改进机器学习模型,怎么少的了主动学习?!
全文共2059字,预计学习时长4分钟

图片来源:pexels.com/@pixabay
本文将阐述如何通过主动学习迭代改善机器学习模型的性能。这项技能适用于任何模型,但是本文将对主动学习如何改进二进制文本分类器进行说明。以下所有内容基于微软2018年Strata数据会议教程《将R和Python用于可扩展的数据科学、机器学习和人工智能》。
代码传送门:https://github.com/hsm207/Strata2018/tree/blog

方法
数据集
通过在Wikipedia Detox数据集上构建一个二进制文本分类器来阐述主动学习的概念,以检测注释是否造成人身攻击。这里有一些例子来说明这个问题:
数据集传送门:https://meta.m.wikimedia.org/wiki/Research:Detox/Data_Release

训练集有115,374个被标注的例子。现将这个训练集分为三个集合,即初始训练集、未标注训练集和测试集,具体如下:

此外,标注在初始训练集中分布均匀,但在测试集中只有13%的标注为1。
通过这种方式分割训练集来模拟现实情况。其对应情况是有10285个高质量的被标注的例子,决定105089个“未标注”的例子中哪些需要标注,以得到更多的训练数据来训练分类器。因为标注数据很昂贵,所以确定对模型性能最有用的例子是一个挑战。
就未标注训练集来说,主动学习相对于随机抽样是一种更好的抽样法。
最后使用Glove单词嵌入将注释转换为50维嵌入式。
抽样法
使用的抽样法是不确定性抽样和联合抽样二者的结合。其工作方式是:
1. 从未标注训练集中随机选择1000个样本。
2. 使用欧氏距离作为距离度量(这是集合部分),在这1000个样本上构建一个分集聚类。
3. 将分集聚类的输出分为20组。
4. 对每一组选择熵entropy(http://www.di.fc.ul.pt/~jpn/r/maxent/maxent.html)最大的样本。即选取模型最不确定的观测值。
以上是为了模拟一次只能得到20个高质量标注的情况,例如,一名放射科医生一天只能处理20张医学图像。没有对整个未标注训练集聚类,是因为计算熵需要进行模型推导,而这在大型数据集中可能需要花很长的时间。
聚类样本的原因是为了最大化增加标注样本的多样性。例如,若简单从1000个样本中选出熵最高的前20个,如果这些样本紧密,就有可能选出非常相似的样本。这种情况最好只从这个组中选择一个例子,剩余从另一个组中选择,因为不同例子有助于更好学习模型。
模型
通过FastTrees来构建分类器,用注释的矢量嵌入作为输入。FastTrees是FastRank的实现,FastRank是梯度提升算法的一种变体。
更多详情传送门:https://docs.microsoft.com/en-us/machine-learning-server/r-reference/microsoftml/rxfasttrees
评价指标
由于测试集不平衡,将使用AUC作为主要的评价指标。
实现细节
下面的图表来说明主动学习在此实验中所起的作用:
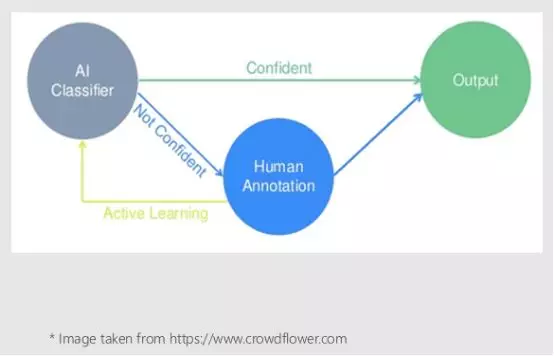
首先会在初始训练集上训练模型,然后使用这个模型和上述的抽样法来识别未标注训练集中分类最不确定即没有信心的20个注释,并进行人工标注。现在可以扩展初始训练集,包括人工新的标注样本,和重新训练模型(从零开始)。这是实验的主动学习部分。会重复20次迭代扩展初始训练集的步骤,并在每次迭代结束时评估模型在测试集上的性能。
结果
为了比较,可以通过从未标注的训练集中随机抽取任意20个例子来迭代扩展初始训练集。下图比较了主动学习方法(active)和3次随机抽样(random),根据训练集(tss)大小使用不同度量。
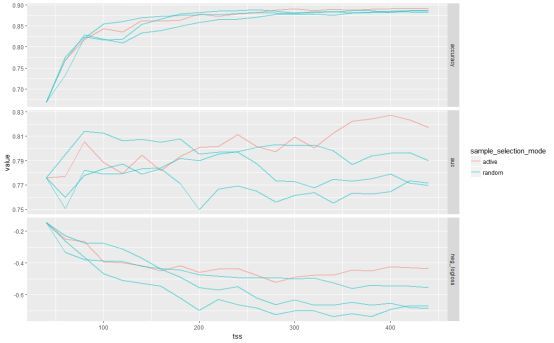
看得出最初随机抽样优于主动学习方法。然而,在训练集大小为300左右时,主动学习方法在AUC方面开始大幅度超过随机抽样。
在实践中可能会继续扩展初始训练集,直到模型改进(例如AUC的增加)相对于标注成本的比率下降到预先确定的阈值以下。
验证结果
为了确保得到的结果并非巧合,可以模拟随机抽样法进行100次20个迭代,并计算产生的AUC大于主动学习方法的次数。模拟结果只产生了一个随机抽样的AUC比主动学习高的例子。这表明主动学习的结果有5%的统计学意义。最后得出,随机抽样与主动学习的AUC平均差异为-0.03。
结论
在有大量未标注的数据和有限的预算来标注这些数据的情况下,采用主动学习的方法来确定哪些未标注的数据,通过人工标注可以在给定预算的限制下将模型的性能最大化。

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)