新浪微博爬虫
详解新浪微博爬取过程
前言
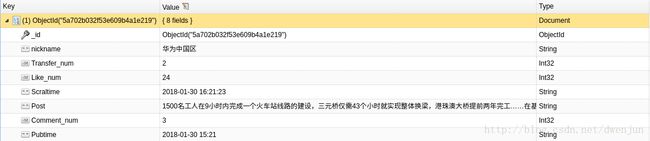
因为科研需要,我从16年8月起就开始跟微博数据打交道,所以从那时开始就不得不想尽办法爬取微博数据,我爬取的内容主要是:博文、发博账号、发文时间、爬取时间、点赞数/评论数/转发数,详情如图1。经过长时间的总结和实验,我完善了切实可行的爬虫代码,代码被我放在github上,同样你也可以在我的个人博客open-source里面查看到weibospider项目。
欢迎大家fork和star我的项目,项目地址,谢谢!
环境
linux+Python3.6+mongo
但是万变不离其中,更改一下便可以用于其他语言和环境。
预登陆
我们都知道微博数据需要先登录才能爬取,而我们解决的办法是使用微博预登陆获得登录需要的必要参数,这一部分在/Prelogin.py 实现的。
def login_weibo(nick , pwd) :
#==========================获取servertime , pcid , pubkey , rsakv===========================
# 预登陆请求,获取到若干参数
prelogin_url = 'http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=%s&rsakt=mod&checkpin=1&client=ssologin.js(v1.4.15)&_=1400822309846' % nick
preLogin = getData(prelogin_url)
# 下面获取的四个值都是接下来要使用的
servertime = re.findall('"servertime":(.*?),' , preLogin.decode('utf-8'))[0]
pubkey = re.findall('"pubkey":"(.*?)",' , preLogin.decode('utf-8'))[0]
rsakv = re.findall('"rsakv":"(.*?)",' ,preLogin.decode('utf-8'))[0]
nonce = re.findall('"nonce":"(.*?)",' , preLogin.decode('utf-8'))[0]
#===============对用户名和密码加密================
# 好,你已经来到登陆新浪微博最难的一部分了,如果这部分没有大神出来指点一下,那就真是太难了,我也不想多说什么,反正就是各种加密,最后形成了加密后的su和sp
su = base64.b64encode(bytes(urllib.request.quote(nick) , encoding = 'utf-8'))
rsaPublickey = int(pubkey , 16)
key = rsa.PublicKey(rsaPublickey , 65537)
#稍微说一下的是在我网上搜到的文章中,有些文章里并没有对拼接起来的字符串进行bytes,这是python3的新方法好像是。rsa.encrypt需要一个字节参数,这一点和之前不一样。其实上面的base64.b64encode也一样
message = bytes(str(servertime) + '\t' + str(nonce) + '\n' + str(pwd) , encoding = 'utf-8')
sp = binascii.b2a_hex(rsa.encrypt(message , key))
#=======================登录=======================
#param就是激动人心的登陆post参数,这个参数用到了若干个上面第一步获取到的数据,可说的不多
param = {'entry' : 'weibo' , 'gateway' : 1 , 'from' : '' , 'savestate' : 7 , 'useticket' : 1 , 'pagerefer' : 'http://login.sina.com.cn/sso/logout.php?entry=miniblog&r=http%3A%2F%2Fweibo.com%2Flogout.php%3Fbackurl%3D' , 'vsnf' : 1 , 'su' : su , 'service' : 'miniblog' , 'servertime' : servertime , 'nonce' : nonce , 'pwencode' : 'rsa2' , 'rsakv' : rsakv , 'sp' : sp , 'sr' : '1680*1050' ,
'encoding' : 'UTF-8' , 'prelt' : 961 , 'url' : 'http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack'}
# 这里就是使用postData的唯一一处,也很简单
s = postData('http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.15)' , param)
# 好了,当你的代码执行到这里时,已经完成了大部分了,可是有很多爬虫童鞋跟我一样还就栽在了这里,假如你跳过这里直接去执行获取粉丝的这几行代码你就会发现你获取的到还是让你登陆的页面,真郁闷啊,我就栽在这里长达一天啊
# 好了,我们还是继续。这个urll是登陆之后新浪返回的一段脚本中定义的一个进一步登陆的url,之前还都是获取参数和验证之类的,这一步才是真正的登陆,所以你还需要再一次把这个urll获取到并用get登陆即可
urll = re.findall("location.replace\(\'(.*?)\'\);" , s)[0]
getData(urll)
#======================获取粉丝====================
# 如果你没有跳过刚才那个urll来到这里的话,那么恭喜你!你成功了,接下来就是你在新浪微博里畅爬的时候了,获取到任何你想获取到的数据了!
# 可以尝试着获取你自己的微博主页看看,你就会发现那是一个多大几百kb的文件了
但是需要注意这行代码,有时候会出现匹配不成功的问题,所以这个时候你需要打印出s检查一下问题
urll = re.findall("location.replace\(\'(.*?)\'\);" , s)[0]获取爬取账号的URL
这个过程你需要分析账号的规律,因为不同微博账号,可以代码规律不一样,url获取通过查看元素,查找到对应页面的地址。
解析页码
def get_content(self,text):
mongo = MongoDB()
reg = '(\d+)'
logger.info('解析获取网页数据...')
content = json.loads(text.decode("ascii"))['data']
soup = BeautifulSoup("" + content + "", "lxml")
tmp = soup.find_all("div", attrs={"class": "WB_detail"})
tmp2 = soup.find_all("div", attrs={"class":"WB_handle"})
if len(tmp) > 0 :
for i in range(len(tmp)):
item = {}
item["nickname"] = tmp[i].find("div", attrs={"class": "WB_info"}).find("a").get_text()
item["Post"] = tmp[i].find("div", attrs={"class": "WB_text W_f14"}).get_text().replace("\n", "").replace(" ","").replace( "\u200b", "")
# -*- 爬取发布时间 -*-
item["Pubtime"] = tmp[i].find("a", attrs={"class": "S_txt2"}).get("title")
# -*- 爬取转发数 -*-
if re.findall(reg,str(tmp2[i].find("span", attrs={"class": "line S_line1","node-type":"forward_btn_text"})), re.S):
item["Transfer_num"] = int(re.findall(reg,str(tmp2[i].find("span", attrs={"class": "line S_line1","node-type":"forward_btn_text"})), re.S)[0])
else:
item["Transfer_num"] = 0
# -*- 爬取评论数 -*-
if re.findall(reg, str(tmp2[i].find("span", attrs={"class": "line S_line1", "node-type": "comment_btn_text"})), re.S):
item["Comment_num"] = int(re.findall(reg, str(tmp2[i].find("span", attrs={"class": "line S_line1", "node-type": "comment_btn_text"})), re.S)[0])
else:
item["Comment_num"] = 0
# -*- 爬取点赞数 -*-
if re.findall(reg, str(tmp2[i].find("span", attrs={"node-type": "like_status"})), re.S):
item["Like_num"] = int(re.findall(reg, str(tmp2[i].find("span", attrs={"node-type": "like_status"})), re.S)[0])
else:
item["Like_num"] = 0
item["Scraltime"] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
if mongo.process_item(item)== "null":
break
else:
continue
定时登录设置
这一部分是我参考别人的代码,你也可以用参考其他方式
import sched, time
from program.Spider import Weibo_Spider
from program.Prelogin import getData
from program.logfile import logger
# 初始化sched模块的scheduler类
# 第一个参数是一个可以返回时间戳的函数,第二个参数可以在定时未到达之前阻塞。
schedule = sched.scheduler(time.time, time.sleep)
def domain():
weibospider = Weibo_Spider()
ID_urls = weibospider.ID_urls
for i in range(len(ID_urls)):
for j in range(len(ID_urls[i])):
logger.info('正在爬取第'+str(i)+"个账号 第"+str(j+1)+"条网页")
weibospider.get_content(text=getData(ID_urls[i][j]))
def perform(inc):
schedule.enter(inc, 0, perform, (inc,))
domain() # 需要周期执行的函数
def mymain():
schedule.enter(0, 0, perform, (86400,))预览结果
更改微博账号以及你自己url地址和微博账号id,然后运行/main.py文件,爬取过程如下图。
if __name__ == "__main__":
mymain()
schedule.run() # 开始运行,直到计划时间队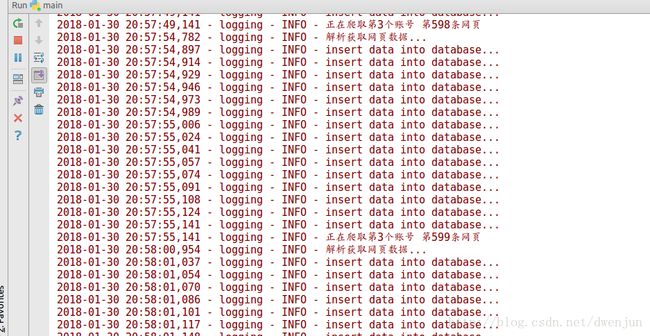
Tips
- 微博账号可以自己去淘宝买,如果爬取的内容比较多最好多买几个换着用。
- 前面也说了有时候正则匹配会出现问题,我也不知道为啥会时不时不能用,总的来说用起来没什么毛病。
- 个人觉得这些代码可以scrapy框架再整理一下。
- 如果大家发现还有什么毛病也欢迎联系我[email protected]。