《DeepLab-ResNet rebuilt in TensorFlow》代码运行阅读笔记
初步接触图像分割领域,跑一个经典的代码看看效果,挖掘灵感
这是2017年CVPR上的工作《DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs》
ubuntu16下的环境搭建
首先,需要下载以下几个文件:代码链接中的工程文件,deeplab_resnet.ckpt这个训练好的模型参数,VOC2012数据集(其中SegmentationClass需要替换为SegmentationClassAug)。这些东西代码链接中都有,仔细看看。
然后,搭建python2.7下的tensorflow的环境
首先安装anaconda,然后在控制台输入以下命令
conda create -n easytensor27 python=2.7//创建名为easytensor27的虚拟环境
source activate easytensor27 //进入虚拟环境
anaconda search -t conda tensorflow //查看tensorflow的链接
anaconda show anaconda/tensorflow-gpu
conda install --channel https://conda.anaconda.org/anaconda tensorflow-gpu //安装tensorflow
python
source activate easytensor27
pip install -r requirements.txt //进入工程目录下,安装依赖的包
用pycharm打开工程,应用虚拟环境,修改train.py中的三个地方
DATA_DIRECTORY=''中间写数据集存储的地方load函数中,写上模型参数存储的地方再根据GPU显存大小,修改一下BATCH_SIZE的大小
即可运行train.py

代码阅读(按照程序运行流程)
-
命令行参数解析
Python标准库推荐使用的命令行参数解析模块——Argparse
- add_argument()方法,用来设置程序可接受的命令行参数。
- 现在要运行程序,就必须设置一个参数(或者有defualt)。
- parse_args()方法实际上从我们的命令行参数中返回了一些数据
args = get_arguments()-
获取窗口大小
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。h, w = map(int, args.input_size.split(','))
input_size = (h, w)-
设置graph级别的随机种子
在Graph中,我们通过tf.set_random_seed()函数对该图资源下的全局随机数生成种子进行设置,使得不同Session中的random系列函数表现出相对协同的特征,这就是Graph-Level的表现。
tf.set_random_seed(args.random_seed)-
数据获取与线程管理
载入数据的教程
首先要知道TensorFlow(TF)是怎么样工作的。
TF的核心是用C++写的,这样的好处是运行快,缺点是调用不灵活。而Python恰好相反,所以结合两种语言的优势。涉及计算的核心算子和运行框架是用C++写的,并提供API给Python。Python调用这些API,设计训练模型(Graph),再将设计好的Graph给后端去执行。简而言之,Python的角色是Design,C++是Run。
Tensorflow数据读取有三种方式:
- Preloaded data: 预加载数据
- Feeding: Python产生数据,再把数据喂给后端。
- Reading from file: 从文件中直接读取
前两种方案的缺点:
1、预加载:将数据直接内嵌到Graph中,再把Graph传入Session中运行。当数据量比较大时,Graph的传输会遇到效率问题。
2、用占位符替代数据,待运行的时候填充数据。
前两种方法很方便,但是遇到大型数据的时候就会很吃力,即使是Feeding,中间环节的增加也是不小的开销,比如数据类型转换等等。最优的方案就是在Graph定义好文件读取的方法,让TF自己去从文件中读取数据,并解码成可使用的样本集。
从文件中读取,简单来说就是将数据读取模块的图搭好
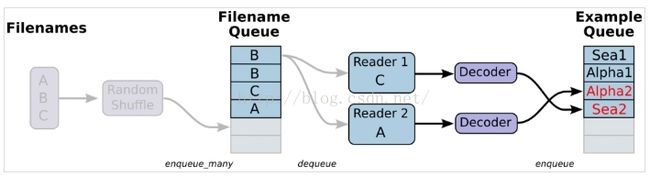
coord = tf.train.Coordinator() #的目的就是创建一个协调器,管理线程,这会在文件名入队时起作用
coord = tf.train.Coordinator()接下来加载reader
tf.name_scope 主要结合 tf.Variable() 来使用,方便参数命名管理。
用之前命令行解析的参数构建一个自定义的ImageReader对象并调用dequeue,构建计算图中的image_batch和label_batch节点
with tf.name_scope("create_inputs"):
reader = ImageReader(
args.data_dir,
args.data_list,
input_size,
args.random_scale,
args.random_mirror,
args.ignore_label,
IMG_MEAN,
coord)
image_batch, label_batch = reader.dequeue(args.batch_size)-
创建网络
用一个继承自自定义Network的自定义类DeepLabResNetModel创建网络结构。
执行Network的__init__函数,核心部分在DeepLabResNetModel中的setup函数,针对setup函数作以下几点说明。
- 网络输入的是image_batch
- 创建各层的步骤如下:
- feed:用已经存在的节点作为输入(第一个节点data是在__init__函数中定义的),返回network本身
- 各种功能的层的叠加都是通过Network这个类的函数做到的。返回self、调用layer函数(@标识符)、调用类的操作函数(conv、relu、pool、fc、batch_norm等)
- 借助is_training函数,可以对batch_norm层的参数进行锁定,不让更新
- 网络输出 fc1_voc12
def spamrun(fn):
@spamrun
def useful(a,b):
if __name__ == "__main__"
useful(2,5)
等价于
def spamrun(fn):
def useful(a,b):
if __name__ == "__main__"
useful = spamrun(useful)
useful(a,b)
-
统计获取可训练变量
restore_var = [v for v in tf.global_variables() if 'fc' not in v.name or not args.not_restore_last]
all_trainable = [v for v in tf.trainable_variables() if 'beta' not in v.name and 'gamma' not in v.name]
fc_trainable = [v for v in all_trainable if 'fc' in v.name]
conv_trainable = [v for v in all_trainable if 'fc' not in v.name] # lr * 1.0
fc_w_trainable = [v for v in fc_trainable if 'weights' in v.name] # lr * 10.0
fc_b_trainable = [v for v in fc_trainable if 'biases' in v.name] # lr * 20.0
assert(len(all_trainable) == len(fc_trainable) + len(conv_trainable))
assert(len(fc_trainable) == len(fc_w_trainable) + len(fc_b_trainable))-
网络输出整形
将前几个维度整合,为一个类别的目标输出mask。
raw_prediction = tf.reshape(raw_output, [-1, args.num_classes])-
label整形
一种简单的方式就是男性为0,女性为1,其他为2。使用上面简单的序列对分类值进行表示后,进行模型训练时可能会产生一个问题就是特征的因为数字值得不同影响模型的训练效果,在模型训练的过程中不同的值使得同一特征在样本中的权重可能发生变化,假如直接编码成1000,是不是比编码成1对模型的的影响更大。为了解决上述的问题,使训练过程中不受到因为分类值表示的问题对模型产生的负面影响,引入独热码对分类型的特征进行独热码编码。
用临界点插值 的方式将label整形成输出特征的大小。不过没有进行独热码编码。
然后再拉长
label_proc = prepare_label(label_batch, tf.stack(raw_output.get_shape()[1:3]), num_classes=args.num_classes, one_hot=False)
raw_gt = tf.reshape(label_proc, [-1,])
-
排除超出21类的标签,生成最终计算的标签(,1)和预测结果(,21)
indices = tf.squeeze(tf.where(tf.less_equal(raw_gt, args.num_classes - 1)), 1)
gt = tf.cast(tf.gather(raw_gt, indices), tf.int32)
prediction = tf.gather(raw_prediction, indices)-
计算loss
tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None,labels=None,logits=None,name=None) 函数是将softmax和cross_entropy放在一起计算,对于分类问题而言,最后一般都是一个单层全连接神经网络,比如softmax分类器居多,对这个函数而言,tensorflow神经网络中是没有softmax层,而是在这个函数中进行softmax函数的计算。
tf.trainable_variables返回的是需要训练的变量列表,加了trainable=False的变量不返回,当变量名中有weights的时候,计算L2正则化的结果。有108项内容,卷积w104加上全连接层w4。tf.nn.l2_loss一般用于优化的目标函数中的正则项,防止参数太多复杂容易过拟合。(output = sum(t ** 2) / 2)
第一个loss的所有项取平均值,与后一个正则化loss所有项加起来,得到最终loss
# Pixel-wise softmax loss.
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=prediction, labels=gt)
l2_losses = [args.weight_decay * tf.nn.l2_loss(v) for v in tf.trainable_variables() if 'weights' in v.name]
reduced_loss = tf.reduce_mean(loss) + tf.add_n(l2_losses)-
summary操作
将预测结果,标签,原始图像写入。
# Processed predictions: for visualisation.
raw_output_up = tf.image.resize_bilinear(raw_output, tf.shape(image_batch)[1:3,])
raw_output_up = tf.argmax(raw_output_up, dimension=3)
pred = tf.expand_dims(raw_output_up, dim=3)
# Image summary.
images_summary = tf.py_func(inv_preprocess, [image_batch, args.save_num_images, IMG_MEAN], tf.uint8)
labels_summary = tf.py_func(decode_labels, [label_batch, args.save_num_images, args.num_classes], tf.uint8)
preds_summary = tf.py_func(decode_labels, [pred, args.save_num_images, args.num_classes], tf.uint8)
total_summary = tf.summary.image('images',
tf.concat(axis=2, values=[images_summary, labels_summary, preds_summary]),
max_outputs=args.save_num_images) # Concatenate row-wise.
summary_writer = tf.summary.FileWriter(args.snapshot_dir,
graph=tf.get_default_graph())-
定义梯度更新时的一些参数
base_lr = tf.constant(args.learning_rate)
step_ph = tf.placeholder(dtype=tf.float32, shape=())
learning_rate = tf.scalar_mul(base_lr, tf.pow((1 - step_ph / args.num_steps), args.power))
opt_conv = tf.train.MomentumOptimizer(learning_rate, args.momentum)
opt_fc_w = tf.train.MomentumOptimizer(learning_rate * 10.0, args.momentum)
opt_fc_b = tf.train.MomentumOptimizer(learning_rate * 20.0, args.momentum)
-
计算梯度
计算卷积层可更新参数,全连接层可更新参数的梯度,分别放在不同位置上
grads = tf.gradients(reduced_loss, conv_trainable + fc_w_trainable + fc_b_trainable)
grads_conv = grads[:len(conv_trainable)]
grads_fc_w = grads[len(conv_trainable) : (len(conv_trainable) + len(fc_w_trainable))]
grads_fc_b = grads[(len(conv_trainable) + len(fc_w_trainable)):]-
用梯度更新参数
train_op_conv = opt_conv.apply_gradients(zip(grads_conv, conv_trainable))
train_op_fc_w = opt_fc_w.apply_gradients(zip(grads_fc_w, fc_w_trainable))
train_op_fc_b = opt_fc_b.apply_gradients(zip(grads_fc_b, fc_b_trainable))
train_op = tf.group(train_op_conv, train_op_fc_w, train_op_fc_b)-
创建session,执行init
# Set up tf session and initialize variables.
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
init = tf.global_variables_initializer()
sess.run(init)-
创建saver,保存checkpoint
saver = tf.train.Saver(var_list=tf.global_variables(), max_to_keep=10)-
加载checkpoint
# Load variables if the checkpoint is provided.
if args.restore_from is not None:
loader = tf.train.Saver(var_list=restore_var)
load(loader, sess, args.restore_from)-
执行训练循环
threads = tf.train.start_queue_runners(coord=coord, sess=sess)
# Iterate over training steps.
for step in range(args.num_steps):
start_time = time.time()
feed_dict = { step_ph : step }
if step % args.save_pred_every == 0:
loss_value, images, labels, preds, summary, _ = sess.run([reduced_loss, image_batch, label_batch, pred, total_summary, train_op], feed_dict=feed_dict)
summary_writer.add_summary(summary, step)
save(saver, sess, args.snapshot_dir, step)
else:
loss_value, _ = sess.run([reduced_loss, train_op], feed_dict=feed_dict)
duration = time.time() - start_time
print('step {:d} \t loss = {:.3f}, ({:.3f} sec/step)'.format(step, loss_value, duration))
coord.request_stop()
coord.join(threads)