在Ubuntu16.04中配置Anaconda(Python2.7)以支持Spark2.0(Pyspark)
本文主要内容:
- 对比Spark和Hadoop
- 介绍PysPark和Anaconda
- 搭建并配置
- 运行WordCount
最近想学习大数据分析平台Spark,由于实验室设备不足,只能先在本地搭建一个独立式的Spark环境,进行简单分析,逐步探索Spark的奥秘,为以后Spark集群操作打好基础。
对于从事数据挖掘和机器学习人员来说,使用anaconda的ipython notebook无疑是最棒的体验。那么,如何在ipython notebook中使用spark呢?
Spark和Hadoop
大数据框架
- Hadoop是对大数据集进行分布式计算的标准工具。提供了包括工具和技巧在内的丰富的生态系统,允许使用相对便宜的商业硬件集群进行超级计算机级别的计算。主要核心:HDFS和MapReduce;
- Spark使用函数式编程范式扩展了MapReduce编程模型以支持更多计算类型,可以涵盖广泛的工作流。
- Spark据称要比Hadoop快100倍,但它本身没有一个分布式存储系统;
- Spark需要一个第三方的分布式存储系统;
- 结合Spark和Hadoop,将Spark安装在Hadoop之上,使得Spark可以使用存储在HDFS中的数据。
速度
- Spark基于内存:Spark使用内存缓存来提升性能,因此进行交互式分析也足够快速(就如同使用Python解释器,与集群进行交互一样)。缓存同时提升了迭代算法的性能,这使得Spark非常适合数据理论任务,特别是机器学习。
- Hadoop基于磁盘:MapReduce要求每隔步骤之间的数据要序列化到磁盘,这意味着MapReduce作业的I/O成本很高,导致交互分析和迭代算法(iterative algorithms)开销很大。而事实是,几乎所有的最优化和机器学习都是迭代的。
高级数据处理(实时流处理、机器学习)
- Spark胜过Hadoop——受欢迎原因;
- Spark平台的速度和流数据处理能力非常适合机器学习算法;
- Spark有自己的机器学习库MLlib,而Hadoop系统则需要借助第三方机器学习库,如Apache Mahout。
Spark库
Spark附带一些强大的库:
- SparkSQL:提供SQL语句,进行结构化数据查询和大数据集的探索。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作;
- SparkMLLIB:提供主要机器学习算法和框架。这个库包含可扩展的学习算法,如分类、聚类、回归等需要对大量数据集进行迭代的操作;
- Spark Streaming:提供实时处理;
- Spark GraphX:提供图处理和计算。
由于这些库满足了很多大数据需求,也满足了很多数据科学任务的算法和计算上的需要,Spark快速流行起来。不仅如此,Spark也提供了使用Scala、Java和Python编写的API;满足了不同团体的需求,允许更多数据科学家简便地采用Spark作为他们的大数据解决方案。
PySpark
Spark是用Scala写的,整个Spark生态系统需要运行在JVM环境中,并且需要利用本地的HDFS。Hadoop的HDFS是Spark支持的数据存储之一。Spark可以处理不同类型的数据资源、种类、格式等。
PySpark提供了Spark集成的API,并允许在集群中的所有节点上使用Python的生态系统。更重要的是,它提供Python机器学习的库(如sklearn)和数据处理方法(pandas)。
PySpark的工作原理如下图:

Anaconda
- Python的IDE非常多,目前比较适合用来进行科学计算的是anaconda平台;
- anaconda有非常好的集成性,包升级的速度也非常快;
- 包含众多流行的科学、数学、工程包,以及数据分析、数据挖掘和机器学习库等,且完全开源免费。
- 支持平台:Windows、Linux、Mac;
更多信息可到官网了解:anaconda
Spark总体安装步骤
- 搭建环境:Linux(Ubuntu16.04)
- 安装Java SDK(Software Development Kit)
- 安装带Python2.7版本的Anaconda
- 安装Spark2.0
- 配置环境变量
Spark具体安装过程
1、搭建开发环境
本人使用Ubuntu16.04系统的台式机。若是Windows系统可以使用虚拟机创建Linux环境,具体过程自查Google,这里不再赘述。
2、安装带有Python2.7的Anaconda
具体安装过程自查Google,也可参考本人这篇博客:IPython Notebook介绍及在Ubuntu16.04下的安装使用
3、安装Java 8
- 安装Java 8 可参考下列命令:
# install oracle java 8
$ sudo apt-get install software-properties-common
$ sudo add-apt-repository ppa:webupd8team/java
$ sudo apt-get update
$ sudo apt-get install oracle-java8-installer- 设置JAVA_HOME环境变量;
- 检查你的JAVA_HOME环境变量是否生效:
$ echo JAVA_HOME4、安装Spark
在本地设置和运行Spark非常简单,只需要下载一个预构建的包。另外只要安装Java SDK和Python就可以在Windows、Linux、Mac上运行Spark。直接到Spark下载页面进行下载:Spark官网下载
具体操作:
- 选择Spark版本:Spark2.0.2(发布于2016.11.14);
- 选择下载包的类型:Pre-built for Hadoop 2.7 and later;
- 选择下载类型:Direct Download;
接下来,对下载文件进行操作:
- 解压
tar -xf spark-2.0.0-bin-hadoop2.7- 删除压缩包
rm spark-2.0.2-bin-hadoop2.7.tgz- 将解压文件移至~/spark文件夹
sudo mv spark-2.0.0-bin-hadoop2.7 ~/spark至此,Spark安装已完成。如果你的安装过程没有错误的话,运行下列命令:
#run spark
$ cd ~/spark
$ ./bin/pyspark你将会看到界面出现一个类似Spark的图标:
5、配置环境变量
- 进入/etc/profile修改:
$ sudo vim /etc/profile- 在末尾加入:
export ANACONDA_ROOT=~/anaconda2
export PYSPARK_DRIVER_PYTHON=$ANACONDA_ROOT/bin/ipython notebook
export PYSPARK_PYTHON=$ANACONDA_ROOT/bin/python
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
- 立即生效:
$ source /etc/profile运行WordCount例子
最后来运行WordCount例子,验证是否一切正常:
#import module
import re
from operator import add
#read input file
file_in = sc.textFile('/home/spark/WordCount.txt')
#count lines
print 'number of lines in file: %s' % file_in.count()
#add up lenths of each line
chars = file_in.map(lambda s: len(s)).reduce(add)
print 'number of cjaracters in file: %s' % chars
#get words from the input file
words = file_in.flatMap(lambda line: re.split('\W+',line.lower().strip()))
#words of more than 3 characters
words = words.filter(lambda x: len(x) > 3)
#set count 1 per word
words = words.map(lambda w: (w,1))
#reduce phase - sum count all the words
words = words.reduceByKey(add)
#create tuple (count,words) and sort in descending
words = words.map(lambda x: (x[1],x[0])).sortByKey(False)
words.take(10)输出:
number of lines in file: 11
number of cjaracters in file: 3264
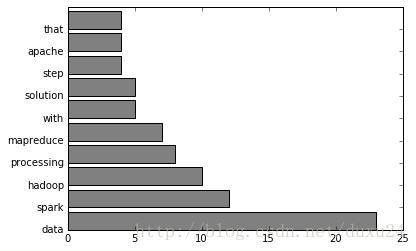
[(23, u'data'),
(12, u'spark'),
(10, u'hadoop'),
(8, u'processing'),
(7, u'mapreduce'),
(5, u'with'),
(5, u'solution'),
(4, u'step'),
(4, u'apache'),
(4, u'that')]可视化:
#create function for histogram of most frequent words
% matplotlib inline
import matplotlib.pyplot as plt
#plt.figure(figsize=(8,6))
def histogram(words):
count = map(lambda x: x[1], words)
word = map(lambda x: x[0], words)
plt.barh(range(len(count)), count,color = 'grey')
plt.yticks(range(len(count)), word)
plt.show()
# display histogram
histogram(words.take(10))可视化结果: