Hadoop作业性能指标及参数调优实例 (一)Hadoop作业性能异常指标
作者:Shu, Alison
Hadoop作业性能调优的两种场景:
一、用户观察到作业性能差,主动寻求帮助。
(一)eBayEagle作业性能分析器
1. Hadoop作业性能异常指标
2. Hadoop作业性能调优7个建议
(二)其它参数调优方法
二、Hadoop集群报告异常,发现个别作业导致集群事故。
一、用户观察到作业性能差,主动寻求帮助。
(一)eBay Eagle作业性能分析器
对一般作业性能调优,eBay Eagle[i]的作业性能分析器已经能满足用户大部分需求。eBayEagle作业性能分析包含两个部分,第一部分是根据定量指标,捕捉性能异常的作业。在本文中,我们不考虑Hadoop集群或者节点故障造成作业性能的普遍下降,因此我们认为这些性能指标异常只与Hadoop作业有关,可以通过性能调优来改善。第二部分是调优建议。根据Hadoop作业性能异常指标判断作业是否需要调优,再综合采用第二部分的建议。第二部分也可以作为Hadoop作业开发的指引,并在后期性能测试中检查。
1. Hadoop作业性能异常指标有7个,以2015年5月的数据看,发生比例如下:
| 指标 |
% |
| 作业进展缓慢 |
32% |
| Reduce数量太多 |
24% |
| Bytes Consumed Per CPU Second太低 |
23% |
| 和历史记录比较,作业用时太久 |
15% |
| 作业用时太久 |
3% |
| Shuffle size太大 |
2% |
| Read/Write Ops太大 |
0% |
| 总计 |
100% |
§ 作业进展缓慢
HDFS的读写或者File的读写没有任何进展,并且持续相当一段时间。设15分钟为标杆,则当Hadoop作业没有任何读写操作持续达到15分钟,认为作业性能异常。如果作业普遍进展缓慢,可能是系统负载过高或否存在坏节点,这种情况是集群问题,与个别作业无关,但是用户可以通过选择合适的时间窗口或者queue来避免系统资源紧张导致作业性能下降。在Hadoop 2中,yarn通过scheduler管理大型集群多用户之间的资源分享。有两种scheduler:Fair Scheduler和Capacity Scheduler。作业对应的queue如果负载过高,则相应queue里的作业因为等待资源而进展缓慢。eBay Hadoop集群使用Capacity Scheduler,不同的queue拥有不同的资源,同一个作业如果有多个queue可以选择,建议作业使用相对空闲的queue,或者在相对空闲的时间窗口运行。
§ Reduce数量太多
这个指标需要设定合适的标杆,eBay Ealge认为Reduce 数量大于1500,作业性能会变差。初衷是通过控制Reduce 数量减少Seek operation 数量。在实践中,我们发现有些特殊的作业,Map output非常大,减少Seek operation 带来的收益小于Reduce 数据溢出到磁盘导致的额外成本。对这种作业,Reduce 数量超过1500是合理的。
示例:job_1401947195699_0367 Map number=9300, Reducenumber=4500
Job Counter截图

计算控制Reduce 数量的综合损益:
-减少Seek operation 带来的收益:
Reduce 数量从4500降低到1500,目的是减少Seek operation number。简化计算,忽略Shuffle handler使用read ahead来cache data。Reduce 数量减少3000会节省75小时。
reduced # of Seeks:(4500 – 1500) * 9000 (maps) =27000000.
假设IOPS=100, max. reduced time: 27000000 / 100 / 3600(seconds) = 75 hours.
-增加每个Reduce data导致的成本:
已知每个Reduce memory=3GB,ShuffleBytes=19TB
19(TB)/1500*1024(GB)=13(GB)
数据溢出到磁盘:13(GB)-3(GB)=10(GB)
假设磁盘平均读写速度=100MB/s
10(GB) * 2(write + read) * 1500 / 100(MB/s) /3600(seconds) = 85 hours.
-减少Reduce 数量的净收益:
75(hour) -85(hour)=-10(hour)
§ BytesConsumed per CPU second太低
这个指标也要和标杆比较,设BytesConsumed per CPU second低于200KB,认为作业性能较差,需要调优。用户也可以从job counter计算这个指标。
Bytes Consumed = File Bytes Read + File BytesWritten + HDFS Bytes Read + HDFS Bytes Written
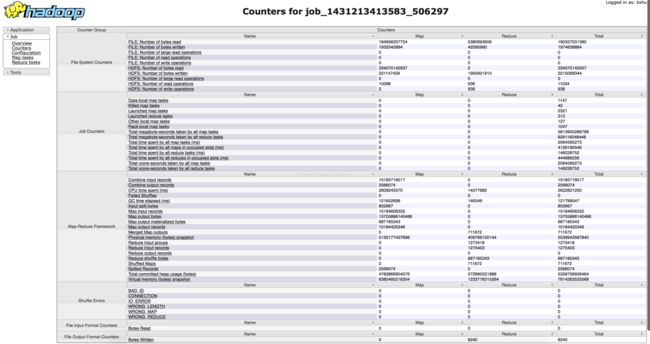
示例:job_1431213413583_506297
Bytes consumed per CPU second=194.65 KB
Job Counter截图:
§ 和历史记录比较,作业用时太久
有很多统计算法可以发现作业用时过长。eBay Eagle使用如下算法:
· 采集最少100个历史用时,每个用时作为一个数据点
· 去除10%最长用时数据点,计算中位数p90
· 计算绝对离差的中位数MAD
· 计算离差倍增数的95分位数dmMax
· 如果作业用时的离差倍增数大于dmMax,且大于p90,则认为作业用时太久,需要用户注意作业性能。如果普遍发生,则可以是集群问题,和个别作业无关。
很多Hadoop作业每天运行一次或者一天运行多次,适合统计历史用时。但根据Hadoop 平台架构,每次MapReduce作业都会获得新的Job Id,因此需要作业命名正则化来唯一确定作业。eBay Eagle创建了属性 ebay.job.name=
Hadoop作业命名正则化示例(命令行方式):
/bin/hadoop jar
§ 作业耗时太久,超过标杆
设12小时为标杆,如果Hadoop作业耗时超过12小时,即认为作业性能差 。
用户很容易通过JobTrackerweb URL或是Hadoop API观察这个指标。
§ ShuffleSize太大
标杆设为单个Reduce对应的Shuffle size上限为10GB,超过这个数值,作业需要调优。
示例:job_1431213413583_517459
Reduce number=1 Reduce Shuffle Bytes=10709428036
Job Counter截图:

§ Read/WriteOps太大
标杆设为HDFS Read or Write Ops上限为10MB,超过这个数值,作业需要调优。
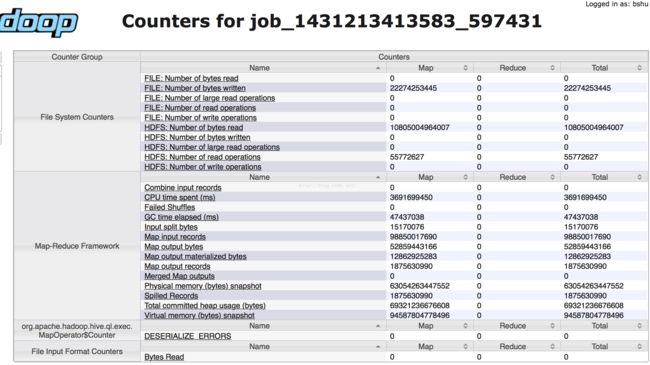
示例:job_1431213413583_597431 HDFS_READ_OPS=55.77M
Job Counter截图:
[1] eBay Eagle是eBay自主研发的系统,用于大型Hadoop集群管理,集监控、警示和智能修复功能于一体。eBayEagle即将开源,有望成为Apache的孵化项目。