Oracle 11g学习笔记--高级查询
Oracle 11g学习笔记–高级查询
说明:本文总结自《Oracle Database 11g SQL 开发指南》 Jason Price著
集合操作符
集合操作符可以将两个或者多个查询返回的行组合起来
| 操作符 | 说明 |
| union all | 返回各个查询检索出的所有行 |
| union | 返回各个检索查询出的所有行,不包括重复行 |
| intersect | 返回两个查询检索出的共有行 |
| minus | 返回将第二个查询检索出的行从第一个查询检索出的行中减去之后剩余的行 |
使用方法:
select ..... from table_1 union all select ....from table_2;
--必须保证具有相同的结果列translate函数
translate(x, from_string, to_string)函数在x中查找from_string中的字符,并将其转换成to_string中对应的字符。
select translate('ab123', 'abcdefg123', '3456789abc') from dual;鼠标放上来,查看结果
从结果可以看出,from_string和to_string中的字符是一一对应的,然后根据这种对应关系,将原字符串进行转换;
注意:两个字符串的长度可以不一致,若前者比后者长,那么后者会以空补齐,此处的空就是没有任何东西,若前者比后者短,那么后者多出的部分会自动忽略;
decode()函数
decode(value, search_value, result, default_value)对 value与search_value进行比较,若相等,则返回result,否则返回default_value.
select decode(1, 1, 3, 4) from dual;鼠标放上来,查看结果
case表达式
case表达式可在SQL语句中实现if-then-elsse型的逻辑,它的作用与decode类似,但是我们应该使用case,因为它与ANSI兼容,而且更容易读;
select
case ROWNUM-1
when 1 then 'A'
when 2 then 'B'
else [default] 'D'
end
from products;
--else后面是默认值鼠标放上来,查看结果
层次化查询
有下图这样一张表,它记录的是员工的一些信息,m_id该员工的上级的id,例如James就是Ron的上级;

那么我们如何找出他们的层级关系。
oracle为我们提供的Select语句的Connect by和start with子句可以执行层次查询;
语法如下:
select [level], column, expression, ...
form table
[where where_caluase]
[start with start_condtion connect by prior prior_condition]
--level 是一个伪列,代表了第几层,对于本表的CEO,自然是第一层
--start_condtion 定了层次化查询的起点,当编写层次化查询时必须指定start with子句;
--prior_condition 定义了父行和子行之间的关系,当编写层次化查询时必须定义connect by prior子句实例:
--employee_id 就是表中的id
--manager_id 就是表中的m_id
select level, employee_id, manager_id, first_name, last_name
from more_employees
start with employee_id =1
connect by prior employee_id = manager_id
order by level;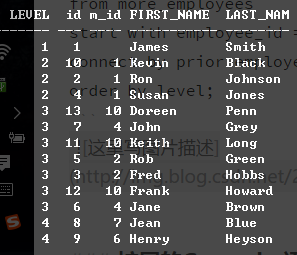
那么如果我们要查Susan的员工有哪些,该怎么查询?
select first_name || ' ' || last_name as employee
from more_employees
start with first_name = 'Susan'
connect by prior employee_id = manager_id;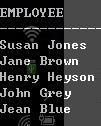
扩展的Group by语句
rollup子句扩展了group子句,为每一个分组返回一天小计记录,并未全部分组记录返回总计;
select division_id, job_id, sum(salary)
from employees2
group by rollup(division_id, job_id)
order by division_id, job_id;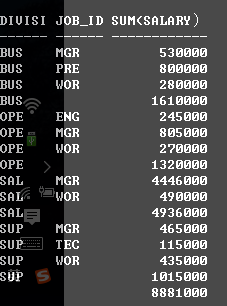
select division_id, job_id, count(salary)
from employees2
group by rollup(division_id, job_id)
order by division_id, job_id;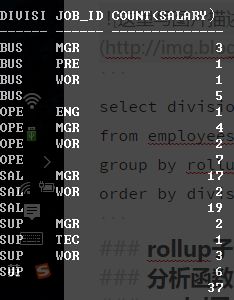
从以上的案例可以看出来,rollup的作用就是将第一次分组结果小计+总计,第二次分组只是对第一次分组的再次分组显示。
补充:其实rollup可以和任何聚合函数一起使用;
rollup子句
使用cube子句
cube是对group by的扩展,返回cube中所有列组合的小计信息,同时在最后显示统计信息;
select division_id, job_id, sum(salary)
from employees2
group by cube(division_id, job_id)
order by division_id, job_id;
从结果可以看出他和rollup的唯一区别就是在后面加上了其他小组的小计信息;
grouping函数
grouping函数可以接受一列,返回0或者1。如果列值为空,那么grouping()返回1,如果非空,返回0;该函数只能在rollup和cube的查询中使用,当需要在返回控制的地方显示某个值得时候,grouping 函数就会非常有用;
select grouping(division_id), division_id, job_id, sum(salary)
from employees2
group by cube(division_id, job_id)
order by division_id, job_id;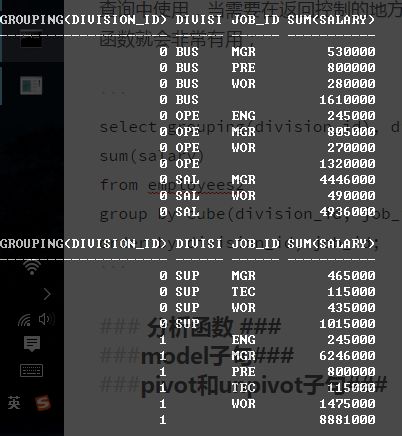
由于在最后几条记录中,division_id为空,所一显示的是1;
那么有什么用处呢?在此处我们就需要引入前面讲到的case-when-then了;
select
case grouping(division_id)
when 0 then division_id
when 1 then 'all_divisions'
end
,case grouping(job_id)
when 0 then job_id
when 1 then 'all_jobs'
end
,sum(salary)
from employees2
group by cube(division_id, job_id)
order by division_id, job_id;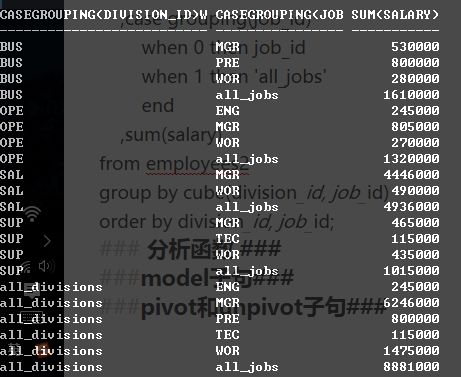
grouping sets
该子句知识返回小计,比cube少了最后的总计,但是他的性能一般比cube好,所以我们应该尽可能的使用grouping sets, 少使用cube;
select division_id, job_id, sum(salary)
from employees2
group by grouping sets(division_id, job_id)
order by division_id, job_id;
grouping_id
该函数可以传入一列,或者多列,返回grouping为对应的十进制值。例如,对于grouping_id(division_id, job_id), 若grouping(division_id)返回1,grouping(job_id)返回0;那么grouping_id(division_id, job_id)的值就是(10)(二进制)这样返回的就是2;
select division_id div, job_id job, grouping(division_id) divi_id, grouping(job_id) job_id, grouping_id(division_id, job_id) divi_job_id, sum(salary)
from employees2
group by rollup(division_id, job_id)
order by division_id, job_id;
group_id
group_id函数可以消除group by子句返回的重复记录。如果某一个特定的分组重复出现了n次,那么group_id返回0到n-1之间的一个整数。
如查询
select division_id div, job_id job, sum(salary)
from employees2
group by division_id, cube(division_id, job_id)
order by division_id, job_id;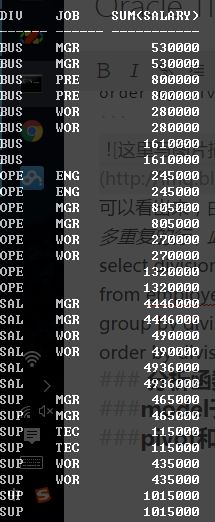
可以看出来,由于group by后面加了一个division_id,所以出现了许多重复的行,此时,就可以利用group_id来操作了。
select division_id div, job_id job, sum(salary), group_id()
from employees2
group by division_id, cube(division_id, job_id)
order by division_id, job_id;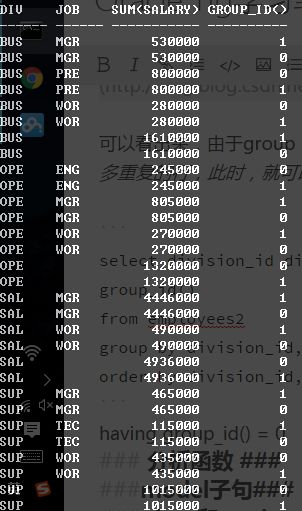
这样我们就可以在group后面加上分组显示条件
having group_id() = 0,即可过滤多余的项了;
==================华丽的分割线==================
我想说这一章,可真够多的,所以我决定将剩下来的部分各自写成一篇,而且我感觉他们都足可以独成一篇。
分析函数
http://blog.csdn.net/e_xiake/article/details/52824584
model子句
http://blog.csdn.net/e_xiake/article/details/52832307
pivot和unpivot
http://blog.csdn.net/e_xiake/article/details/52840696