case DESC:
case FOR:
case INTERVAL:
case CASE:
case WHEN:
case THEN:
case ELSE:
case END:
case JOIN:
case CROSS:
case OUTER:
case INNER:
case LEFT:
case SEMI:
case RIGHT:
case FULL:
case NATURAL:
case ON:
case LATERAL:
case WINDOW:
case OVER:
case PARTITION:
case RANGE:
case ROWS:
case UNBOUNDED:
case PRECEDING:
case FOLLOWING:
case CURRENT:
case FIRST:
case LAST:
case ROW:
case WITH:
case VALUES:
case CREATE:
case TABLE:
case VIEW:
case REPLACE:
case INSERT:
case DELETE:
case INTO:
case DESCRIBE:
case EXPLAIN:
case FORMAT:
case LOGICAL:
case CODEGEN:
case CAST:
case SHOW:
case TABLES:
case COLUMNS:
case COLUMN:
case USE:
case PARTITIONS:
case FUNCTIONS:
case DROP:
case UNION:
case EXCEPT:
case SETMINUS:
case INTERSECT:
case TO:
case TABLESAMPLE:
case STRATIFY:
case ALTER:
case RENAME:
case ARRAY:
case MAP:
case STRUCT:
case COMMENT:
case SET:
case RESET:
case DATA:
case START:
case TRANSACTION:
case COMMIT:
case ROLLBACK:
case MACRO:
case IF:
case DIV:
case PERCENTLIT:
case BUCKET:
case OUT:
case OF:
case SORT:
case CLUSTER:
case DISTRIBUTE:
case OVERWRITE:
case TRANSFORM:
case REDUCE:
case USING:
case SERDE:
case SERDEPROPERTIES:
case RECORDREADER:
case RECORDWRITER:
case DELIMITED:
case FIELDS:
case TERMINATED:
case COLLECTION:
case ITEMS:
case KEYS:
case ESCAPED:
case LINES:
case SEPARATED:
case FUNCTION:
case EXTENDED:
case REFRESH:
case CLEAR:
case CACHE:
case UNCACHE:
case LAZY:
case FORMATTED:
case GLOBAL:
case TEMPORARY:
case OPTIONS:
case UNSET:
case TBLPROPERTIES:
case DBPROPERTIES:
case BUCKETS:
case SKEWED:
case STORED:
case DIRECTORIES:
case LOCATION:
case EXCHANGE:
case ARCHIVE:
case UNARCHIVE:
case FILEFORMAT:
case TOUCH:
case COMPACT:
case CONCATENATE:
case CHANGE:
case CASCADE:
case RESTRICT:
case CLUSTERED:
case SORTED:
case PURGE:
case INPUTFORMAT:
case OUTPUTFORMAT:
case DATABASE:
case DATABASES:
case DFS:
case TRUNCATE:
case ANALYZE:
case COMPUTE:
case LIST:
case STATISTICS:
case PARTITIONED:
case EXTERNAL:
case DEFINED:
case REVOKE:
case GRANT:
case LOCK:
case UNLOCK:
case MSCK:
case REPAIR:
case RECOVER:
case EXPORT:
case IMPORT:
case LOAD:
case ROLE:
case ROLES:
case COMPACTIONS:
case PRINCIPALS:
case TRANSACTIONS:
case INDEX:
case INDEXES:
case LOCKS:
case OPTION:
case ANTI:
case LOCAL:
case INPATH:
case CURRENT_DATE:
case CURRENT_TIMESTAMP:
case IDENTIFIER:
case BACKQUOTED_IDENTIFIER:
{
setState(629);
qualifiedName();
}
break;
case STRING:
{
setState(630);
((ShowFunctionsContext)_localctx).pattern = match(STRING);
}
break;
default:
throw new NoViableAltException(this);
}
}
}
.......
public final TablePropertyKeyContext tablePropertyKey() throws RecognitionException {
TablePropertyKeyContext _localctx = new TablePropertyKeyContext(_ctx, getState());
enterRule(_localctx, 44, RULE_tablePropertyKey);
int _la;
try {
setState(1103);
_errHandler.sync(this);
switch (_input.LA(1)) {
case SELECT:
case FROM:
case ADD:
case AS:
case ALL:
case DISTINCT:
case WHERE:
case GROUP:
case BY:
case GROUPING:
case SETS:
case CUBE:
case ROLLUP:
case ORDER:
case HAVING:
case LIMIT:
case AT:
case OR:
case AND:
case IN:
case NOT:
case NO:
case EXISTS:
case BETWEEN:
case LIKE:
case RLIKE:
case IS:
case NULL:
case TRUE:
case FALSE:
case NULLS:
case ASC:
case DESC:
case FOR:
case INTERVAL:
case CASE:
case WHEN:
case THEN:
case ELSE:
case END:
case JOIN:
case CROSS:
case OUTER:
case INNER:
case LEFT:
case SEMI:
case RIGHT:
case FULL:
case NATURAL:
case ON:
case LATERAL:
case WINDOW:
case OVER:
case PARTITION:
case RANGE:
case ROWS:
case UNBOUNDED:
case PRECEDING:
case FOLLOWING:
case CURRENT:
case FIRST:
case LAST:
case ROW:
case WITH:
case VALUES:
case CREATE:
case TABLE:
case VIEW:
case REPLACE:
case INSERT:
case DELETE:
case INTO:
case DESCRIBE:
case EXPLAIN:
case FORMAT:
case LOGICAL:
case CODEGEN:
case CAST:
case SHOW:
case TABLES:
case COLUMNS:
case COLUMN:
case USE:
case PARTITIONS:
case FUNCTIONS:
case DROP:
case UNION:
case EXCEPT:
case SETMINUS:
case INTERSECT:
case TO:
case TABLESAMPLE:
case STRATIFY:
case ALTER:
case RENAME:
case ARRAY:
case MAP:
case STRUCT:
case COMMENT:
case SET:
case RESET:
case DATA:
case START:
case TRANSACTION:
case COMMIT:
case ROLLBACK:
case MACRO:
case IF:
case DIV:
case PERCENTLIT:
case BUCKET:
case OUT:
case OF:
case SORT:
case CLUSTER:
case DISTRIBUTE:
case OVERWRITE:
case TRANSFORM:
case REDUCE:
case USING:
case SERDE:
case SERDEPROPERTIES:
case RECORDREADER:
case RECORDWRITER:
case DELIMITED:
case FIELDS:
case TERMINATED:
case COLLECTION:
case ITEMS:
case KEYS:
case ESCAPED:
case LINES:
case SEPARATED:
case FUNCTION:
case EXTENDED:
case REFRESH:
case CLEAR:
case CACHE:
case UNCACHE:
case LAZY:
case FORMATTED:
case GLOBAL:
case TEMPORARY:
case OPTIONS:
case UNSET:
case TBLPROPERTIES:
case DBPROPERTIES:
case BUCKETS:
case SKEWED:
case STORED:
case DIRECTORIES:
case LOCATION:
case EXCHANGE:
case ARCHIVE:
case UNARCHIVE:
case FILEFORMAT:
case TOUCH:
case COMPACT:
case CONCATENATE:
case CHANGE:
case CASCADE:
case RESTRICT:
case CLUSTERED:
case SORTED:
case PURGE:
case INPUTFORMAT:
case OUTPUTFORMAT:
case DATABASE:
case DATABASES:
case DFS:
case TRUNCATE:
case ANALYZE:
case COMPUTE:
case LIST:
case STATISTICS:
case PARTITIONED:
case EXTERNAL:
case DEFINED:
case REVOKE:
case GRANT:
case LOCK:
case UNLOCK:
case MSCK:
case REPAIR:
case RECOVER:
case EXPORT:
case IMPORT:
case LOAD:
case ROLE:
case ROLES:
case COMPACTIONS:
case PRINCIPALS:
case TRANSACTIONS:
case INDEX:
case INDEXES:
case LOCKS:
case OPTION:
case ANTI:
case LOCAL:
case INPATH:
case CURRENT_DATE:
case CURRENT_TIMESTAMP:
case IDENTIFIER:
case BACKQUOTED_IDENTIFIER:
enterOuterAlt(_localctx, 1);
{
setState(1094);
identifier();
setState(1099);
_errHandler.sync(this);
_la = _input.LA(1);
while (_la==T__3) {
{
{
setState(1095);
match(T__3);
setState(1096);
identifier();
}
}
setState(1101);
_errHandler.sync(this);
_la = _input.LA(1);
}
}
break;
case STRING:
enterOuterAlt(_localctx, 2);
{
setState(1102);
match(STRING);
}
break;
default:
throw new NoViableAltException(this);
}
}
catch (RecognitionException re) {
_localctx.exception = re;
_errHandler.reportError(this, re);
_errHandler.recover(this, re);
}
finally {
exitRule();
}
return _localctx;
}
为学犹掘井,井愈深土愈难出,若不快心到底,岂得见泉源乎?——张九功