MapReduce+MapReduce执行过程(四)
文章目录
- 1. MR原理
- 1.1 MapReduce 架构
- 1.2 Mapreduce运行流程
- 1.3 MapReduce中的Map和Reduce
- 2. 使用Hadoop Streaming -python写出WordCount
- 3. 使用mapreduce计算movielen中每个用户的平均评分
- 4. 使用mapreduce实现merge功能
- 5. 使用mapreduce实现去重任务
- 6. 使用mapreduce实现排序
- 7. 使用mapreduce实现倒排索引
- 8. 使用mapreduce计算Jaccard相似度
- 9. 使用mapreduce实现PageRank
【Task4】MapReduce+MapReduce执行过程
MR原理
使用Hadoop Streaming -python写出WordCount
使用mapreduce计算movielen中每个用户的平均评分。
使用mapreduce实现merge功能。根据item,merge movielen中的 u.data u.item
使用mapreduce实现去重任务。
使用mapreduce实现排序。
使用mapreduce实现倒排索引。
使用mapreduce计算Jaccard相似度。
使用mapreduce实现PageRank。
Python3调用Hadoop的API
1. MR原理
通俗易懂地理解MapReduce的工作原理
MapReduce工作原理(重点)
1.1 MapReduce 架构
在MapReduce中,用于执行MapReduce任务的机器角色有两个:JobTracker和TaskTracker。其中JobTracker是用于调度工作的,TaskTracker是用于执行工作的。一个Hadoop集群中只有一台JobTracker。
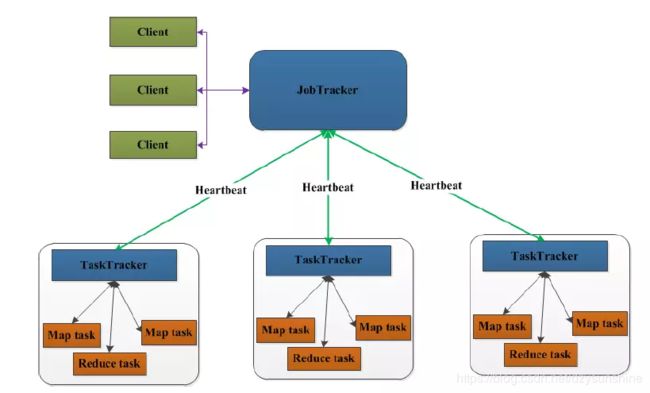
客户端向JobTracker提交一个作业,JobTracker把这个作业拆分成很多份,然后分配给TaskTracker去执行,TaskTracker会隔一段时间向JobTracker发送(Heartbeat)心跳信息,如果JobTracker在一段时间内没有收到TaskTracker的心跳信息,JobTracker会认为TaskTracker挂掉了,会把TaskTracker的作业任务分配给其他TaskTracker。
1.2 Mapreduce运行流程
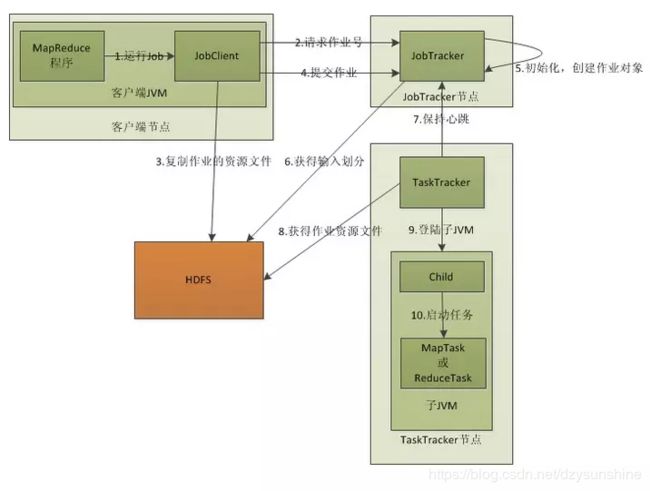
1、客户端启动一个job
2、向JobTracker请求一个JobID
3、将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息。这些文件都存放在JobTracker专门为该作业创建的文件夹中,文件夹名为该作业JobID。JAR文件默认会有10个副本,输入划分信息告诉JobTracker应该为这个作业启动多少个map任务等信息。
4、JobTracker接收到作业后将其放在作业队列中,等待JobTracker对其进行调度。当JobTracker根据自己的调度算法调度该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行。这里需要注意的是,map任务不是随便分配给某个TaskTracker的,Data-Local(数据本地化)将map任务分配给含有该map处理的数据库的TaskTracker上,同时将程序JAR包复制到该TaskTracker上运行,但是分配reducer任务时不考虑数据本地化。
5、TaskTracker每隔一段时间给JobTracker发送一个Heartbeat告诉JobTracker它仍然在运行,同时心跳还携带很多比如map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把作业设置成“成功”,JobClient再传达信息给用户。
1.3 MapReduce中的Map和Reduce
MapReduce 框架只操作键值对,MapReduce 将job的不同类型输入当做键值对来处理并且生成一组键值对作为输出。
(input) ->map-> ->combine-> ->reduce-> (output)
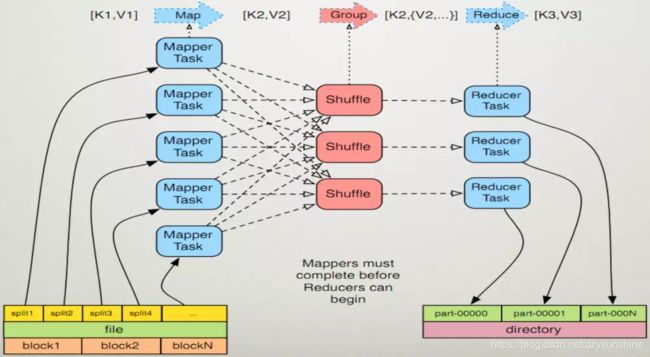

Shuffle过程
Collections.shuffle(List list):随机打乱list里的元素顺序。
MapReduce里的Shuffle:描述着数据从map task输出到reduce task输入的这段过程。

2. 使用Hadoop Streaming -python写出WordCount
这里前面已经写过,直接给出链接:学会写WordCount
3. 使用mapreduce计算movielen中每个用户的平均评分
这里开始进展比较困难,参考大佬的知乎专栏:MapReduce+MapReduce执行过程
由于要计算movielen数据集中每个用户的平均评分,所以我们要先把数据集下载下来。
- 下载链接1,下载链接2
上面两个都可以,数据集的相关介绍可以看这里——MovieLens数据集
Mrjob是一个编写MapRecuce任务的开源Python框架,它实际上对Hadoop Stream的命令进行了封装,因此让开发者接触不到Hadoop数据流命令行,使我们更轻松、快速编写MapReduce任务。
首先要安装mrjob
pip install mrjob
这里报错
![]()
这里说明缺少pip功能,采用以下方法解决
wget https://bootstrap.pypa.io/get-pip.py --no-check-certificate
python get-pip.py
![]()
安装成功!
运行MapReduce的方式:
- (1)内嵌(-r inline)方式,下面两种方式等价
python word_count.py -r inline input.txt > output.txt
python word_count.py input.txt > output.txt
- (2)本地(-r local)方式:用于本地模拟Hadoop调试,与内嵌(inline)方式的区别是启动了多进程执行每一个任务。
python word_count.py -r local input.txt > output1.txt
- (3)Hadoop(-r hadoop)方式
hadoop fs -chown -R hadoop:hadoop /tmp
#在执行MapReduce任务的时候hadoop用户会创建socket,通过jdbc访问。所以在执行你写得MapReduce之前一定要设置权限
python /MyMapReduce.py /a.txt -r hadoop
#在Hadoop集群,执行Python的MapReduce任务。
输入下列命令会将结果保存到文件夹:
hadoop fs -ls /output/hadoop_word
下面就用上面的第一种方法运行mapreduce:
要计算每个用户的平均评分需要用到ratings.csv文件,字段如下所示
userId,movieId,rating,timestamp
1,1,4.0,964982703
1,3,4.0,964981247
1,6,4.0,964982224
1,47,5.0,964983815
1,50,5.0,964982931
编写python文件,执行前不要忘了先把数据集下载好并移动到指定位置,程序如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from mrjob.job import MRJob
class MRratingAvg(MRJob):
'''
计算每个用户的平均评分
'''
def mapper(self, _, line):
user_id, item_id, rating, timestamp = line.strip().split(',')
if not user_id.isdigit():
return
yield user_id, float(rating)
def reducer(self, user_id, values):
#shuff and sort 之后
'''
(user_id,[rating1,rating2,rating3])
'''
l = list(values)
yield (user_id, sum(l)/len(l))
if __name__ == '__main__':
MRratingAvg.run()
运行命令:
python avgrating.py ratings.csv > avgrating.txt
会生成一个avgrating.txt文件,如下:

发现输出内容会带上引号,把reducer的函数中的yield改成print即可。
4. 使用mapreduce实现merge功能
根据item,merge movielen中的 u.data u.item。
这里用的数据是older datasets中的MovieLens 100K Dataset。u.data的数据以制表符分隔,字段有:
user id | item id | rating | timestamp.
u.item的数据以|分隔,字段有:
movie id | movie title | release date | video release date |
IMDb URL | unknown | Action | Adventure | Animation |
Children's | Comedy | Crime | Documentary | Drama | Fantasy |
Film-Noir | Horror | Musical | Mystery | Romance | Sci-Fi |
Thriller | War | Western |
这里需要对上述两个数据进行merge,他们的共同字段就是item id和movie id。为了方便,u.item中后面的字段我就不保存了,也就是说,最终得到的数据的字段是这样的:
user id | item id | movie title | rating
查看数据情况
head u.data

head u.item
#!/usr/bin/python
# -*- coding: utf-8 -*-
from mrjob.job import MRJob
class MRdataMerge(MRJob):
'''
根据user_id merge data和item
'''
def mapper(self, _, line):
line = line.split('|')
if len(line) > 1:
movie_id, movie_title = line[0], line[1]
yield movie_id, (0, movie_title)
else:
line = line[0].split('\t')
user_id, item_id, rating, _ = line
yield item_id, (1, user_id, rating)
def reducer(self, item_id, values):
movie_title = ''
final = []
for items in values:
if items[0] == 0:
movie_title = items[1]
else:
user_id, rating = items[1], items[2]
final.append([user_id, rating])
for data in final:
yield data[0], (item_id, movie_title, data[1])
if __name__ == '__main__':
MRdataMerge.run()
由于读取原数据集时会遇到编码错误(‘utf8’ codec can’t decode byte 0xe9 in position 3: invalid continuation byte),发现数据u.item中的第1005行有乱码,改正之后就正常了.
python mergedata.py u.data u.item > mergedata.txt

5. 使用mapreduce实现去重任务
#!/usr/bin/env python
#! coding=utf-8
from mrjob.job import MRJob
import re
class MRdedup(MRJob):
'''
实现去重
'''
def mapper(self, _, line):
line = line.strip().split(',')
yield line[0], (line[1], line[2])
def reducer(self, id, values):
exist_list = []
for value in values:
if value not in exist_list:
exist_list.append(value)
print id, (value[0], value[1])
if __name__ == '__main__':
MRdedup.run() #run()方法,开始执行MapReduce任务。
6. 使用mapreduce实现排序
#!/usr/bin/python
# -*- coding: utf-8 -*-
from mrjob.job import MRJob
class MRrank(MRJob):
'''
计算每个用户的平均评分
'''
def mapper(self, _, line):
user_id, score = line.split(',')
yield 'rank', (float(score), user_id)
def reducer(self, user_id, values):
# shuff and sort 之后
l = list(values)
l.sort()
for key in l:
print key[1], key[0]
if __name__ == '__main__':
MRrank.run() #run()方法,开始执行MapReduce任务。
7. 使用mapreduce实现倒排索引
#!/usr/bin/python
# -*- coding: utf-8 -*-
from mrjob.job import MRJob
class MRratingAvg(MRJob):
'''
计算每个用户的平均评分
'''
def mapper(self, _, line):
line = line.strip().split(',')
docum = line[0]
words = line[1].split()
for word in words:
yield word, docum
def reducer(self, word, docum):
#shuff and sort 之后
temp = []
for d in docum:
temp.append(d)
yield word, temp
if __name__ == '__main__':
MRratingAvg.run() #run()方法,开始执行MapReduce任务。
8. 使用mapreduce计算Jaccard相似度
#!/usr/bin/python
# -*- coding: utf-8 -*-
from mrjob.job import MRJob
class MRjaccard(MRJob):
def mapper(self, _, line):
line = line.strip().split()
user1, user2 = line[0], line[1]
item1, item2 = line[2], line[3]
yield 'simi', (user1, user2, item1, item2)
def reducer(self, key, lines):
#shuff and sort 之后
for line in lines:
users = line[:2]
items = line[2:]
unions = len(set(items[0]).union(set(items[1])))
intersections = len(set(items[0]).intersection(set(items[1])))
yield (users[0], users[1]), (intersections, unions, float(intersections)/unions)
if __name__ == '__main__':
MRjaccard.run()
9. 使用mapreduce实现PageRank
from mrjob.job import MRJob
from mrjob.protocol import JSONProtocol
from mrjob.step import MRStep
class MRPageRank(MRJob):
def mapper(self, _, line):
data = line.strip().split(',')
p = float(data[1])
target = data[2:]
n = len(target)
for i in target:
yield i, p/n
def reducer(self, id, p):
''' reducer of pagerank algorithm'''
alpha = 0.8
N = 4 # Size of the web pages
value = 0.0
for v in p:
value += float(v)
values = alpha * value + (1 - alpha) / N
yield id, values
if __name__ == '__main__':
MRPageRank.run()