【WINDOWS10 + VS2015】在MFC、Qt、WIN32项目中利用CUDA编程
引言
图像处理算法、矩阵或者向量数学运算的编程实现过程中,经常涉及许多“块运算”。这种运算在程序中表现为循环或者多次嵌套的循环操作,很适合用cuda进行gpu编程加速。刚步入研究生时期,我学习了一些cuda编程的皮毛,但是后来进行图像处理任务时并没有用上,导致现在连皮毛也渐渐忘记了。随着面对的任务越来越复杂,对实时性要求越来越高,渐渐认识到cuda是一根救命稻草——算法的时间复杂度很难降低一个数量级,但是利用gpu和多线程对算法进行并行加速可以大大减少运算时间。opencv开源库已经用cuda实现了大量的算法(这正是提醒我们要重视cuda),但是只针对opencv的一些模块和算法。有必要重新学习cuda编程,并在今后图像处理任务的编程使用中积累cuda编程的经验。
安装CUDA
如何安装呢? 我的PC上很早装的,所以不提供这部分内容(-.-)。请戳下面链接(随便找的,应该可以装好。)单击此处
本文的内容
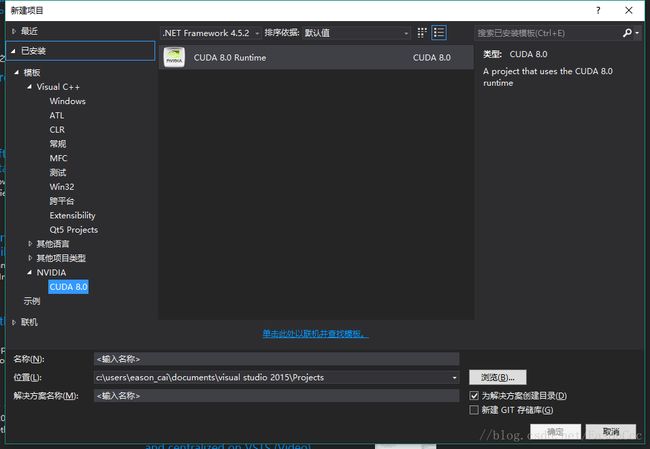
cuda的配置很多地方有教程了,这篇博客主要记录如何在VS下配置和使用cuda。作为记录以防再需,同时希望给需要的人带来帮助。首先,你的电脑应该要有支持cuda的显卡。其次,先进行一下配置,需要确保以及安装好VS, 下载并且配置好cuda,设置好了cuda的环境变量(一般默认添加)。如何检验呢,你的VS能否向下面这样新建CUDA程序?
如果可以的话:
1. 新建一个MFC程序(WIN32程序、控制台程序、QT),或者打开现有的MFC程序,无所谓基于Dialog或者视图。
2. 配置项目属性
(1)
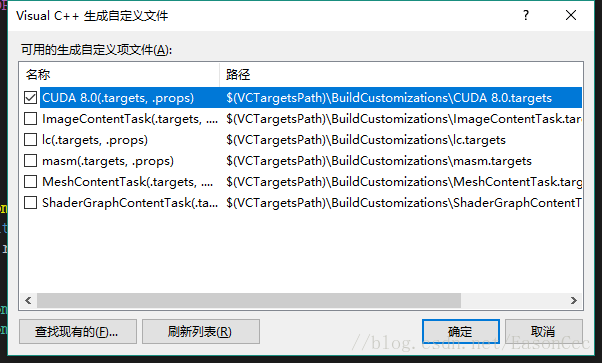
解决方案资源管理器->右键项目名称->生成依赖项->生产自定义(英文版VS请自行对照翻译)
(2)
勾选cuda项->确定
(3)
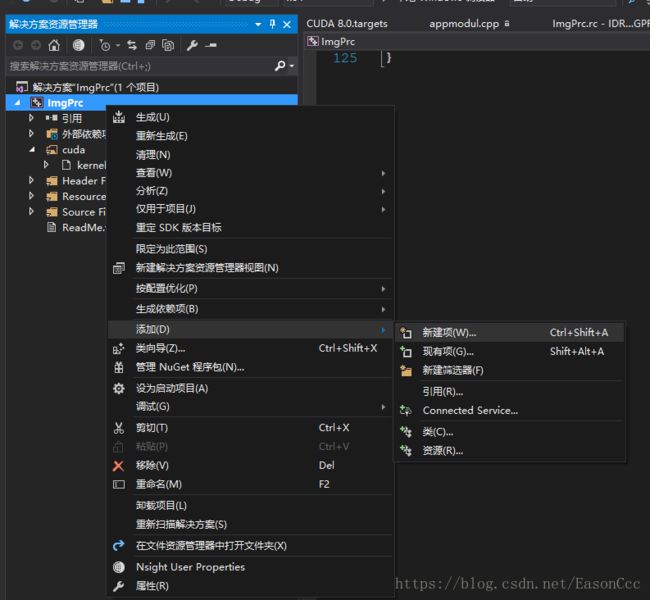
解决方案资源管理器->右键项目名称->添加->添加新建项->选择.cu文件. (如果没有cu文件的选项,选择.cpp源文件,自己手动把拓展名改成.cu即可.)

(4)
右键添加的.cu文件->属性->勾选项类型为 CUDA C/C++.

(5)
右键项目->属性->链接器->常规->附加库目录->添加目录 $(CUDA_PATH_V5_5)\lib\$(Platform) . 在VS中查看有没有这个宏,如果没有,一般对应的这个路径: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\lib\x64 (取决于cuda的安装路径)。
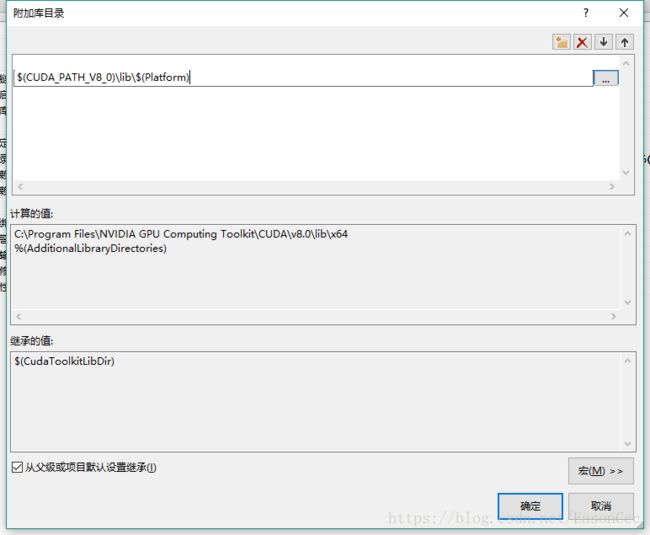
(6)
链接器->输入->附加依赖项中添加cudart.lib
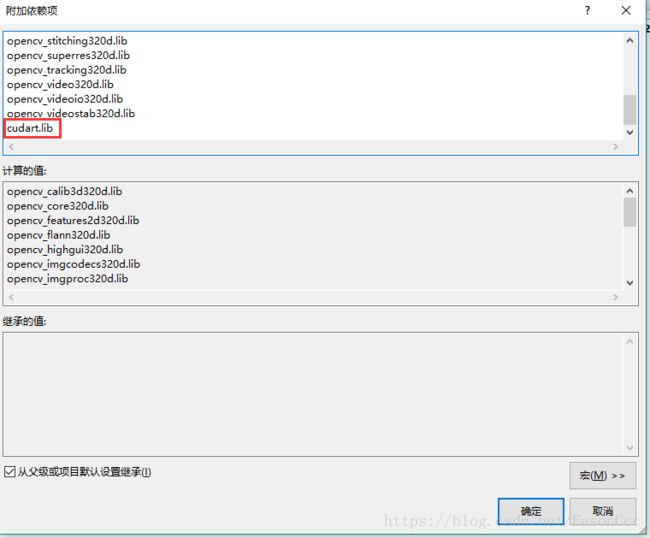
当然,这只是runtime的静态库,你可以添加你可能用到的其他静态库到附加依赖项。
3. 完成项目属性配置后就可以编写cuda程序了。但是有一点要注意,你项目的.cpp文件不能直接#include “xx.cu”或#include “xx.cuh”,需要通过借助extern关键字引入外部函数的方式调用。并且,由于在.cu文件中编写的用来调用的host函数需要通过extern “C”指定C编译器。
1. 在.cu文件中
#include #include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include 例子
按照上面所述的方式,便可以在VS的其他工程中使用cuda编程了。贴上一个例子,如果你的工程配有opencv的话可以用这个例子试一试。
1 kernel.cu (也许你创建的.cu文件叫其他名字)
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include >> (dev_img, w, h, 3);
cv::Mat img(1000, 1000, CV_8UC3);
HANDLE_ERROR(cudaMemcpy(img.data, dev_img, 1000*1000*3, cudaMemcpyDeviceToHost));
cv::imshow("See", img);
HANDLE_ERROR(cudaFree(dev_img));
}
2 ImgPrcView.cpp (你调用这个函数的文件)
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
extern "C"
{
void DrawCircles();
}
...
//无关代码
...
void CImgPrcView::OnTest()
{
DrawCircles();
}
3 程序运行结果

Bonus
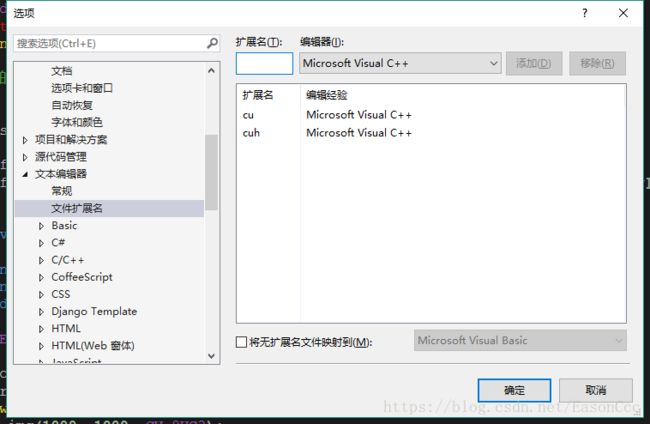
你可以在 工具->选项->文本编辑器->文件扩展名中添加.cu和.cuh文件使用Microsoft Visual C++编辑,以获得VS的一些代码提示帮助。