代码详解:轻巧!低廉!为自动驾驶汽车实施端到端学习
全文共3507字,预计学习时长7分钟

过去十年,自动驾驶汽车标志着汽车行业的最大变化。所有主要汽车公司都投身于开发属于自己的自动驾驶汽车。自动化技术将是一个价值高达7兆美元的行业,同时会在未来挽救很多人的生命。本文将深入介绍如何使用卷积神经网络开发自动驾驶汽车。
开发方法
每当谈到自动驾驶汽车时,大多会谈论激光雷达(LIDAR) 、雷达(RADAR)、360度摄像头和昂贵的图形处理器(GPU)。问题可分为几个部分,如车道检测、路径规划和控制。但在端到端的自动驾驶汽车模型中,构建的模型仅采用汽车前置摄像头图像并预测转向角度。这里只使用最低限度的训练数据和计算量,汽车就学会了在道路上行驶,无论路上是否有车道标记。
这构建了一个轻巧且计算成本低廉的优秀模型,并为这种自驾车问题提供了端到端的解决方案。
为什么需要自动驾驶汽车?
*降低驾驶员成本。
*减少驾驶员压力。
*停车更高效。
*省时、减少车流量。
*减少事故。
*支持汽车共享。
算法
下图中,这辆车配有三个摄像头,都安装在汽车挡风玻璃后。它们及时录下视频并采集转向角数据。为使汽车系统与外形相独立,设转向角数据为1/r,其中r表示以米为单位的转弯半径。使用1/r代替r是为了防止直线行驶时产生奇点。训练数据中包含从视频中采样并与转向数据相匹配的单图像帧。

端到端自动驾驶汽车的CNN模型
上图描述了在CNN模型中,视频作为图像帧被传送到CNN,模型再输出预期的转向角。然后使用反向传播算法,试着最小化预期转向角与计算出的转向角之间的误差。

测试CNN模型
训练过后,模型可以使用单个前置摄像头拍摄的视频图像预测转向角。
数据集——驾驶中汽车的图像大概有45000幅,共2.2G。数据集由陈苏利(SullyChen)于2017年制作。数据记录地点为加州的兰乔帕洛斯佛迪斯市和圣佩德罗。
数据集传送门:https://drive.google.com/file/d/0B-KJCaaF7elleG1RbzVPZWV4Tlk/view
网络架构——此网络由9层构成,其中包含5个卷积层,1个归一化层和3个完全连接层。
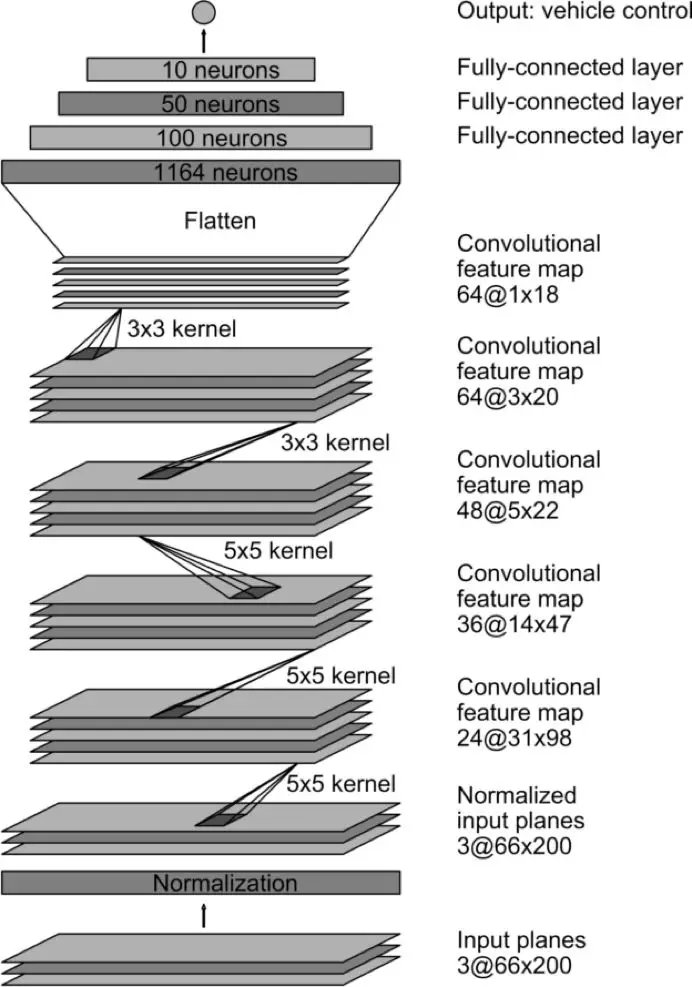
网络架构
import tensorflow as tfimport scipydef weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)def conv2d(x, W, stride):
return tf.nn.conv2d(x, W, strides=[1, stride, stride, 1], padding='VALID')
x = tf.placeholder(tf.float32, shape=[None, 66, 200, 3])
y_ = tf.placeholder(tf.float32, shape=[None, 1])
x_image = x#first convolutional layerW_conv1 =
weight_variable([5, 5, 3, 24])b_conv1 = bias_variable([24])h_conv1 =
tf.nn.relu(conv2d(x_image, W_conv1, 2) + b_conv1)
#second convolutional layerW_conv2 = weight_variable
([5, 5, 24, 36])b_conv2 = bias_variable([36])
h_conv2 = tf.nn.relu(conv2d(h_conv1, W_conv2, 2) + b_conv2)
#third convolutional layerW_conv3 = weight_variable([5, 5, 36, 48])
b_conv3 = bias_variable([48])h_conv3 = tf.nn.relu(conv2d(h_conv2, W_conv3, 2) + b_conv3)
#fourth convolutional layerW_conv4 = weight_variable([3, 3, 48, 64])
b_conv4 = bias_variable([64])h_conv4 = tf.nn.relu(conv2d(h_conv3, W_conv4, 1) + b_conv4)
#fifth convolutional layerW_conv5 = weight_variable([3, 3, 64, 64])
b_conv5 = bias_variable([64])h_conv5 = tf.nn.relu(conv2d(h_conv4, W_conv5, 1) + b_conv5)
#FCL 1W_fc1 = weight_variable([1152, 1164])b_fc1 = bias_variable([1164])
h_conv5_flat = tf.reshape(h_conv5, [-1, 1152])
h_fc1 = tf.nn.relu(tf.matmul(h_conv5_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32)h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#FCL 2W_fc2 = weight_variable([1164, 100])b_fc2 = bias_variable([100])
h_fc2 = tf.nn.relu(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
h_fc2_drop = tf.nn.dropout(h_fc2, keep_prob)
#FCL 3W_fc3 = weight_variable([100, 50])b_fc3 = bias_variable([50])
h_fc3 = tf.nn.relu(tf.matmul(h_fc2_drop, W_fc3) + b_fc3)h_fc3_drop = tf.nn.dropout
(h_fc3, keep_prob)
#FCL 3W_fc4 = weight_variable([50, 10])b_fc4 = bias_variable([10])h_fc4 = tf.nn.relu
(tf.matmul(h_fc3_drop, W_fc4) + b_fc4)h_fc4_drop = tf.nn.dropout(h_fc4, keep_prob)
#OutputW_fc5 = weight_variable([10, 1])b_fc5 = bias_variable([1])
#linear#y = tf.multiply((tf.matmul(h_fc4_drop, W_fc5) + b_fc5), 2)
## atany = tf.multiply(tf.atan(tf.matmul(h_fc4_drop, W_fc5) + b_fc5), 2)
#scale the atan output此网络的第一层由图像归一化组成。这是硬编码的,因为这部分在模型学习过程中并未涉猎过。归一化通过GPU处理有助于进行加速。
卷积层用于特征提取,这是通过对卷积层配置进行的实验后,根据观察结果选出的。在前三个卷积层中使用跨步卷积,其步幅为2x2、内核大小为5x5,最后两层中使用非跨步卷积,内核大小为3x3。
五个卷积层之后是三个完全连接层,它们输出转弯半径的倒数。
训练细节
为训练卷积神经网络,必须选择输入的图像帧。在此以10FPS的速率对视频进行采样。这是因为更高的取样速率可能会造成结果中包含信息无用的类似图像。
通过对图像帧增加转换、轮换等方式进行图像增强,以便于汽车学习如何从意外情况中恢复。从正态分布中随机选择图像增强摄动。正态分布的平均值为0,测出的标准误差是人类驾驶员所测标准误差的2倍。
可视化
举两个例子——一条未铺砌的道路和一条林道。在未铺砌的道路图中可以看到特征图激活,显示出了道路的轮廓。然而在林道图中,模型无法找出任何有用信息,且大多有噪声。
由此可见,CNN能够检测道路的轮廓,但是CNN从未被明确地训练检测道路轮廓这一功能。

CNN特征图激活(左下:第一层特征图激活。右下:第二层特征图激活)

CNN特征图激活(左下:第一层特征图激活,大多含噪声。右下:第二层特征图激活,大多含噪声。)
至此已经讨论了CNN如何使用少于100小时的驾驶数据学习检测道路的轮廓(包括不同的情况,如未铺砌道路、晴朗天气以及雨天)。模型能够在没有明确标记数据的情况下检测道路的轮廓。
问题的稳健性仍需提高,而且还需找到一种方式来确定稳健性以及优化网络内部进程的可视化。

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~