如何运行Faster RCNN的tensorflow代码
0.目的
刚刚学习faster rcnn目标检测算法,在尝试跑通github上面Xinlei Chen的tensorflow版本的faster rcnn代码时候遇到很多问题(我真是太菜),代码地址如下:
https://github.com/endernewton/tf-faster-rcnn
1. 运行环境配置
代码的README里面说明了,环境要求既有是这个git里面的,还有就是rbg的caffe代码中也有了一些环境。基本上包括:
python2.7
CUDA(并行计算库)>=6.0
cudnn(深度学习库)
cython,
opencv-python
easydict=1.6
当然这只是跑通代码的环境,并没有那么苛刻的。
1.1 检查环境
检查环境的目的是为了安装TensorFlow,首先是
1.1.1 Linux 内核和发行版
需要查看 linux内核和发行版,来确定后续一些软件的安装版本选择。《如何查看LINUX发行版的名称及其版本号》:https://www.qiancheng.me/post/coding/show-linux-issue-version
查看Linux内核
| 1 |
|
查看Linux发行版
| 1 |
|

我用的是 centos,在运行demo期间没发现什么问题,但最好是用Ubutu 14或者16吧
1.1.2 检查cuda 和cudnn的版本
chen 推荐的是 TensorFlow 的 r1.2 版本,应该是安装r1.2推荐的cuda和cudnn,但是因为我没有服务器的root权限,无法更改cuda和cudnn,所以只能选择一个和本机环境相对应的tensorflow版本了。
注意这里如果不安装匹配的版本,可能会出现cudnn库找不到的情况,(别问我怎么知道的),https://stackoverflow.com/questions/42013316/after-building-tensorflow-from-source-seeing-libcudart-so-and-libcudnn-errors,如果有root权限的,最好是装r1.2版本的,当然要查好r1.2支持的cuda和cudnn,方法也在下面。
查看cuda的版本:http://blog.csdn.net/zhangjunhit/article/details/76532196
| 1 |
|
查看cudnn版本:
| 1 |
|

我的cuda=8,cudnn=6
到tensorflow 的官网上查对应的TF版本:https://www.tensorflow.org/install/install_sources#common_installation_problems

如果没有GPU的就安装cpu版本,README里面说cpu也是能运行的,我没试。
1.2 安装Anaconda 和TensorFlow
tensorflow r1.4的安装教程:https://www.tensorflow.org/versions/r1.4/install/install_linux?hl=zh-cn,我是按照Anaconda的方法弄的,比较简单。
因为我的系统上面安装了anaconda,之前装了python3。为了方便,直接用anaconda新开了一个环境,装了python2.7。教程:https://www.jianshu.com/p/d2e15200ee9b
创建环境:
| 1 |
|
进入环境:
| 1 |
|
![]()
前面这样显示就对了(我的名字叫python27,你的应该是tensorflow)
使用pip安装tensorflow:
pip install --ignore-installed --upgrade tfBinaryURL
注意这里的 tfBinaryURL 是 URL of the TensorFlow Python package ,但这里面都是谷歌的镜像,要是没挂科学上网的话应该是访问不到的,我是用的阿里的镜像:http://mirrors.aliyun.com/pypi/simple,自己找合适的版本,我用的是http://mirrors.aliyun.com/pypi/packages/68/b4/8731e144a68a6044b8eba47f51f0a862c696b0c016c8512ca2aa3916f62a/tensorflow_gpu-1.4.0rc1-cp27-cp27mu-manylinux1_x86_64.whl。
更多镜像在:https://www.jianshu.com/p/502638407add
输入上面的命令之后就成功了,运行了一下官方的测试:
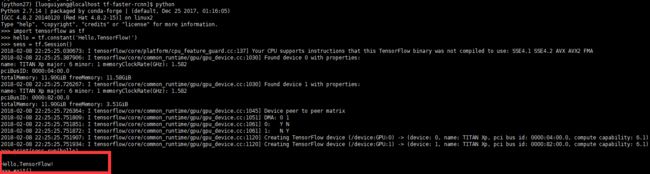
成功输出:Hello,TensorFlow!
1.3 安装其他依赖
保持在tensorflow这个环境中,继续用pip安装cython, opencv-python, easydict这三个库。
| 1 2 3 |
|

链接cython模块的时候出现了一个警告,具体什么原因我也不太清楚,就暂时没有管它,最后也是能运行demo的。
| 1 2 3 4 5 6 7 8 9 10 |
|
3 下载代码和数据
到这一步,按照README里面的提示一步一步走就应该没问题了(如果在本地测试的话)。
1、clone github的仓库
| 1 |
|
2、更新GPU的架构配置,到setup.py中找到 -arch 这个参数,改成自己的GPU架构就行了
| 1 2 3 |
|
对应的配置如右图,github里面可能会对一些其他的显卡更新参数。 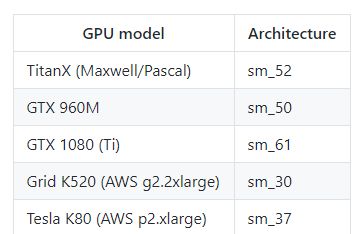
3、链接cython 模块,注意这也是在上一步那个lib 文件夹中进行的
| 1 2 3 |
|
4、安装 Python COCO API,这是为了使用COCO数据库
| 1 2 3 4 5 |
|
4 运行Demo 和测试预训练模型
1、下载预训练模型
| 1 2 |
|
README里面也说了,下载链接可能会失效,sh文件里面给了一个备用链接也是不管用的,但是readme里面还给了备份的Google Drive的地址,我把其中的要用的模型 voc_0712_80k-110k.tgz 这个文件手动下载了(百度云备份:https://pan.baidu.com/s/1kWkF3fT),下载之后放到 data文件夹中就行,(但是md5sum校验值对不上,估计是下载地址不一样的问题,也暂时忽略吧),运行以下命令解压:
| 1 |
|
2、建立预训练模型的软连接
| 1 2 3 4 5 6 |
|
3、运行以下代码就能测试demo了,主义是在tf-faster-rcnn 这个根文件夹中运行
| 1 2 3 |
|
这里还有一个问题,demo里面一个文件 import matlibplot.pyplot ,这时候如果是用终端连接的服务器的话,可能会出现DISPLAY 变量未设置这个bug,echo $DISPLAY 命令这时候肯定是什么不显示的。错误如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|
这是因为matplotlib 输出的图像没有输出出来,有两种方法:
解决方法(1)设置X11转发,具体方法Google一下,因为我的服务器没有配置Xauth,我也没有root权限,所以对我不适用了
解决方法(2)改代码,不要让图像show了,而是把图像保存起来。错误里面可以看出引入matplotlib 的是 ./tools/demo.py 这个文件,教程:http://rootlu.com/blog/2017/10/08/MatplotlibInLinux.html/
更改了两处


改完之后,图片就保存在 tf-faster-rcnn 这里了,下载下来是这样的(没仔细改代码,只保存了一幅)
基础的demo就可以运行了。后面调试的部分研究明白了再补上。