Cascade R-CNN论文阅读 最详细易懂
Cascade R-CNN
现在的目标检测所存在的问题
在目标检测中,我们通常使用IoU(候选框和原标记框重叠度:https://blog.csdn.net/iamoldpan/article/details/78799857)的阈值来定义正负面,一般情况下会采用一个较低的阈值u=0.5来进行区分判别,但是在u=0.5的时候会存在很多的误判(noisy detections),如图
产生这么多误判的原因是因为阈值太低了,但是为什么又不能用高阈值u=0.7来进行检验呢?这是因为阈值过高,而导致了正样本数太少,容易导致其产生过拟合(过拟合和欠拟合:https://blog.csdn.net/weixin_42575020/article/details/82949285)缺少泛化能力
提高阈值训练所存在的问题:
-
由于正样本数减少而导致的过拟合
-
在train和inference使用不一样的阈值很容易导致不匹配(或者可以理解为在train和inference的时候他们的最优阈值是不一样的,最优阈值即效果最好的时候的阈值)
所以这篇论文就是去解决提高阈值后存在的问题
思路的简介
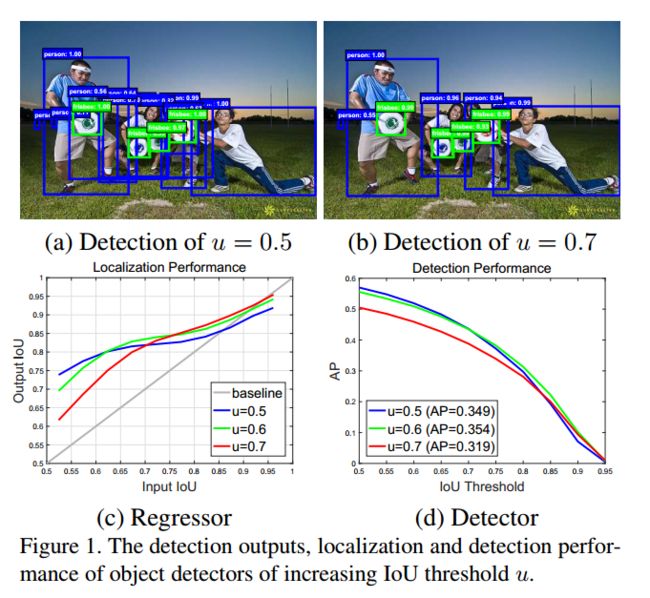
这是他们所做的一组实验测验,
先看左图(c),横轴是proposal(使用特定算法提取出的可能是目标的区域 )的IoU,纵轴是经过Bounding-box regression(边框回归:https://blog.csdn.net/elaine_bao/article/details/60469036)得到的新的IoU,不同的线条代表不同阈值训练出来的detector,新的IoU越高说明detector进行回归的性能越好。
于是就发现:纵轴(回归后)0.55~0.6的范围内横轴(proposal)阈值为0.5的detector性能最好,在0.6~0.75阈值为0.6的detector性能最佳,而到了0.75之后就是阈值为0.7的detector了(当然,这个其实也不是特别准确,只是大约估计)
这就说明了一个问题:只有proposal自身的阈值和训练器训练用的阈值较为接近的时候,训练器性能最好,也就是上述问题所提到的问题2:在train和inference使用不一样的阈值很容易导致不匹配
于是作者认为单一的阈值训练出的检测器效果有限,但是我们有不能直接提高阈值去强行提升效果,否则就会出现问题1的情况:由于正样本数减少而导致的过拟合
为了说明问题1,作者使用右图来进行说明,横轴为IoU的阈值,纵轴为AP(可以理解为精确度平均值:https://blog.csdn.net/qq_41994006/article/details/81051150)即AP可以体现一个dector的检测效果,该图说明在u=0.6时,效果微微高于u=0.5,但是到u=0.7的时候,效果反而是最低的,其原因是训练样本大大减少,过拟合现象已经特别严重,所以他对于样本的要求会非常高。
上述两个问题综合起来就成了:
如何在保证样本数不减少的情况下提高阈值进行检测?
作者机智的发现了,上边左图,几乎所有的线条都在灰色的对角线以上,这说明:
绝大部分的proposal在经过Bounding-box regression(边框回归)后,其IoU必然是增加的
于是作者根据这个现象,采用级联的方式,前一个检测模型的输出作为后一个检测模型的输入,因此是stage by stage的训练方式,而且越往后的检测模型,其界定正负样本的IOU阈值是不断上升的。
相关工作
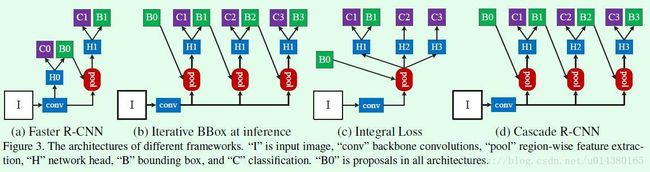
R-CNN构架
(a)Faster R-CNN(https://blog.csdn.net/young_gy/article/details/79155011)引入RPN网络,成为two stage类型网络的基础,所以用它说明下上图吧,H0是proposal sub-network(提议子网络)就是初步确定的一些初步检验假设,即目标提议。这些假设由感兴趣的区域检测子网络H1处理,表示为检测头,每个假设都有一个分数C和一个边界框B。
在这个地方列举下目标检测的常规定位损失函数吧:
其中b为边界框b=(bx,by,bw,bh),边框回归的任务就是让回归量f(x,b)讲候选框b回归到g中。所以(1)就是他的定位损失

处理定位损失之外,还有一个是分类损失:

分类器是指定图像的函数h(x)将x分类到M+1个类中,其中类0表示背景,其他的要检测对象是什么。y为类标签。给定一个训练集(xi,yi)进行学习,最小化分类损失来进行学习。
当然文中也提及了YOLO和SSD这种高效one-stage的网络,他们具有高效的计算能力,但是准确度通产低于two stage类型,但是最近RetinaNet被提出用于解决密集检测中的极端背景类别不平衡问题(我也不知道他提及这个干啥,可能是像推荐这篇文章吧)
(b)迭代式BBox回归,就是前一个检测模型回归得到的bbox坐标初始化下一个检测模型的bbox,然后继续回归,这样迭代三次后得到结果。但是他采用的还是同一个阈值。
用公式可以理解为:

所以他有两个比较明显的缺点:(可以不看,只是说他的不足之处)
-
用(c)regressor图中可以知道,每次迭代都使用相同阈值输出的IoU不在输入Iou附近,出现了问题2:在train和inference使用不一样的阈值很容易导致不匹配。所以迭代效果不会有太大提升
-
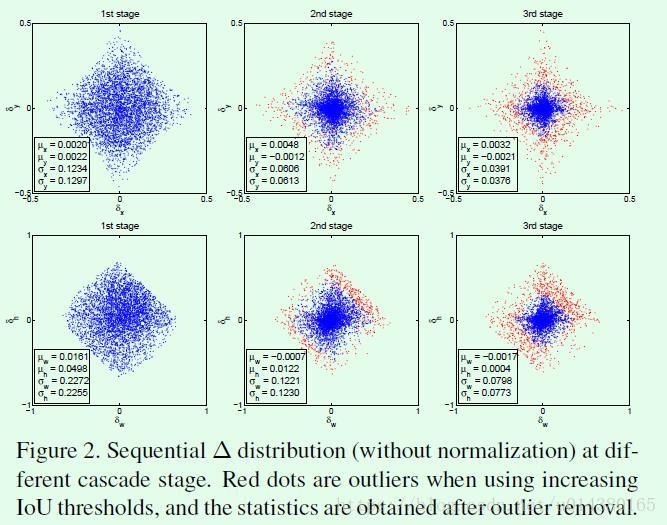
作者对这种做法进行测试,Figure2(下面那个图),发现在bbox回归在不同阶段的四个回归值分布情况(蓝色的点),可以发现在不同阶段这四个值得分布差异较大,所以已成不变的检测模型难以在改变中达到最优效果,再进行补充说明下吧,在回归后detector会改变样本分布,下图就是体现样本的分布的一个效果图
(c)Integral Loss其实是一个分类器集合,使用不同的IOU阈值进行分类,虽然针对于各种情况分类的思路很好,而且有有效的刷高了COCO数据集的实验结果,但是他还是降低了正样本的数量,对于阈值很高的情况下,过拟合风险问题依然存在。
所以作者接受了(b)的级联思想和(c)的利用不同阈值来进行处理的想法,形成了(d)级联RCNN结构。
Cascade R-CNN
于是就采用了,这样的做法,对(3)进行了优化
用多个专用回归量{fT,fT-1,...,f1}针对不同阶段重采样进行优化,让每个阶段都几乎是最优的
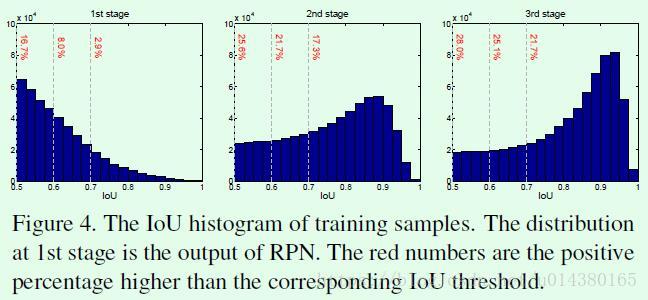
为了说明这种级联方式返回后的样本数,作者还进行了一些测试
他的损失函数是:![]()
定位损失+分类损失,其中:![]() 也就是前一级回归后的框
也就是前一级回归后的框
实验结果
作者总共用了4个stage:1个RPN+3个检测器(阈值设定为0.5,0.6,0.7)从Figure4结果显示,IoU逐级上升,所以阈值也不一样。
当然阈值的设定是有理有据的,所以这个地方作者也例举出了一些图表和性能的对比:

图五(a)是表示级联和单独训练的检测器性能(虚线是级联后的效果)(b)就是将groud truth加入proposal set的效果,相当于能达到的最好效果
图六是各个阶段不同阈值训练出来的不同的效果

然后总之效果很好:
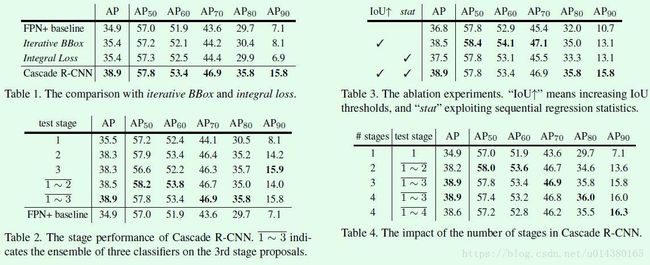
这是关于cascade R-CNN和Iterative bbox、Integral loss的对比
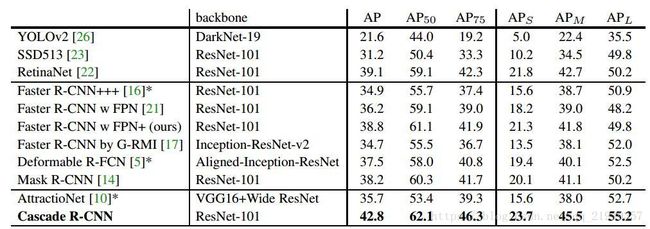
精确度的比较
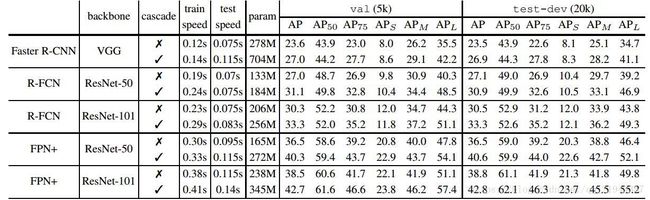
训练、调试时间、参数量的比较
本人纯属小白,还望大神们多提意见!