19. C语言 -- 指针和二维数组
本博客主要内容为 “小甲鱼” 视频课程《带你学C带你飞》【第一季】 学习笔记,文章的主题内容均来自该课程,在这里仅作学习交流。在文章中可能出现一些错误或者不准确的地方,如发现请积极指出,十分感谢。
也欢迎大家一起讨论交流,如果你觉得这篇文章对你有所帮助,记得评论、点赞哦 ~(。・∀・)ノ゙
1. 二维数组
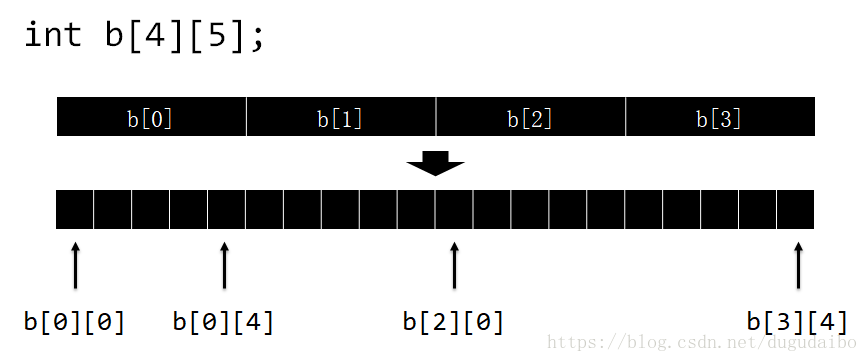
回顾 《15. C语言 – 二维数组》 中的内容可以知道,C 语言没有真正意义上的二维数组。二维数组的实现,只是简单地通过“线性扩展”的方式进行。如图所示,int b[4][5]; 就是定义 4 个元素,每个元素都是一个包含 5 个整型变量的一维数组。它在内存中依然是以线性的形式存储。
2. 关于数组的三个问题
假设我们定义了二维数组array[4][5],为了方便理解,使用如下的形式进行表述

2.1 array 表示的是什么?
显然同一维数组一样, array 是整个二维数组的首地址;在一维数组中,数组名是数组中第一个元素的地址,但是在二维数组中,数组名是第一行元素的地址。其实这个也很好理解,可以将整个二维数组当作是一个一维数组,那么一维数组中的每一个元素就是 array 中的一行。下面将通过代码的形式进行验证
#include 我们初始化了一个全为 0 的数组,首先打印出了整型在内存中的大小,之后打印出 array 的地址,和 array 的下一个位置的地址。如果 array 指向的是数组中的第一行,那么 array 将指向数组中的第二行,array 与 array 之间差就是 5*sizeof(int),也就是指针 array 的步长为 5 。执行上述代码可以得到如下的结果
sizeof int: 4
array: 0x7ffcebf6e700
array + 1: 0x7ffcebf6e714
整型在内存中的大小为 4 ,而 array + 1 与 array 的差正好是 20。所以很明显,array 确实是数组中第一行元素的指针。
2.2 *(array+1)表示的是什么?
*(array+1) 称为 (array+1) 的解引用,也就是之前所讲的取值。我们可以从两个角度对他进行理解。首先从解引用的角度,从上面你得分析可以知道,array 是数组中第一行元素的指针,也就是说 array 的地址是数组的首地址,步长是数组中每一行元素的个数。因此 array + 1 所表示的数组的第二行的指针,对它进行解引用,实际上就是对 array +1所在的地址取值,很显然就是数组中第二行的第一个元素。
但是一个更好的角度是从语法糖的角度进行考虑。语法糖(Syntactic sugar)是由 Peter J. Landin(和图灵一样的天才人物,是他最先发现了 Lambda 演算,由此而创立了函数式编程)创造的一个词语,它意指那些没有给计算机语言添加新功能,而只是对人类来说更“甜蜜”的语法。语法糖往往给程序员提供了更实用的编码方式,有益于更好的编码风格,更易读。不过其并没有给语言添加什么新东西。
在 C 语言里用 a[n] 表示 *(a+n),用 a[n][m] 表示 *(*(a+n)+m),这就是语法糖的应用,因为在内部,编译器会自动将 a[n] 转换为 *(a+n) 的形式实现。同样我们之前学习过的 for 循环也是 while 循环的一种语法糖。
因此 *(array+1) == array[1] ,而 array[1] 又可以看作是二维数组中第二行元素所组成的子数组的名字,也就是数组中第二行第一个元素的地址。我们可以通过实验的方式的进行验证
#include 在上面的代码中,首先初始化了一个数组,数组中的元素是各不相同的,之后打印输出 *(array+1) 以及对应的语法糖 array[1],然后打印出数组中 array[1][0] 的地址,最后打印出对 array+1 的双重解引用,如果 *(array+1) 是 array[1](即数组中第二行中第一个元素的地址),那么 **(array+1) 将表示第二行第一元素的值。执行代码的到如下的结果
*(array+1): 0x7ffe4640fe84
array[1]: 0x7ffe4640fe84
&array[1][0]: 0x7ffe4640fe84
**(array+1): 5
可以看到 array[1] 确实是 *(array+1) 的语法糖,并且指向数组中第二行第一个元素的地址。
2.3 * (*(array+1)+3)表示什么?
根据刚刚所讲的语法糖,*(array+1)+3 可以表示为下面的形式

由于 *(array+1) 是第二行第一个元素的地址,所以 *(array+1)+3 是第二行第四个元素的地址,那么很明显 * ( *(array+1)+3) 表示第二行第四个元素的值。
这样我们就得到了一个结论,在 C 原的数组中,下标索引的形式都可以转化为使用指针间接索引的形式,并且他们之间是完全等价的,如下图所示

3. 数组指针和二维数组
在之前《15. C语言 – 二维数组》 中的第二部分,二维数组的初始化中讲到数组可以使用如下的方式进行定义
int array[2][3] = {{0, 1, 2}, {3, 4, 5}};
// 可以写成
int array[][3] = {{0, 1, 2}, {3, 4, 5}};
在之前的《18. C语言 – 指针数组和数组指针》 中的第3部分 数组指针 可以知道,定义一个数组指针是这样的
int (*p)[3];
那么问题来了,请问如何解释下边语句
int (*p)[2] = array;
很明显,根据刚刚所讲的内容,array 是数组第一行元素的指针,所以 p 是指向一个有两个元素数组的指针,数组中的每个元素是 array 数组中的一行。
我们可以通过下面的代码进行验证
#include 如果 p 是指向一个有两个元素数组的指针(数组中的每个元素是 array 数组中的一行),那么 **(p+1) 将表示数组中第二行第一个元素的值,根据语法糖可知 **(array+1) 表示的也是数组中第二行第一个元素的值。执行上面的代码可以获得如下的实验结果
**(p+1): 3
**(array+1): 3
array[1][0]: 3
*(*(p+1)+2): 5
*(*(array+1)+2): 5
array[1][2]: 5
很明显刚刚的解释是正确的。
参考
[1] “小甲鱼” 视频课程《带你学C带你飞》【第一季】P24
欢迎大家关注我的知乎号(左侧)和经常投稿的微信公众号(右侧)
