【论文笔记】DeepCut: Object Segmentation from Bounding Box Annotations using Convolutional Neural Networks
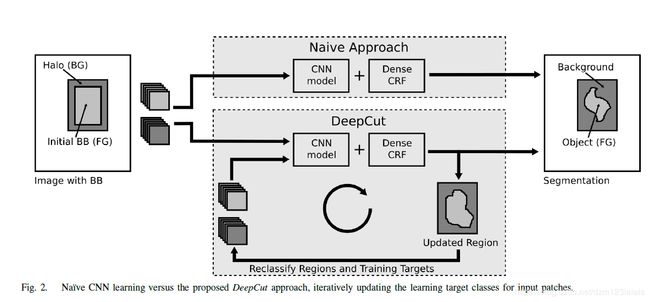
这篇论文提出了一种给定弱标注的实例分割方法。其将微软研究院提出的GrabCut进行扩展,可以实现给定bounding boxes的神经网络分类器训练。该论文将分类问题视为在稠密连接的条件随机场下的能量最小化问题,并通过不断迭代实现实例分割。

Abstract
In this paper, we propose DeepCut, a method to obtain pixelwise object segmentations given an image dataset labelled weak annotations, in our case bounding boxes. It extends the approach of the well-known GrabCut [1] method to include machine learning by training a neural network classifier from bounding box annotations. We formulate the problem as an energy minimisation problem over a densely-connected conditional random field and iteratively update the training targets to obtain pixelwise object segmentations. Additionally, we propose variants of the DeepCut method and compare those to a na¨ıve approach to CNN training under weak supervision. We test its applicability to solve brain and lung segmentation problems on a challenging fetal magnetic resonance dataset and obtain encouraging results in terms of accuracy
Method
让我们考虑在图上使用能量函数的分割问题,如[11]所述。我们为每个像素i寻找一个标记 f f f,以最小化:
E ( f ) = ∑ i ψ u ( f i ) + ∑ i < j ψ p ( f i , f j ) ( 1 ) E(f)=\sum_{i} \psi_{u}\left(f_{i}\right)+\sum_{i<j} \psi_{p}\left(f_{i}, f_{j}\right) \qquad\qquad (1) E(f)=i∑ψu(fi)+i<j∑ψp(fi,fj)(1)
其中, ψ u ( f i ) \psi_{u}\left(f_{i}\right) ψu(fi)作为一元数据的一致性项,测量给定数据的每个像素 i i i处标签 f f f的匹配度。另外,成对正则项 ψ p ( f i , f j ) \psi_{p}\left(f_{i}, f_{j}\right) ψp(fi,fj)惩罚任意两个像素位置 i i i和 j j j的标签差异。通常,成对正则化项的形式是:
ψ p ( f i , f j ) ∝ exp ( − ( I i − I j ) 2 2 θ β ) \psi_{p}\left(f_{i}, f_{j}\right) \propto \exp \left(-\frac{\left(I_{i}-I_{j}\right)^{2}}{2 \theta_{\beta}}\right) ψp(fi,fj)∝exp(−2θβ(Ii−Ij)2)
并在强度向量 I i I_i Ii和 I j I_j Ij之间执行对比度敏感的平滑度惩罚。我们可以把等式(1)中的能量最小化。使用连接紧密的CRF,其中将成对项替换为:
ψ p ( f i ) = g ( i , j ) [ f i ≠ f j ] \psi_{p}\left(f_{i}\right)=g(i, j)\left[f_{i} \neq f_{j}\right] ψp(fi)=g(i,j)[fi̸=fj]
由两个惩罚项组成,即造型外观(4a)和圆滑度(4b),分别位于pi和pj之间:
g ( i , j ) = ω 1 exp ( − ∣ p i − p j ∣ 2 2 θ α 2 − ∣ I i − I j ∣ 2 2 θ β 2 ) ( 4 a ) g(i, j)=\omega_{1} \exp \left(-\frac{\left|p_{i}-p_{j}\right|^{2}}{2 \theta_{\alpha}^{2}}-\frac{\left|I_{i}-I_{j}\right|^{2}}{2 \theta_{\beta}^{2}}\right) \qquad \qquad (4a) g(i,j)=ω1exp(−2θα2∣pi−pj∣2−2θβ2∣Ii−Ij∣2)(4a)
+ ω 2 exp ( − ∣ p i − p j ∣ 2 2 θ γ 2 ) ( 4 b ) +\omega_{2} \exp \left(-\frac{\left|p_{i}-p_{j}\right|^{2}}{2 \theta_{\gamma}^{2}}\right) \qquad \qquad (4b) +ω2exp(−2θγ2∣pi−pj∣2)(4b)
每个像素i的一元势由一个数据模型独立计算每个像素 i i i,该数据模型的参数 Θ \Theta Θ在给定输入图像或补丁x的标签分配过程中产生分布,并被定义为该概率的负对数可能性:
ψ u ( f i ) = − log P ( y i ∣ x , Θ ) \psi_{u}\left(f_{i}\right)=-\log P\left(y_{i} | x, \Theta\right) ψu(fi)=−logP(yi∣x,Θ)
相对于GrabCut,其中一元项是由观察到的颜色或强度矢量的GMM计算的,我们使用带有参数 Θ \Theta Θ的CNN。
一元势用CNN计算,二元势用CRF计算??
A. Segmentation by Iterative Energy Optimisation
所提出的DeepCut方法可以看作是一种类似于GrabCut的迭代能量最小化方法。算法中包含两个关键步骤: 模型评估和标签更新。GrabCut使用GMM来参数化前景和背景的颜色分布。在模型估计阶段,基于每个像素 i i i的当前标签分配 f f f计算GMM的参数 Θ \Theta Θ。在标签更新阶段像素被重新被新模型赋予标签。DeepCut用神经网络模型代替GMM,在密连通图上用DenseCRF中的图割求解器。我们没有重新计算我们的模型,而是利用迁移学习[32],用上一次迭代的参数重新初始化CNN。
Experiments
A. Image Data
在所有实验中,我们使用了[36]中的数据库,由55名胎儿的MR图像组成。采用T2加权ssFSE序列(扫描参数:TR 1000 ms,TE 98 ms,4mm片厚,0.4mm片隙)在1.5T MR扫描仪上获取图像。大多数图像都含有典型的运动艺术品。该人群由30名健康者和25名宫内生长受限(IUGR)患者组成,胎龄从20周到30周不等。对于所有的图像,大脑和肺区域都是由专家评分员手工分割的。我们想强调的是,实际上,大脑片段不是组织切片,而是整个大脑,类似于[37],[38]中使用的数据。
B. Preprocessing & Generation of Bounding Boxes
所有图像都进行了偏置场校正(一种MRI图像的预处理方法),并将图像强度归一化为从包围盒计算的零均值和单位标准差。边界盒 B B B是通过计算手动分割结果的最大范围,每片增加5个体素,从人工分割中产生的。background halo regions背景晕区 H H H是通过将B扩展为20个体素而形成的。
C. Comparative Methods
为了比较所提出的DeepCut方法的性能,我们固定了CNN的结构、预处理和CRF参数。我们可以考虑 C N N naive \mathrm{CNN}_{\text { naive }} CNN naive 精度性能的下限。或者,我们在完全监督下(即从像素分割, C N N F S CNN_{FS} CNNFS)直接训练CNN,并将其预测为 B B B,在给定模型复杂性和数据的情况下,可以认为这是一个较高的精度上界。我们评估通过包围框( D C B B DC_{BB} DCBB)或通过GrabCut预分割( D C P S DC_{PS} DCPS)初始化的建议的深度切割的性能。最后,我们陈述了GrabCut(GC)方法[1]的结果,用于在所提出的框架之外进行性能比较。
D. Experimental Setup, Evaluation & Parameter Selection
我们对随机选取的健康和IGUR受试者进行了5折交叉验证,并为所有比较方法建立了训练和测试数据库。通过使用Dice相似系数来评价由此产生的片段与专家手工分段的重叠程度,以衡量两个区域A和B之间的平均重叠:
D S C = 2 ∣ A ∩ B ∣ ∣ A ∣ + ∣ B ∣ D S C=\frac{2|A \cap B|}{|A|+|B|} DSC=∣A∣+∣B∣2∣A∩B∣