凸优化简单学习笔记
本文来源于个人的凸优化学习笔记参考cs229 cvxoptnote,写成笔记的原因仅仅是想通过个人的笔记自己讲述与推导一下这些数学公式,内容可能会很简单,强力建议想得到一手资料的人好好学习文末参考资料
凸集合
定义就直接跳过了,这里简单写一些常见的凸集
- 凸集的交, 设 C i , i = 1 , 2 , 3 , . . . , n C_i,i = 1,2,3,...,n Ci,i=1,2,3,...,n 是凸集,那么我们有 ∩ i = 0 n C i \cap _{i=0}^n C_i ∩i=0nCi 也是凸集
- affine subspace 即 A x + b = 0 , x ∈ R n Ax+b=0,x \in R^n Ax+b=0,x∈Rn, 这既是 convex,也是concave
- 凸函数的sublevel 即 i f f ( x ) i s c o n v e x f u n c t i o n , t h e n { f ( x ) < = α } i s c o n v e x s e t if \ f(x)\ is\ convex\ function,then \{f(x) <=\alpha\} is\ convex\ set if f(x) is convex function,then{f(x)<=α}is convex set
凸函数
Define

性质,两条重点
- first-order-approximation
f ( y ) ≥ f ( x ) + ( ∇ f ( x ) ) T ( y − x ) f(y)\ge f(x)+(\nabla f(x))^T(y-x) f(y)≥f(x)+(∇f(x))T(y−x) - 二阶导数大于0
∇ x 2 f ( x ) ≥ 0 \nabla_x^2 f(x) \ge 0 ∇x2f(x)≥0
一些简单的凸函数
- Affine funciton
f ( x ) = A T x + b , x ∈ R n f(x) =A^Tx+b,x\in R^n f(x)=ATx+b,x∈Rn - quadratic function
f : R n − > R , f ( x ) = 2 − 1 x T A x + b T x + c , A ∈ S n , b ∈ R n , c ∈ R f:R^n->R,f(x) = 2^{-1}x^TAx+b^Tx+c,A\in S^n,b\in R^n,c\in R f:Rn−>R,f(x)=2−1xTAx+bTx+c,A∈Sn,b∈Rn,c∈R
这里简单说一下 ∇ 2 f ( x ) = A \nabla^2 f(x)=A ∇2f(x)=A, 因此如果 A A A 是半正定(positive-semidefinite)的,那么 f ( x ) f(x) f(x) is convex - Norm,e.g f ( x ) = ∣ ∣ x ∣ ∣ 2 2 f(x) = ||x||_2^2 f(x)=∣∣x∣∣22
- 凸函数的非负权重和
f ( x ) = ∑ i = 0 n c i f i ( x ) , f i ( x ) ∈ c o n v e x f u n c t i o n c l a s s f(x)=\sum_{i=0}^nc_if_i(x),f_i(x)\in convex\ function\ class f(x)=∑i=0ncifi(x),fi(x)∈convex function class - 凸函数集合的最大值函数
f ( x ) = max f i ( x ) , f i ( x ) ∈ c o n v e x f u n c t i o n c l a s s f(x) = \max f_i(x),f_i(x)\in convex\ function\ class f(x)=maxfi(x),fi(x)∈convex function class
证明:
f ( θ x + ( 1 − θ ) y ) = max f i ( θ x + ( 1 − θ ) y ) ≤ max θ f i ( x ) + ( 1 − θ ) f i ( y ) ≤ θ f ( x ) + ( 1 − θ ) f ( y ) \begin{aligned} f(\theta x + (1-\theta)y)&= \max f_i(\theta x + (1-\theta)y)\\ &\le \max \theta f_i(x) +(1-\theta)f_i(y)\\ &\le \theta f(x) + (1-\theta)f(y) \end{aligned} f(θx+(1−θ)y)=maxfi(θx+(1−θ)y)≤maxθfi(x)+(1−θ)fi(y)≤θf(x)+(1−θ)f(y)
凸优化问题
define

凸优化问题的局部最优解一定是全局最优解
接下来是凸优化问题最重要,也是最有趣的一个性质
证明
我们用反证法,
设 x ∈ R n , f ( x ) ∈ c o n v e x f u n c t i o n c l a s s x\in R^n,f(x) \in convex\ function\ class x∈Rn,f(x)∈convex function class,且, x x x 是 凸优化问题 f ( x ) f(x) f(x) 的一个局部最优解,那么我们有,在 x x x 的邻域中,i.e. ∣ ∣ x − z ∣ ∣ 2 < R ||x-z||_2 <R ∣∣x−z∣∣2<R ,不存在一个点 z z z,使得 f ( z ) < f ( x ) f(z)<f(x) f(z)<f(x), 同时,假设 x x x 不是全局最优解,那么我们有,在定义域中,存在一点 y , s . t . f ( y ) < f ( x ) y,s.t.\ f(y)<f(x) y,s.t. f(y)<f(x)
设 z = θ y + ( 1 − θ ) x , θ = R 2 ∣ ∣ x − y ∣ ∣ 2 z=\theta y + (1-\theta)x,\theta=\frac{R}{2||x-y||_2} z=θy+(1−θ)x,θ=2∣∣x−y∣∣2R,可以证明 ∣ ∣ x − z ∣ ∣ 2 = 2 − 1 R < R ||x-z||_2=2^{-1}R<R ∣∣x−z∣∣2=2−1R<R
同时,
f ( z ) = f ( θ y + ( 1 − θ ) x ) ≤ θ f ( y ) + ( 1 − θ ) f ( x ) ≤ f ( x ) \begin{aligned} f(z)&=f(\theta y + (1-\theta)x)\\ &\le \theta f(y)+(1-\theta)f(x)\\ &\le f(x) \end{aligned} f(z)=f(θy+(1−θ)x)≤θf(y)+(1−θ)f(x)≤f(x)
矛盾
一些机器学习的example
- 线性回归
J ( θ ) = ∣ ∣ W T Φ ( X ) − Y ∣ ∣ 2 2 = ∑ ( w t ϕ ( x i ) − y i ) 2 J(\theta) = ||W^T\Phi (X)-Y||_2^2=\sum (w^t\phi(x_i)-y_i)^2 J(θ)=∣∣WTΦ(X)−Y∣∣22=∑(wtϕ(xi)−yi)2
因为 f i ( w ) = ( w t ϕ ( x i ) − y i ) 2 f_i(w)=(w^t\phi(x_i)-y_i)^2 fi(w)=(wtϕ(xi)−yi)2 是一个复合affine 凸函数(i.e. x^2 是凸函数,而 w t ϕ ( x i ) − y i w^t\phi(x_i)-y_i wtϕ(xi)−yi 是对 w w w 的affine function) - logistic reg
J ( θ ) = − ∑ y i log g ( θ x i ) + ( 1 − y i ) log 1 − g ( θ x i ) J(\theta)=-\sum y_i\log g(\theta x_i) + (1-y_i)\log 1- g(\theta x_i) J(θ)=−∑yilogg(θxi)+(1−yi)log1−g(θxi) - SVM
SVM 的目标函数是一个 QP(quadratic opt) 问题, O ( n 3 ) O(n^3) O(n3)
这个问题还引出一些凸问题有趣的性质,比如lagrange duality 和 KKT,我们后面分析
lagrange & KKT
lagrange mutiplier
对于上面的凸优化问题来说,我们有它的lagrange function
L ( x , α , β ) = f ( x ) + ∑ α i g i ( x ) + ∑ β i h i ( x ) s . t . α i > = 0 \begin{aligned} \mathcal{L}(x,\alpha,\beta)&=f(x)+\sum \alpha_i g_i(x) + \sum \beta_i h_i(x)\\ &s.t. \alpha_i >=0 \end{aligned} L(x,α,β)=f(x)+∑αigi(x)+∑βihi(x)s.t.αi>=0
其中 x x x 称为 primal variable, α , β \alpha,\beta α,β 是dual variable
NOTE 其实可以将 α , β \alpha,\beta α,β 理解成打破原来约束的代价
primal & dual 原问题与对偶问题

中间那段 english 不用看,直接看形式就行了
我们下面试图证明这样一个弱对偶性(weak duality)
即 d ∗ = θ D ( α ∗ , β ∗ ) ≤ p ∗ = θ P ( x ∗ ) d^*=\theta_D(\alpha^*,\beta^*)\le p^*=\theta_P(x^*) d∗=θD(α∗,β∗)≤p∗=θP(x∗),反之(strong duality) 是说 d ∗ = p ∗ d^*=p^* d∗=p∗
原问题的解释
首先我们化简一下 θ P ( x ) \theta_P(x) θP(x)
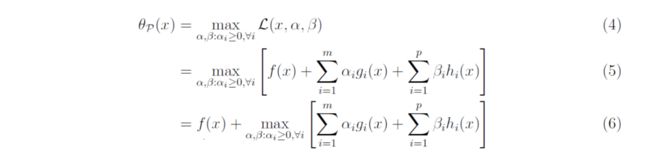
可以证明如下两个性质
- θ P ( x ) \theta_P(x) θP(x) 是一个凸函数
f ( x ) f(x) f(x) 是凸函数, g ( x ) g(x) g(x) 是凸函数, h ( x ) h(x) h(x) 是affine function α i ≥ 0 \alpha_i\ge 0 αi≥0, 所以, ∑ α i g ( x ) + β i h ( x ) \sum \alpha_i g(x) + \beta_i h(x) ∑αig(x)+βih(x) 也是凸函数,凸函数集合的最大值是凸函数,所以 θ P ( x ) \theta_P(x) θP(x) 是一个凸函数 - θ P ( x ) \theta_P(x) θP(x) 的简化

关于这一点,我们可以从上面化简后的例子得到
弱对偶性(weak duality)
θ D ( α , β ) = min L ( x , α , β ) ≤ L ( x ∗ , α , β ) ≤ f ( x ∗ ) + max { ∑ α i g ( x ∗ ) + β i h ( x ∗ ) } = θ P ( x ∗ ) ≤ p ∗ \begin{aligned} \theta_D(\alpha,\beta)&=\min \mathcal{L}(x,\alpha,\beta)\\ &\le \mathcal{L}(x^*,\alpha,\beta)\\ &\le f(x^*) + \max \{\sum \alpha_ig(x^*) + \beta_i h(x^*)\}\\ &=\theta_P (x^*)\\ &\le p^* \end{aligned} θD(α,β)=minL(x,α,β)≤L(x∗,α,β)≤f(x∗)+max{∑αig(x∗)+βih(x∗)}=θP(x∗)≤p∗
即 对偶问题的最优解总是小于等于原问题的最优解
当然强对偶性(strong duality) 指的就是 d ∗ = p ∗ d^*=p^* d∗=p∗ 了
不过这要满足一些条件,参考文献中指出 一个 Slater’s Condition ,指出如果存在一些可行解,严格满足所有的限制条件,即 g i ( x ) < 0 g_i(x)<0 gi(x)<0, 不过没有证明,同时指出几乎所有的图问题都满足 strong duility,这其实解释了为什么我们往往可以套用lagrange 乘数法求导解决这种限制性优化问题
接下来还有一个重要的结论,互补松弛(complementary slackness)
互补松弛(complementary slackness)
这个定理是说,如果强对偶性满足,那么我们有 a i ∗ g i ( x ∗ ) = 0 , i = 1 , 2 , … , m a_i^*g_i(x^*)=0,i =1,2,\dots,m ai∗gi(x∗)=0,i=1,2,…,m
简单证明一下
p ∗ = d ∗ = θ D ( α ∗ , β ∗ ) = min L ( x , α ∗ , β ∗ ) ≤ L ( x ∗ , α ∗ , β ∗ ) = f ( x ∗ ) + ∑ α i ∗ g ( x ∗ ) + β i ∗ h ( x ∗ ) ≤ f ( x ∗ ) = p ∗ \begin{aligned} p^*=d^*=\theta_D(\alpha^*,\beta^*)&=\min \mathcal{L}(x,\alpha^*,\beta^*)\\ &\le \mathcal{L}(x^*,\alpha^*,\beta^*)\\ &=f(x^*) + \sum \alpha_i^*g(x^*) + \beta_i^* h(x^*)\\ &\le f(x^*)\\ &= p^* \\ \end{aligned} p∗=d∗=θD(α∗,β∗)=minL(x,α∗,β∗)≤L(x∗,α∗,β∗)=f(x∗)+∑αi∗g(x∗)+βi∗h(x∗)≤f(x∗)=p∗
着意味着
∑ α i ∗ g i ( x ∗ ) + β i ∗ h ( x ∗ ) = ∑ α i ∗ g i ( x ∗ ) = 0 \begin{aligned} &\sum \alpha_i^*g_i(x^*) + \beta_i^* h(x^*)\\ &=\sum \alpha_i^*g_i(x^*)\\ &=0 \end{aligned} ∑αi∗gi(x∗)+βi∗h(x∗)=∑αi∗gi(x∗)=0
而我们有 α i ≥ 0 , g i ( x ) ≤ 0 , α i ∗ g i ( x ∗ ) ≤ 0 \alpha_i\ge 0, g_i(x)\le 0,\alpha_i^* g_i(x^*)\le 0 αi≥0,gi(x)≤0,αi∗gi(x∗)≤0, 最终,他们的和等于0,因此 α i ∗ g i ( x ∗ ) = 0 \alpha_i^* g_i(x^*)=0 αi∗gi(x∗)=0, 这意味着,
i f α i ∗ > 0 , t h e n , g i ( x ∗ ) = 0 o r i f g i ( x ∗ ) > 0 , t h e n , α i ∗ = 0 if\ \alpha_i^* >0,then,g_i(x^*)=0\\ or \\ if\ g_i(x^*)>0,then,\alpha_i^* =0 if αi∗>0,then,gi(x∗)=0orif gi(x∗)>0,then,αi∗=0
好,最后是 KKT条件,其实就是前几个性质的总结
KKT

参考
- cvxopt-note1
- cvxopt-note2
版权声明
本作品为作者原创文章,采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议
作者: taotao
转载请保留此版权声明,并注明出处