MyBatis入门
1. 基本用法
开发流程:
(1)配置好MyBatis
主要就是需要配置好数据源以及告诉MyBatis持久化类的映射文件mapper.xml哪里找。MyBatis默认的配置文件名称是mybatis-config.xml,在最开始的示例中我们将MyBatis的配置放在了applicationContext.xml中,这也是可以的。
传统简单配置:
<configuration>
<properties resource="db.properties"/>
<settings>
<setting name="logImpl" value="LOG4J"/>
settings>
<typeAliases>
<typeAlias alias="user" type="org.fkit.domain.User"/>
typeAliases>
<environments default="mysql">
<environment id="mysql">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
dataSource>
environment>
environments>
<mappers>
<mapper resource="org/fkit/mapper/UserMapper.xml"/>
mappers>
configuration>注解模式下的高级配置:
<mybatis:scan base-package="org.fkit.hrm.dao"/>
<context:component-scan base-package="org.fkit.hrm"/>
<context:property-override location="classpath:db.properties"/>
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"/>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"
p:dataSource-ref="dataSource"/>
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager"
p:dataSource-ref="dataSource"/>
<tx:annotation-driven transaction-manager="transactionManager"/>
beans>(2)根据数据中的表,定义好领域模型
这里不赘述,只强调一点,属性都要用对象类型,不要用基础类型。
(3)定义Mapper XML文件
<mapper namespace="org.fkit.mapper.OrderMapper">
<insert id="saveUser" parameterType="user"
useGeneratedKeys="true" keyProperty="id">
INSERT INTO TB_USER(name,sex,age)
VALUES(#{name},#{sex},#{age})
insert>
mapper>- namespace:全局要唯一
- id:mapper的id。
- parameterType:表示执行这条语句的时候需要一个User类型的对象作为参数。
- useGeneratedKeys:使用数据库的自动增长主键,建议对MySQL开启。
- keyProperty:将数据库生成的主键设置到user对象的id属性中去,从而在代码中,执行完这条SQL,user实例的id就被赋值了,可以读取。
#{name}:当parameterType是基础类型的时候,这里读取的就是入参;当parameterType是一个对象类型的时候,这里读取的就是对象的属性。
(4)使用SqlSession执行mapper
获取SqlSession分为三步:
- 读取mybatis-config.xml文件;
- 创建一个SqlSessionFactory;
- 使用SqlSessionFactory获取一个SqlSession;
考虑到SqlSessionFactory需要频繁使用,我们可以把它写成一个单例模型:
public class FKSqlSessionFactory {
private static SqlSessionFactory sqlSessionFactory = null;
// 初始化创建SqlSessionFactory对象
static{
try {
// 读取mybatis-config.xml文件
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(inputStream);
} catch (Exception e) {
e.printStackTrace();
}
}
// 获取SqlSession对象的静态方法
public static SqlSession getSqlSession(){
return sqlSessionFactory.openSession();
}
// 获取SqlSessionFactory的静态方法
public static SqlSessionFactory getSqlSessionFactory() {
return sqlSessionFactory;
}
}执行可以这样写:
public static void main(String[] args) throws Exception {
// 获得Session实例
SqlSession session = FKSqlSessionFactory.getSqlSession();
// 创建User对象
User user = new User("jack", "男", 22);
// 插入数据
session.insert("org.fkit.mapper.UserMapper.saveUser", user);
// 提交事务
session.commit();
// 关闭Session
session.close();
}2. 深入用法
2.1 Mapper接口的代理对象
MyBatis官方手册建议通过mapper接口的代理对象执行SQL操作,该对象关联了SqlSession对象,开发者可以通过该对象直接调用方法操作数据库。
public interface OrderMapper {
Order selectOrderByUserId(int id);
}和下面这句mapper对应:
<select id="selectOrderByUserId" parameterType="int" resultType="org.fkit.domain.Order">
SELECT * FROM tb_order WHERE user_id = #{id}
select>方法名和参数以及返回类型都必须与Mapper一致,使用SqlSession.getMapper方法就可以获取该接口的代理对象:
// 读取mybatis-config.xml文件
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
// 初始化mybatis,创建SqlSessionFactory类的实例
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(inputStream);
// 创建Session实例
SqlSession session = sqlSessionFactory.openSession();
// 获得UserMapper接口的代理对象
UserMapper um = session.getMapper(UserMapper.class);
// 调用selectUserById方法
User user = um.selectUserById(1);2.2 ResultMap
当mapper中的返回类型是一个对象,尤其是这个对象的属性名和数据库中表的列名不一致时,需要使用resultMap这个元素作为对mapper的补充:
<resultMap id="userResultMap" type="org.fkit.domain.User">
<id property="id" column="user_id" />
<result property="name" column="user_name"/>
<result property="sex" column="user_sex"/>
<result property="age" column="user_age"/>
resultMap>
<select id="selectUser2" resultMap="userResultMap">
SELECT * FROM TB_USER2
select>resultMap有两种子元素:
(1)id:表述数据库的主键;
(2)result:普通列;
2.3 关联映射
2.3.1 一对一关系
一对一的关系很常见,比如一个人只有一个身份证,一个身份证只能属于一个人;这种从左到右和从右到左都是1的关系,就是一对一关系。
- 在数据库中的表现形式是一张表的外键列参考另一张表的主键,然后再给这个外键列添加唯一性约束。
- 在Java编码中的表现形式就是一个对象包含另一个对象。
建表:
create table tb_person(
id int primary key AUTO_INCREAMENT,
name varchar(18),
sex varchar(2),
card_id varchar(20) unique,
foreign key (card_id) references tb_card(id)
);Person.java
public class Person implements Serializable {
private Integer id; // 主键id
private String name; // 姓名
private String sex; // 性别
private Integer age; // 年龄
// 人和身份证是一对一的关系,即一个人只有一个身份证
private Card card; Card.java
public class Card implements Serializable {
private Integer id; // 主键id
private String code; // 身份证编号来看一眼一对一的关联映射怎么写:
<mapper namespace="org.fkit.mapper.PersonMapper">
<select id="selectPersonById" parameterType="int" resultMap="personMapper">
select * from tb_person where id = #{id}
select>
<resultMap id="personMapper" type="Classes">
<id property="id" column="id" />
<result property="name" column="c_name" />
<result property="sex" column="sex" />
<result property="age" column="age" />
<association property="card" javaType="org.fkit.domain.Card"
column="card_id"
select="org.fkit.mapper.selectCardById"/>
resultMap>
<select id="selectCardById" parameterType="int" resultType="org.fkit.domain.Card">
select * from tb_card where id = #{id}
select>
mapper>在数据库中,person表是没有保存card信息的,仅仅保存了一个card_id,所以执行selectPersonById这个mapper之后得到的仅仅是card_id,而不是Card对象,因此需要再执行一条select查询语句来返回Card对象。
实际上,上面的列子相当于执行了select * from tb_person where id = #{id} + select * from tb_card where id = #{id} + 将结果利用resultMap映射为对象。我们也可以用内连接查询来简化这个步骤,即:
select * from tb_person p, tb_card where p.id = #{id} and p.card_id = c.id + 将结果利用resultMap映射为对象。也就是说,第一条select语句改为上面的内连接查询,然后在定义association元素的时候就不用指定select语句了。
association注意点:
(1)association中的结果类型叫 javaType,和resultMap中的resultType类型但是不要混淆了。
(2)association也可以像resultMap一样有id和result子元素。
2.3.2 一对多关系
一对一关系使用外键进行关联,不论是A参考B的主键还是B参考A的主键都是可以的,只不过我们会根据现实世界的逻辑分一个主表一个附表。一对多关系也是使用外键关联,外键列在“多”的一方,与一对一关系的区别在于这个外键列不需要加unique约束。比如一个班有多个学生,而一个学生只能属于一个班。在Java编码的表现形式是“一”的一方中的一个属性是“多”的一方的集合。
Student.java:
public class Student implements Serializable {
private Integer id; // 学生id,主键
private String name; // 姓名
private String sex; // 性别
private Integer age; // 年龄
// 学生和班级是多对一的关系,即一个学生只属于一个班级
private Clazz clazz;Class.java:
public class Clazz implements Serializable {
private Integer id; // 班级id,主键
private String code; // 班级编号
private String name; // 班级名称
// 班级和学生是一对多的关系,即一个班级可以有多个学生
private List students; ClazzMapper.xml:
<mapper namespace="org.fkit.mapper.ClazzMapper">
<select id="selectClazzById" parameterType="int" resultMap="clazzResultMap">
SELECT * FROM tb_clazz WHERE id = #{id}
select>
<resultMap type="org.fkit.domain.Clazz" id="clazzResultMap">
<id property="id" column="id"/>
<result property="code" column="code"/>
<result property="name" column="name"/>
<collection property="students" javaType="ArrayList"
column="id" ofType="org.fkit.domain.Student"
select="org.fkit.mapper.StudentMapper.selectStudentByClazzId"
fetchType="lazy">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="sex" column="sex"/>
<result property="age" column="age"/>
collection>
resultMap>
mapper>collection标签的属性:
- property:属性名
- javaType:属性的类型
- ofType:集合类型中泛型的类型
- column:表示使用id作为参数进行之后的select查询。这个属性很容易混淆,与它上下文中的column属性的含义都不同。但是也可以理解,因为很显然数据库表中绝不对有一个集合类型的列,所以collection标签中的
column绝不表示属性对应的列,而是接下来需要使用的列,一般就是主键,因为外表参考主键。 - fetchType:eager表示立即加载,lazy表示懒加载,默认是lazy
类似的道理,只查一张表找不全Clazz对象需要的所有属性,所以collection中有另一条select语句。
接下来是StudentMapper.xml:
<mapper namespace="org.fkit.mapper.StudentMapper">
<select id="selectStudentByClazzId" parameterType="int"
resultMap="studentResultMap">
SELECT * FROM tb_student WHERE clazz_id = #{id}
select>
<resultMap type="org.fkit.domain.Student" id="studentResultMap">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="sex" column="sex"/>
<result property="age" column="age"/>
<association property="clazz" javaType="org.fkit.domain.Clazz">
<id property="id" column="id"/>
<result property="code" column="code"/>
<result property="name" column="name"/>
association>
resultMap>
<select id="selectStudentById" parameterType="int" resultMap="studentResultMap">
SELECT * FROM tb_clazz c,tb_student s
WHERE c.id = s.clazz_id
AND s.id = #{id}
select>
mapper>Student对象中有一个Clazz对象,一个Student只能属于一个Clazz,所以这里和一对一关系类似,在resultMap中使用association标签。这个xml中有两个mapper,我们先来看底下的selectStudentById。
SELECT * FROM tb_clazz c,tb_student s
WHERE c.id = s.clazz_id
AND s.id = #{id}这个mapper的SQL语句把Student需要的所有属性,包括Clazz中的属性都select回来了,所以association中就不想要额外的select语句了。
另一个mapper selectStudentByClazzId 也是同样的道理。它在Clazz的mapper中使用,气候两条SQL已经把需要的属性全查回来了。
2.3.3 多对多关系
一个订单包含多种商品,一种商品可以属于多个订单,这就是多对多关系。多对多关系一般采用一个中间表来维护,参考另外两张表的主键。
Order.java:
public class Order implements Serializable {
private Integer id; // 订单id,主键
private String code; // 订单编号
private Double total; // 订单总金额
// 订单和用户是多对一的关系,即一个订单只属于一个用户
private User user;
// 订单和商品是多对多的关系,即一个订单可以包含多种商品
private List articles; Article.java
public class Article implements Serializable {
private Integer id; // 商品id,主键
private String name; // 商品名称
private Double price; // 商品价格
private String remark; // 商品描述mapper:
<mapper namespace="org.fkit.mapper.OrderMapper">
<resultMap type="org.fkit.domain.Order" id="orderResultMap">
<id property="id" column="oid"/>
<result property="code" column="code"/>
<result property="total" column="total"/>
<association property="user" javaType="org.fkit.domain.User">
<id property="id" column="id"/>
<result property="username" column="username"/>
<result property="loginname" column="loginname"/>
<result property="password" column="password"/>
<result property="phone" column="phone"/>
<result property="address" column="address"/>
association>
<collection property="articles" javaType="ArrayList"
column="oid" ofType="org.fkit.domain.Article"
select="selectArticleByOrderId"
fetchType="lazy">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="price" column="price"/>
<result property="remark" column="remark"/>
collection>
resultMap>
<select id="selectOrderById" parameterType="int" resultMap="orderResultMap">
SELECT u.*,o.id AS oid,CODE,total,user_id
FROM tb_user u,tb_order o
WHERE u.id = o.user_id
AND o.id = #{id}
select>
<select id="selectOrderByUserId" parameterType="int" resultType="org.fkit.domain.Order">
SELECT * FROM tb_order WHERE user_id = #{id}
select>
<select id="selectArticleByOrderId" parameterType="int"
resultType="org.fkit.domain.Article">
SELECT * FROM tb_article WHERE id IN (
SELECT article_id FROM tb_item WHERE order_id = #{id}
)
select>
mapper>2.4 动态SQL
常用的动态SQL元素包括:
- if
- choose(when、otherwise):类似switch。
- where:where元素直到只有一个以上的if条件有值才把where子句加上,而且会智能得去除多余的AND和OR。
- set:set元素会自动前置SET关键字,并且会去除无关的逗号。
- foreach:使用MyBatis的mapper执行SQL往往会需要一个输入参数,类型不限,所以我们可以将集合类型作为输入参数,然后结合SQL语句中的
in条件语句来操作数据库。 - bind:可以将OGNL表达式的值绑定到一个变量中,方便后来引用这个变量的值,一般用于LIKE子句。
<mapper namespace="org.fkit.mapper.EmployeeMapper">
<select id="selectEmployeeWithId" parameterType="int" resultType="org.fkit.domain.Employee">
SELECT * FROM tb_employee where id = #{id}
select>
<select id="selectEmployeeByIdLike"
resultType="org.fkit.domain.Employee">
SELECT * FROM tb_employee WHERE state = 'ACTIVE'
<if test="id != null ">
and id = #{id}
if>
select>
<select id="selectEmployeeByLoginLike"
resultType="org.fkit.domain.Employee">
SELECT * FROM tb_employee WHERE state = 'ACTIVE'
<if test="loginname != null and password != null">
and loginname = #{loginname} and password = #{password}
if>
select>
<select id="selectEmployeeChoose"
parameterType="hashmap"
resultType="org.fkit.domain.Employee">
SELECT * FROM tb_employee WHERE state = 'ACTIVE'
<choose>
<when test="id != null">
and id = #{id}
when>
<when test="loginname != null and password != null">
and loginname = #{loginname} and password = #{password}
when>
<otherwise>
and sex = '男'
otherwise>
choose>
select>
<select id="findEmployeeLike"
resultType="org.fkit.domain.Employee">
SELECT * FROM tb_employee WHERE
<if test="state != null ">
state = #{state}
if>
<if test="id != null ">
and id = #{id}
if>
<if test="loginname != null and password != null">
and loginname = #{loginname} and password = #{password}
if>
select>
<select id="selectEmployeeLike"
resultType="org.fkit.domain.Employee">
SELECT * FROM tb_employee
<where>
<if test="state != null ">
state = #{state}
if>
<if test="id != null ">
and id = #{id}
if>
<if test="loginname != null and password != null">
and loginname = #{loginname} and password = #{password}
if>
where>
select>
<update id="updateEmployeeIfNecessary"
parameterType="org.fkit.domain.Employee">
update tb_employee
<set>
<if test="loginname != null">loginname=#{loginname},if>
<if test="password != null">password=#{password},if>
<if test="name != null">name=#{name},if>
<if test="sex != null">sex=#{sex},if>
<if test="age != null">age=#{age},if>
<if test="phone != null">phone=#{phone},if>
<if test="sal != null">sal=#{sal},if>
<if test="state != null">state=#{state}if>
set>
where id=#{id}
update>
mapper>2.4.1 foreach
<select id="selectEmployeeIn" resultType="org.fkit.domain.Employee">
SELECT *
FROM tb_employee
WHERE ID in
<foreach item="item" index="index" collection="list"
open="(" separator="," close=")">
#{item}
foreach>
select> public void testSelectEmployeeIn(SqlSession session){
EmployeeMapper em = session.getMapper(EmployeeMapper.class);
// 创建List集合
List ids = new ArrayList();
// 往List集合中添加两个测试数据
ids.add(1);
ids.add(2);
List list = em.selectEmployeeIn(ids);
list.forEach(employee -> System.out.println(employee));
} 2.4.2 bind
<select id="getEmpsTestInnerParameter" resultType="com.cn.zhu.bean.Employee">
<bind name="_lastName" value="'%'+lastName+'%'"/>
select * from tbl_employee
<if test="_parameter!=null">
where last_name like #{_lastName}
if>
select> 2.5 缓存机制
MyBatis的缓存是针对查询的,为了提高查询的执行效率,这一点首先明确。MyBatis分为两级,一级缓存是SqlSession级别的缓存,二级缓存是mapper级别的缓存。
2.5.1 一级缓存
MyBais的一级缓存是SqlSsesion级别的级存。在操作数据库时要构造一个SqlSsesion对象,该对象中就包含一个HashMap用于存储缓存数据,不同的SqlSsesion 之间的HashMap是互不影响的。当在同一个SqlSsesion中执行两次相同的sql语句时,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次查询时会从缓存中获取数据,不再去底层数据库查询,从而提高查询效率。
- 修改操作的影响:需要注意的是,如果SqlSsesion执行了DML操作(insert、update 和delete),并commit了,MyBatis则会清空SqlSession中的一级缓存,这样做的自的是为了保面项在中在做的是最新的值息,避免脏读。
- clearCache():如果SqlSession调用了clearCache(),会清空HashMap对象中的数据,但是该对象仍可使用。
- 配置:Mybaltis默认开启一级缓存,不需要进行任何配置。
查询命中的条件
传入的 statementId
查询时要求的结果集中的结果范围 (结果的范围通过rowBounds.offset和rowBounds.limit表示);
这次查询所产生的最终要传递给JDBC java.sql.Preparedstatement的Sql语句字符串(boundSql.getSql() )
传递给java.sql.Statement要设置的参数值
HashMap的key就是 statementId + rowBounds + 传递给JDBC的SQL + 传递给JDBC的参数值之后进过计算得到的。
注意事项
MyBatis对会话(Session)级别的一级缓存设计的比较简单,就简单地使用了HashMap来维护,并没有对HashMap的容量和大小进行限制。MyBatis这样设计也有它自己的理由:
- 一般而言SqlSession的生存时间很短。一般情况下使用一个SqlSession对象执行的操作不会太多,执行完就会消亡;
对于某一个SqlSession对象而言,只要执行update操作(update、insert、delete),都会将这个SqlSession对象中对应的一级缓存清空掉,所以一般情况下不会出现缓存过大,影响JVM内存空间的问题;
可以手动地释放掉SqlSession对象中的缓存。
所以使用一级缓存时,对于数据变化频率很大,并且需要高时效准确性的数据要求,我们使用SqlSession查询的时候,要控制好SqlSession的生存时间,SqlSession的生存时间越长,它其中缓存的数据有可能就越旧,从而造成和真实数据库的误差;同时对于这种情况,用户也可以手动地适时清空SqlSession中的缓存。
2.5.2 二级缓存
存储:同样使用HashMap。
作用域:mapper的namespace,也可以指定几个mapper共用一个namespace。
select的读取顺序:二级缓存 —> 一级缓存 —> 数据库。
原理
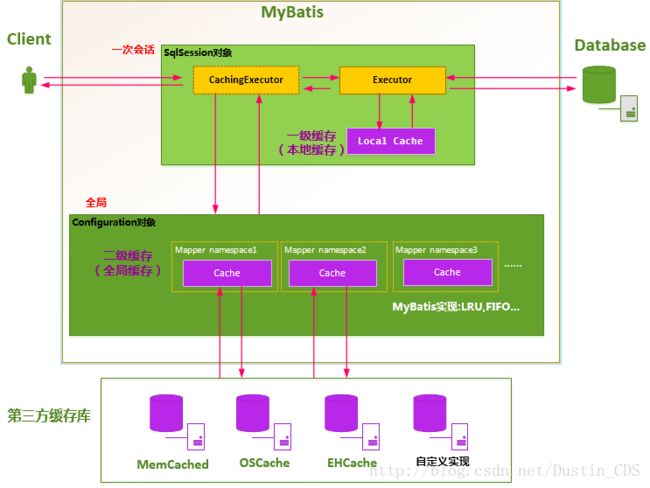
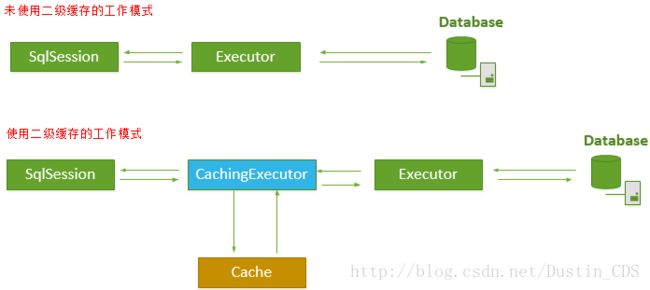
如上图所示,当开一个会话时,一个SqlSession对象会使用一个Executor对象来完成会话操作,MyBatis的二级缓存机制的关键就是对这个Executor对象做文章。如果用户配置了”cacheEnabled=true“,那么MyBatis在为SqlSession对象创建Executor对象时,会对Executor对象加上一个装饰者:CachingExecutor,这时SqlSession使用CachingExecutor对象来完成操作请求。CachingExecutor对于查询请求,会先判断该查询请求在Application级别的二级缓存中是否有缓存结果,如果有查询结果,则直接返回缓存结果;如果缓存中没有,再交给真正的Executor对象来完成查询操作,之后CachingExecutor会将真正Executor返回的查询结果放置到缓存中,然后在返回给用户。
配置二级缓存
(1)在全局配置中启用二级缓存(必须)
<settings>
<setting name="logImpl" value="LOG4J"/>
<setting name="cacheEnabled" value="true"/>
settings>(2)在mapper中启动namespace的二级缓存
<cache
eviction="LRU"
flushInterval="60000"
size="512"
readOnly="true"/> - eviction:置换策略
- LRU:(Least Recently Used),最近最少使用算法,即如果缓存中容量已经满了,会将缓存中最近做少被使用的缓存记录清除掉,然后添加新的记录;
- FIFO:(First in first out),先进先出算法,如果缓存中的容量已经满了,那么会将最先进入缓存中的数据清除掉;
- flushInterval:刷新周期。
- size:这个ns底下的缓存的最大值