无监督学习:深度自编码器
1. 从 PCA 开始
使用PCA对数据进行降维和重构的过程大致上如下图所示

首先将输入的数据乘以一个矩阵得到降维之后的结果,之后再将降维之后的数据乘以之前权重矩阵的转置,恢复得到近似的原始图像。在这个过程中,我们希望输入层与输出层的图像之间越相似越好。这个过程也已通过NN的方式实现,其中 Input layer 到 hidden layer 的过程是编码(encode)过程,而从 hidden layer 到 Output layer 的过程是解码的过程(decode)。因为 hidden layer 得到的结果往往会比原始的维数小,就像一个瓶子的瓶颈一样狭窄,所以也将 hidden layer 称为 bottleneck layer 。
一个很自然的深度自编码器的想法是如下所示的过程

其中有两点需要注意,首先这里认为前后的权重矩阵是对称的,然而不是对称的也没过关系,因为用的是NN的方法而不是PCA的方法,不必满足前后的对称慈宁宫;其次这个模型原先需要采用RBM的方法逐层初始化,以现在训练NN的技术也可以不用了,所以上面的训练过程和一般的神经网络并没有什么区别。
下面是一个使用PCA自编码和使用深度神经网络自编码的实验对比结果
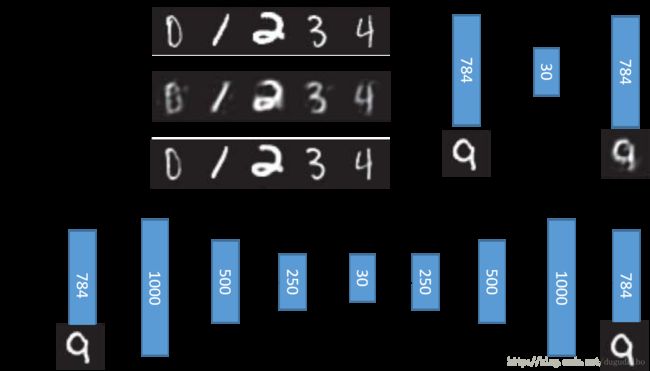
我们可以看到都是编码到30维之后再进行解码,深度自编码器的效果比PCA的效果要好很多。其中有一点需要注意,在使用神经网络的时候,第一个隐层的神经元的个数是多于输入层神经元的个数。
如果用两种方法都将数据降低至2维进行表示,可以看到实验结果如下

可以看到PCA得到的结果将不同种类的数据区分的不是很开,而深度自编码器可以将数据区分的比较开。但是与之前的t-SNE相比还是有一定差距的。
2. 文字检索或者图片检索
将图片或者文字进行深度自编码之后,将它们编码的结果作为它们的特征,将输入的图像或者文字经过同样的编码,在编码后的空间比较相似性,完成文字搜索或者图片搜索。
3. 预训练DNN
在之前训练DNN的技术没有现在这么先进,所以需要通过预训练的方法帮助网络收敛。具体方法如下
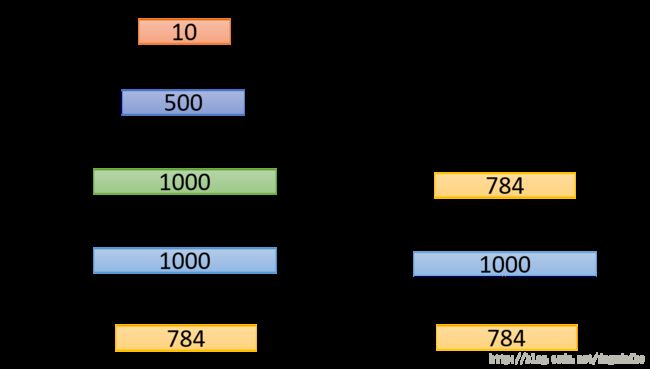
左侧是我们最终希望得到的网络,右边是我进行与训练方法的第一步。我们将数据进行自编码,注意,这里的隐层的神经元的数量远远高于,所以要防止网络根本没有训练,直接将数据传到隐层再传到输出层的情况,所以在训练这一层的时候可以加入一项较大的 L1 惩罚项,使得权重只有部分有数值,强迫网络进行学习。这层收敛之后进入下一层的训练,方法如下

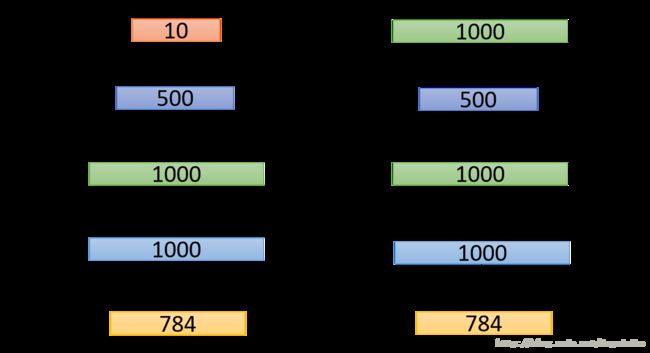
这里保证之前得到的权重不变,将数据经过第一层的输出作为输入,令图中的两个 a 保持不变进行自编码,得到权重 W2 ,同样的方法如下图,可以得到 W3 。
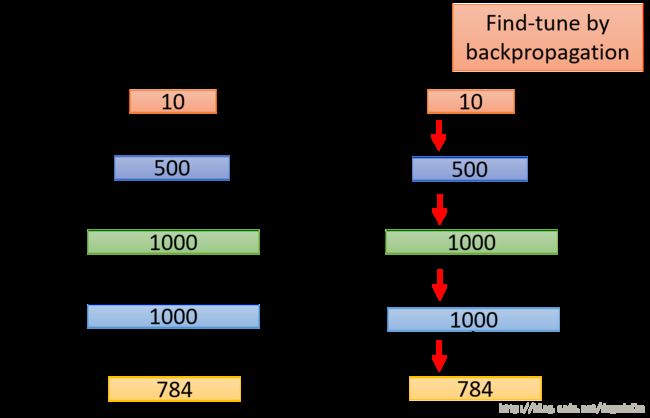
最后加上最后一层,利用所有数据进行训练,或者现在这个过程可以认为是一种 finetune的过程,如下图所示
如上的这个过程在我看来还可以进行进一步的简化,因为现在的技术已经可以较好的训练NN了,所以可以直接训练一个deep autoencoder 之后只取网络的前半部分,然后再接一层进行finetune感觉实际上因该是一样的。这种方法的原始意义在于帮助网络进行与训练加快网络的收敛,但是实际上现在基本上不会用到这样的预训练。但是这种方法同样是有作用的,因为当我们手中的数据一部分是有标签而另一部分是没有标签的,这个时候可以采用 deep auto encoder 通过无标签的数据进行训练,得到一个可以很好提出图像特征的特征提取器,之后在利用有标签的数据进行训练。十分完美~
4. 去噪编码器
这个过程主要如下图所示

在这里首先对图像加入噪声,之后将含有噪声的图像作为输入图像训练自编码器,这里需要注意的是输出层不是要和输入数据(含噪声的数据),而应该是和原始数据相同,这样才能够去掉噪声;另一方面,这个网络可以将含有噪声的图像恢复为原来的样子,所以也证明它是一个鲁棒性很强的模型,即增加了编码器的鲁棒性。
5. CNN自编码器
CNN自编码器的主要流程如下图所示

在这里如果将右侧的部分认是编码的过程的话,在编码的过程中涉及到卷积和池化,所以再解码的过程中涉及到上采样和反卷积。上采样的一种方法如下图所示。
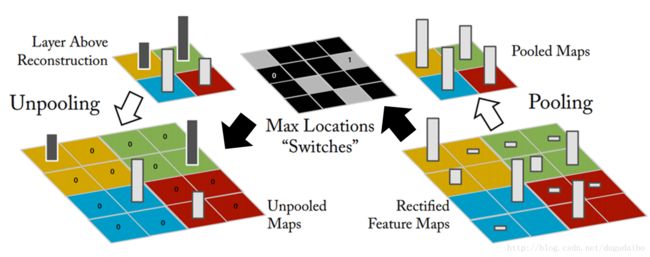
它在每一次的下采样中都记住 maxpooling 所取的最大值的位置,然后在后恢复的过程中将最大值的那个位置仍取最大值,将剩下的位置置零;另一种方法是直接将最大值repeat到四个位置,不用记住位置。
而反卷积的过程实际上就是一个卷积的过程,我们以一维的卷积为例进行说明
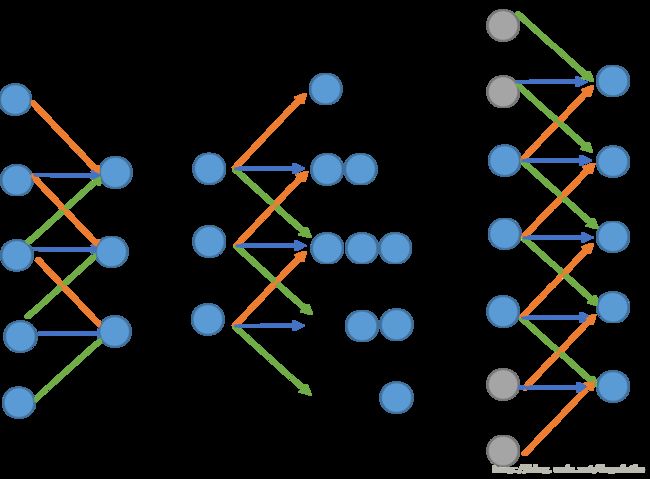
如左图所示是一个一维卷积的例子,我们可以看到经过三个卷积核之后,数据由5维降低至3维,所以如果想得到原来的效果就应该如中间图那样进行计算,每一个神经元伸出去三个权重,得到的位置重叠的结果进行相加,这个过程实际上等同与右侧的过程,但是需要进行补零,所以反卷积的过程实际上就是卷积。
6. 利用自编码器生成数据
自编码器还可用来生成数据,具体的方法如下
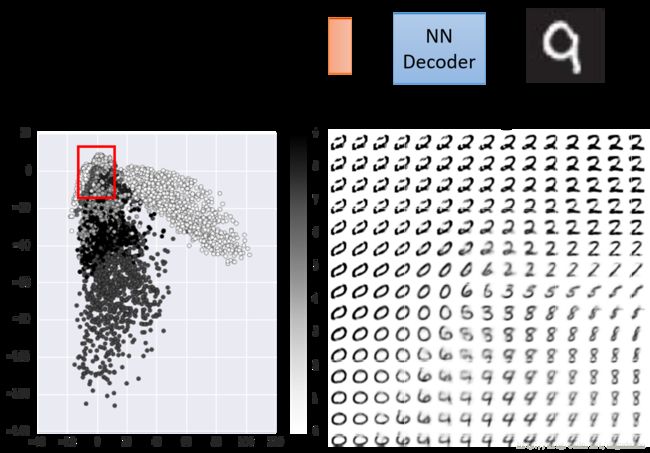
将数据编码至二维空间之后,在某一部分区域进行均匀采样,之后输入解码器之后得到的图像如上图所示。但是这个方法有一个问题,采样的时候还需要首先对数据的分布进行观察在采样,很不方便。因此我们在训练的过程中,加入较强的 l2 正则化,希望得到的权重都是分布在 [0,1] 之间,这样编码得到的结果就如下图所示
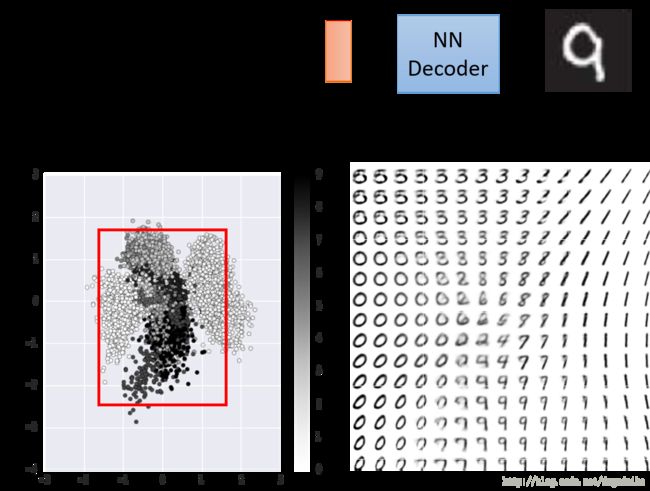
数据明显是中心对成的,所以只需要在中心的一部分区域进行采样即可。
7. 相关小结
总体来讲深度自编码器的实现方式主要有两种,一种是通过NN实现,另一种是通过CNN实现。
它的应用主要有一下几个方面:
(1)最原始的功能:编码和解码
(2)对数据进行降维,并将它们区分开来,效果虽然明显好于PCA的方法,但是也明显差于t-SNE的方法。
(3)抽取图像的特征,这个是一种很通用的方法,不仅仅能抽取有label数据的特征,还可以抽取没有label数据的特征,得到特征之后可以计算之间的相似性(如进行图像,文本的检索),或者进行其他的下一步的操作
(4)预训练网络。这一点现在不常用于预训练网络,而是首先通过无标签的数据进行预训练得到初始权重,再用有标签的数据进行finetune。
(5)图像去噪或者增强模型的抗噪声鲁棒性
(6)生成数据或者图像(但是不知道具体有什么用……)