CS 188 Project3(RL) Q10:Approximate Q-Learning
实现一个近似的Q-learning学习代理,它学习状态特征的权重,其中许多状态可能共享相同的特征。在qlearningAgents.py中的ApproximateQAgent类中编写实现,它是PacmanQAgent的子类。
注:近似Q-learning学习假设在状态和动作对上存在一个特征函数f(s,a),它产生一个向量f1(s,a) .. fi(s,a) .. fn(s,a)特征值。我们在featureExtractors.py中提供特征函数,特征向量是util.Counter(像字典)对象,包含非零的特征和值对;所有省略的特征都具有值零。
近似Q-function 函数的形式如下:
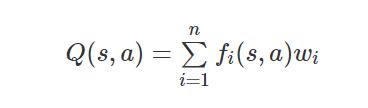
其中每个权重wi与特征函数fi(s,a)关联,在代码中,您应该将权重向量作为字典映射特征(特性提取器返回)实现为权重值。您将更新权重向量,类似于更新Q-values值的方式:
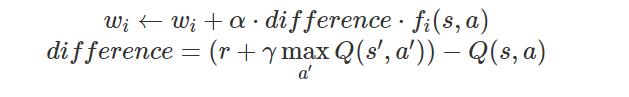
请注意差距difference与正常的Q-learning学习相同,并且R是有经验的奖励。默认情况下,ApproximateQAgent 近似代理使用IdentityExtractor,它为每对(状态、动作)分配一个特征。使用这个特征提取器,您的近似Q-learning代理应该与PacmanQAgent工作相同。
您可以使用以下命令测试:
python pacman.py -p ApproximateQAgent -x 2000 -n 2010 -l smallGrid 
重要提示:ApproximateQAgent是QLearningAgent的一个子类,因此它共享一些方法,如getAction。确保QLearningAgent中的方法调用GetQValue而不是直接访问 Q-values值,这样当您在近似代理中重写GetQValue时,新的近似 Q-values 值将用于计算动作。一旦您确信您的近似学习能够正确地使用标识特征,就可以使用我们的自定义特征提取器运行您的近似Q-Learning代理,它可以轻松地学习如何取胜:
python pacman.py -p ApproximateQAgent -a extractor=SimpleExtractor -x 50 -n 60 -l mediumGrid 
对于您的近似代理来说,更大的布局应该是没有问题的。(警告:这可能需要几分钟的训练时间)
python pacman.py -p ApproximateQAgent -a extractor=SimpleExtractor -x 50 -n 60 -l mediumClassic 如果没报错,那么您的Q-Learning代理几乎每次使用这些简单的功能获胜,即使只有50个训练游戏。
评分:我们将运行您的近似Q-Learning代理,当每个都有相同的测试集时,检查它学习是否与我们的参考实现相同的Q-values值和特征权重。
python autograder.py -q q10ApproximateQAgent代码:
class ApproximateQAgent(PacmanQAgent):
"""
ApproximateQLearningAgent
You should only have to overwrite getQValue
and update. All other QLearningAgent functions
should work as is.
"""
def __init__(self, extractor='IdentityExtractor', **args):
#设置特征提取器,默认将state,action的特征值设置为1
self.featExtractor = util.lookup(extractor, globals())()
#初始化默认参数:学习率alpha,探索率epsilon,折扣率gamma,训练次数numTraining
PacmanQAgent.__init__(self, **args)
#设置权重变量
self.weights = util.Counter()
def getWeights(self):
return self.weights
def getQValue(self, state, action):
"""
Should return Q(state,action) = w * featureVector
where * is the dotProduct operator
"""
"*** YOUR CODE HERE ***"
#util.raiseNotDefined()
#权重系数点乘特征向量计算状态执行下一个动作的Q值!
#设置Q value 初始值
qValue = 0.0
#特征字典的key值是(state,action),其中state是GameState类实例。
features = self.featExtractor.getFeatures(state,action)
#遍历特征字典的key值,计算点乘以后的Q value值
for key in features.keys():
qValue =qValue + self.weights[key]*features[key]
# 返回Q value值
return qValue
def update(self, state, action, nextState, reward):
"""
Should update your weights based on transition
更新权重!!!
"""
"*** YOUR CODE HERE ***"
#util.raiseNotDefined()
#基于迁移转换transition(状态,动作,下一个状态)更新权重,传入的state是一个GameState类实例
#计算差距
difference = reward + self.discount * self.getValue(nextState) - self.getQValue(state,action)
#提取特征字典
features =self.featExtractor.getFeatures(state,action)
#遍历特征字典的key值,更新权重
for key in features.keys():
self.weights[key]=self.weights[key]+self.alpha * difference * features[key]
def final(self, state):
"Called at the end of each game."
# call the super-class final method
#在游戏结束的时候调用,调用父类的方法,将状态的得分减去最后状态的得分计算出deltaReward,
#然后再根据最后的状态,最后的动作,前一个状态,deltaReward进行一次迁移转换观察,
#更新权重,然后更新奖励accumTrainRewards,打印记录训练完成、耗时等相关的日志
PacmanQAgent.final(self, state)
# did we finish training?
#判断是否完成了训练?
if self.episodesSoFar == self.numTraining:
# you might want to print your weights here for debugging
"*** YOUR CODE HERE ***"
pass
#print(self.weights)
欢迎关注微信公众号:“从零起步学习人工智能”!