特征工程总结与学习
文章目录
- 1. 机器学习流程
- 2. 数值型数据
- 2.1 标量、向量和空间
- 2.2 处理计数
- 2.3 对数变换
- 2.4 特征缩放/归一化
- 2.5 交互特征
- 2.6 特征选择
- 3. 文本数据:扁平化、过滤和分块
- 3.1 元素袋:将自然文本转换为扁平向量
- 3.2 使用过滤获取清洁特征
- 4. 特征缩放的效果:从词袋到tf-idf
- 4.1 tf-idf: 词袋的一种简单扩展
- 5. 分类变量:自动化时代的数据计数
- 5.1 分类变量的编码
- 5.2 处理大型分类变量
- 6. 数据降维:使用PCA挤压数据
- 6.1 PCA直观理解
- 6.2 数学推导
小伙伴介绍了一本精通特征工程的书,觉得很不错,特将其进行学习和整理。
特征:原始数据某个方面的一种表示形式,是数据和模型之间的重要的纽带。
特征工程:是指从原始数据中提取特征并将其转换为适合机器学习模型的格式。
1. 机器学习流程
- 数据:是对现实世界的现象的观测。
- 统计中通常对数据有以下几种描述:错误数据,冗余数据及缺失数据。
- 特征工程就是在给定数据、模型和任务的情况下设计出最合适特征的过程。

2. 数值型数据
尽管数值型数据已经很容易被数学模型所使用了,但并不意味着不需要进行特征工程。好的特征不仅能够表示出数据的主要特点,还应该符合模型的假设,因此通常必须进行数据转换。
-
对于数值型数据,我们既要查看它的量级,又要查看它的尺度,即最大值和最小值分别是多少。通常K均值聚类、K近邻、径向基核函数及使用欧氏距离的方法对数据的尺度都是比较敏感的,通常需要对数据进行标准化,以便输出控制在期望的范围之内。相反,一些树模型对数据的尺度并不敏感,通常不需要进行标准化。
-
预测目标分布在多个数量级中的时候,在这种情况下,误差符合高斯分布的假定将不会被满足。一种解决方法是对输出目标进行转换,以消除数量级带来的影响。(严格说来,这应该称为目标工程,而不是特征工程。)对数变换(指数变换的一种特殊形式)可以使变量的分布更加接近于高斯分布。
2.1 标量、向量和空间
- 标量:单独的数值型特征
- 向量:标量的有序列表,向量位于向量空间中,在绝大多数机器学习应用中,模型的输入通常表示为数值向量。
2.2 处理计数
当数据被大量且快速地生成时,很有可能包含一些极端值。这时就应该检查数据的尺度,确定是应该保留数据原始的数值形式,还是应该将它们转换成二值数据,或者进行粗粒度的分箱操作。
2.2.1 二值化
假设我们的任务是创建一个向用户推荐歌曲的推荐器,它的一个功能是预测某个用户喜欢
某首歌曲的程度。如果高收听次数意味着用户真的喜欢这首歌,低收听次数意味着用户对这首歌不感兴趣,那么就可以用它作为目标变量。但是,数据表明,尽管 99% 的收听次数是 24 或更低,还是有一些收听次数达到了几千,最大值是 9667。这些值高得离谱,如果我们试图去预测实际的收听次数,模型会被这些异常值严重带偏。
在百万歌曲数据集中,原始的收听次数并不是衡量用户喜好的强壮指标。(在统计学术语中,“强壮”意味着该方法适用于各种情况。)不同的用户有不同的收听习惯,有些人会无限循环地播放他们最喜欢的歌曲,有些人则只是在特定情形下欣赏音乐。我们不能认为收听了某首歌曲 20 次的人喜欢该歌曲的程度肯定是收听了 10 次的人的两倍。更强壮的用户偏好表示方法是将收听次数二值化,把所有大于 1 的次数值设为 1。换言之,如果用户收听了某首歌曲至少一次,那么就认为该用户喜欢该歌曲。这样,模型就不用花费开销来预测原始收听次数之前的时间差别。二值目标变量是一个既简单又强壮的用户偏好衡量指标。
2.2.2 区间量化(分箱)
假设一份数据集是用户对商家的点评数据,每个商家都有一个点评数量。点评数量会是一个非常有用的输入特征,因为人气和高评分之间通常有很强的相关性。实际情况可能是大多数商家的点评数量很少,但有些商家具有几千条点评。
原始的点评数量横跨了若干个数量级,这对很多模型来说都是个问题。数据向量某个元素中过大的计数值对相似度的影响会远超其他元素,从而破坏整体的相似度测量。
一种解决方法是对计数值进行区间量化,然后使用量化后的结果。换言之,我们将点评数量分到多个箱子里面,去掉实际的计数值。区间量化可以将连续型数值映射为离散型数
值,我们可以将这种离散型数值看作一种有序的分箱序列,它表示的是对密度的测量。
为了对数据进行区间量化,必须确定每个分箱的宽度。有两种确定分箱宽度的方法:固定
宽度分箱和自适应分箱。
1. 固定宽度分箱
通过固定宽度分箱,每个分箱中会包含一个具体范围内的数值。这些范围可以人工定制,也可以通过自动分段来生成,它们可以是线性的,也可以是指数性的。例如,我们可以按10 年为一段来将人员划分到多个年龄范围中: 0 ~ 9岁的在分箱1中,10 ~ 19 岁的在分箱 2中,等等。要将计数值映射到分箱,只需用计数值除以分箱的宽度,然后取整数部分。
当数值横跨多个数量级时,最好按照 10 的幂(或任何常数的幂)来进行分组: 0~9、
10 ~ 99、 100 ~ 999、 1000~9999,等等。这时分箱宽度是呈指数增长的,从 O(10) 到O(100)、O(1000) 以及更大。要将计数值映射到分箱,需要取计数值的对数。指数宽度分箱与对数变换的关系非常紧密。
2. 分位数分箱
固定宽度分箱非常容易计算,但如果计数值中有比较大的缺口,就会产生很多没有任何数
据的空箱子。根据数据的分布特点,进行自适应的箱体定位,就可以解决这个问题。这种
方法可以使用数据分布的分位数来实现。
分位数是可以将数据划分为相等的若干份数的值。例如,中位数(即二分位数)可以将数
据划分为两半,其中一半数据点比中位数小,另一半数据点比中位数大。四分位数将数据
四等分,十分位数将数据十等分,等等。
2.3 对数变换
对数函数是指数函数的反函数,它的定义是 loga(ax) = x,其中 a 是个正的常数, x 可以是
任意正数。因为 a0 = 1,所以有 loga(1) = 0。这意味着对数函数可以将 (0, 1) 这个小区间中
的数映射到 (-∞, 0) 这个包括全部负数的大区间上。函数 log10(x) 可以将区间 [1, 10] 映射到
[0, 1],将 [10, 100] 映射到 [1, 2],以此类推。换言之,对数函数可以对大数值的范围进行压缩,对小数值的范围进行扩展。 x 越大, log(x) 增长得越慢。
通过查看对数函数的图形,可以更好地理解上面的内容。注意一下横轴上从100 到 1000 的 x 值是如何被压缩到纵轴上从 2.0 到 3.0 的 y 值的,小于 100 的 x 值只占横轴的一小部分,但通过对数函数的映射,却占据了纵轴的剩余部分。

2.4 特征缩放/归一化
有些特征的值是有界限的,比如经度和纬度,但有些数值型特征可以无限制地增加,比如
计数值。有些模型是输入的平滑函数,比如线性回归模型、逻辑回归模型或包含矩阵的模
型,它们会受到输入尺度的影响。相反,那些基于树的模型则根本不在乎输入尺度有多大。如果模型对输入特征的尺度很敏感,就需要进行特征缩放。顾名思义,特征缩放会改变特征的尺度,有些人将其称为特征归一化。
2.4.1 min-max缩放

令 x 是一个独立的特征值(即某个数据点中的特征值), min(x) 和 max(x) 分别为这个特征在整个数据集中的最小值和最大值。 min-max 缩放可以将所有特征值压缩(或扩展)到 [0, 1]区间中。
2.4.2 特征标准化/方差缩放
特征标准化可以用下面的公式来定义:
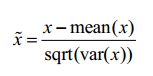
它先减去特征的均值(对所有数据点),再除以方差,因此又称为方差缩放。缩放后的特征均值为 0,方差为 1。如果初始特征服从高斯分布,那么缩放后的特征也服从高斯分布。

2.5 交互特征
两个特征的乘积可以组成一对简单的交互特征,这种相乘关系可以用逻辑操作符 AND 来类比,它可以表示出由一对条件形成的结果:“该购买行为来自于邮政编码为 98121 的地区” AND“用户年龄在 18 和 35 岁之间”。这种特征在基于决策树的模型中极其常见,在广义线性模型中也经常使用。
交互特征的构造非常简单,使用起来却代价不菲。如果线性模型中包含有交互特征对,那它的训练时间和评分时间就会从 O(n) 增加到 O(n2),其中 n 是单一特征的数量。
有若干种方法可以绕过高阶交互特征所带来的计算成本。我们可以在构造出所有交互特征之后再执行特征选择,或者,也可以更加精心地设计出少量复杂特征。
这两种策略各有千秋。特征选择使用计算手段为一个具体问题选择出最佳特征。(这种技术并不局限于交互特征。)但是,一些特征选择技术仍然需要使用大量特征去训练多个模型。
2.6 特征选择
特征选择技术可以精简掉无用的特征,以降低最终模型的复杂性,它的最终目的是得到一个简约模型,在不降低预测准确率或对预测准确率影响不大的情况下提高计算速度。为了得到这样的模型,有些特征选择技术需要训练不止一个待选模型。换言之,特征选择不是为了减少训练时间(实际上,一些技术会增加总体训练时间),而是为了减少模型评分时间。
特征选择技术可以分为以下三类。
过滤
过滤技术对特征进行预处理,以除去那些不太可能对模型有用处的特征。例如,我们可以计算出每个特征与响应变量之间的相关性或互信息,然后过滤掉那些在某个阈值之下的特征。过滤技术的成本比下面描述的打包技术低廉得多,但它们没有考虑我们要使用的模型,因此,它们有可能无法为模型选择出正确的特征。我们最好谨慎地使用预过滤技术,以免在有用特征进入到模型训练阶段之前不经意地将其删除。
打包
这些技术的成本非常高昂,但它们可以试验特征的各个子集,这意味着我们不会意外地删除那些本身不提供什么信息但和其他特征组合起来却非常有用的特征。打包方法将模型视为一个能对推荐的特征子集给出合理评分的黑盒子。它们使用另外一种方法迭代地对特征子集进行优化。
嵌入
这种方法将特征选择作为模型训练过程的一部分。例如,特征选择是决策树与生俱来的一种功能,因为它在每个训练阶段都要选择一个特征来对树进行分割。另一个例子是ℓ1 正则项,它可以添加到任意线性模型的训练目标中。 ℓ1 正则项鼓励模型使用更少的特征,而不是更多的特征,所以又称为模型的稀疏性约束。嵌入式方法将特征选择整合为模型训练过程的一部分。它们不如打包方法强大,但成本也远不如打包方法那么高。与过滤技术相比,嵌入式方法可以选择出特别适合某种模型的特征。从这个意义上说,嵌入式方法在计算成本和结果质量之间实现了某种平衡。
3. 文本数据:扁平化、过滤和分块
3.1 元素袋:将自然文本转换为扁平向量
词袋将一个文本文档转换为一个扁平向量,之所以说这个向量是“扁平”的,是因为它不包含原始文本中的任何结构。原始文本是一个单词序列,但词袋中没有任何序列,它只记录每个单词在文本中出现的次数。因此,向量中单词的顺序根本不重要,只要它在数据集的所有文档之间保持一致即可。词袋也不表示任何单词层次。例如,“animal”这个概念包括“dog”“cat”“raven”等,但在词袋表示中,这些单词在向量中都是平等的元素。
词袋是一种简单而有效的启发式方法,但离正确的文本语义理解还相去甚远。
n 元 词 袋(bag-of-n-grams) 是 词 袋 的 一 种 自 然 扩 展。 n-gram(n 元 词 ) 是 由 n 个 标 记(token)组成的序列。 n-gram 能够更多地保留文本中的初始序列结构,因此 n 元词袋表示法可以表达更丰富的信息。然而,这不是没有代价的。理论上,有 k 个不同的单词,就会有 k*2 个不同的 2-gram(又称二元词)。实际上,没有这么多,因为不是每个单词都可以跟在另一个单词后面。尽管如此, n-gram(n>1)一般来说也会比单词多得多。这意味着 n 元词袋是一个更大也更稀疏的特征空间,也意味着 n 元词袋需要更强的计算、存储和建模能力。 n 越大,能表示的信息越丰富,相应的成本也会越高。
3.2 使用过滤获取清洁特征
停用词 :通常指一些带刺、冠词及介词等没有较大价值的词。停用词列表是一种剔除形成无意义特征的单词的方法。
基于频率的过滤 :高频词和罕见词
词干提取:一种将每个单词转换为语言学中的基本词干形式的 NLP 技术。词干提取有多种方法,有的基于语言学规则,有的基于统计观测。有一种算法子类综合了词性标注和语言
规则,这种处理过程称为词形还原。
词袋表示法简单易懂,容易计算,并对分类和搜索任务非常有效。但有时单个单词还是太简单了,无法表述出文本中的某些信息。为了解决这个问题,我们要求助于更长的序列。n 元词袋是词袋的一种自然推广,它的概念非常好理解,计算起来也和词袋一样容易。
n 元词袋可以生成大量互不相同的 n 元词,它增加了特征存储成本,在模型训练和预测阶段也需要更多计算能力。对于同样数量的数据点, n 元词袋使得特征空间的维度大大增加。因此,数据变得特别稀疏。 n 越大,存储和计算的成本就越高,数据也越稀疏。基于这些原因,更长的 n 元词并不是总能提高模型的准确率或带来其他方面的性能改善。通常只使用二元词和三元词,很少使用更长的 n 元词。
要解决稀疏性和成本增加的问题,一种方法是对 n 元词进行过滤,只保留那些最有意义的短语。这就是搭配提取的目标。理论上,搭配(或短语)可以形成文本中不连贯的标记序列,但实际上,找出不连贯的短语需要非常高的计算成本,而且收效甚微。所以,搭配提取通常从一个备选二元词列表开始,然后使用统计方法对其进行过滤。
所有这些方法都是将一个文本标记序列转换为一个与之无关的计数集合。相对于单词序列,集合中的结构很少,它们可以生成扁平的特征向量。
4. 特征缩放的效果:从词袋到tf-idf
4.1 tf-idf: 词袋的一种简单扩展
tf-idf 是在词袋方法基础上的一种简单扩展,它表示词频 - 逆文档频率。 tf-idf 计算的不是
数据集中每个单词在每个文档中的原本计数,而是一个归一化的计数,其中每个单词的计
数要除以这个单词出现在其中的文档数量。
tf-idf 的直观理解
tf-idf 突出了罕见词,并有效地忽略了常见词。
特征缩放实质上是数据矩阵上的列操作。特别地, tf-idf 和 ℓ2 归一化都是对整个列(例如,一个 n 元词特征)乘以一个常数。
特征缩放(包括 ℓ2 归一化和 tf-idf)的真正用武之地是加快解的收敛速度。
5. 分类变量:自动化时代的数据计数
文档语料库的词汇表可以表示为一个大型分类变量,类别就是唯一的单词。表示如此多的不同类别需要很高的计算成本。如果一个类别(如一个单词)在一个数据点(文档)中出现了多次,就可以将它表示为一个计数,并通过计数统计表示所有类别。这种方法称为分箱计数。
5.1 分类变量的编码
5.1.1 one-hot 编码
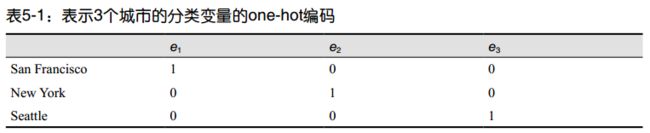
**one-hot 编码,**它可以通过 scikit-learn 中的 sklearn.preprocessing.OneHotEncoder 实现。每个比特位表示一个特征,因此,一个可能有 k 个类别的分类变量就可以编码为一个长度为 k 的特征向量。表 5-1给出了一个例子。
5.1.2 虚拟编码
one-hot 编码的问题是它允许有 k 个自由度,而变量本身只需要 k-1 个自由度。 虚拟编码 2在进行表示时只使用 k-1 个特征,除去了额外的自由度(见表 5-2)。没有被使用的那个特征通过一个全零向量来表示,它称为参照类。虚拟编码和 one-hot 编码都可以通过 Pandas包中的 pandas.get_dummies 来实现。

使用虚拟编码的模型结果比使用 one-hot 编码的模型结果更具解释性。
# 将数据框中的分类变量转换为one-hot编码
>>> one_hot_df = pd.get_dummies(df, prefix=['city'])
>>> one_hot_df
# 为虚拟编码训练一个线性回归模型,指定drop_first标志来生成虚拟编码
>>> dummy_df = pd.get_dummies(df, prefix=['city'], drop_first=True)
>>> dummy_df
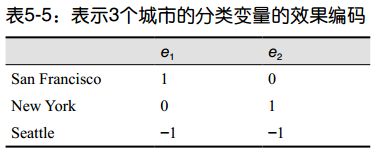
5.1.3 效果编码
效果编码与虚拟编码非常相似,区别在于参照类是用全部由 -1 组成的向量表示的,参见表 5-5。
5.1.4 各种分类变量编码的优缺点
one-hot 编码、虚拟编码和效果编码彼此之间非常相似,它们都有各自的优缺点。 one-hot编码有冗余,这会使得同一个问题有多个有效模型,这种非唯一性有时候比较难以解释。它的优点是每个特征都明确对应一个类别,而且可以把缺失数据编码为全零向量,模型输出也是目标变量的总体均值。
虚拟编码和效果编码没有冗余,它们可以生成唯一的可解释的模型。虚拟编码的缺点是不太容易处理缺失数据,因为全零向量已经映射为参照类了。它还会将每个类别的效果表示为与参照类的相对值,这看上去有点不直观。
效果编码使用另外一种编码表示参照类,从而避免了这个问题,但是全由 -1 组成的向量是个密集向量,计算和存储的成本都比较高。正是因为这个原因,像 Pandas 和 scikit-learn这样的常用机器学习软件包更喜欢使用虚拟编码或 one-hot 编码,而不是效果编码。
当类别的数量变得非常大时,这 3 种编码方式都会出现问题,所以需要另外的策略来处理超大型分类变量。
5.2 处理大型分类变量
5.2.1 特征散列化
散列函数是一种确定性函数,它可以将一个可能无界的整数映射到一个有限的整数范围
[1, m] 中。因为输入域可能大于输出范围,所以可能有多个值被映射为同样的输出,这称
为碰撞。 均匀散列函数可以确保将大致相同数量的数值映射到 m 个分箱中。
我们可以形象地将散列函数想象为一台机器,它吸入一些带数字标号的圆球(键),再把
它们分发到 m 个分箱中。标有同样数字的球总是被分发到同一个分箱中(见图 5-1)。散列
函数在保持特征空间的同时,又可以在机器学习的训练和评价周期中减少存储空间和处理
时间。

特征散列化对计算能力大有裨益,但牺牲了直观的用户可解释性。对于大数据集,当从数据探索和可视化进展到机器学习流程时,我们可以很容易地在二者之间做出取舍。
5.2.2 分箱计数
分箱计数的思想稍有一点复杂:它不使用分类变量的值作为特征,而是使用目标变量取这个值的条件概率。换句话说,我们不对分类变量的值进行编码,而是要计算分类变量值与要预测的目标变量之间的相关统计量。
5.3 小结

6. 数据降维:使用PCA挤压数据
通过自动数据收集和特征生成技术,可以快速获取大量特征,但不是所有特征都是有用的。主成分分析(principal component analysis, PCA)可以用来降低特征维度。
6.1 PCA直观理解
数据降维就是在保留重要信息的同时消除那些“无信息量的信息”。“无信息量”有多种定义方法,PCA 关注的是线性相关性。
我们将数据矩阵的列空间描述为所有特征向量的生成空间。如果列空间的秩小于特征总数,那么多数特征就是几个关键特征的线性组合。线性相关的特征是对空间和计算能力的浪费,因为它们包含的信息可以从更少的几个特征中推导出来。为了避免这种情况, PCA 试图将数据挤压到一个维度大大小于原空间的线性子空间,从而消除这些“臃肿”。
6.2 数学推导
令 X 表示 n×d 的数据矩阵,其中 n 是数据点的数量, d 是特征的数量。令 x是表示单个数据点的列向量(所以 x 是 X 中一行的转置)。令 v 是表示新特征的向量,即要找出的主成分。

6.2.1 线性投影
