ZCA
CNN数值——ZCA
在Caffe的网络描述中,data layer的配置中有一项是用于配置mean_file,也就是数据的平均数值,在计算中每个数据在进入网络计算前会减去mean_file,以确保数据的整体均值为0,这样对于训练数据会更有帮助。
那么除了减去均值之外,还有什么初始化的方法呢?ZCA就是其中比较经典的初始化算法之一。
Zero Component Analysis
我们用一个例子来讲述这个初始化算法的过程。首先我们利用随机算法生成一个数据集。为了节目效果我们的数据集只有2维,而且两个维度之间还有相关关系。生成数据的代码如下所示:
x = np.random.randn(200)
y = x * 2
err = np.random.rand(200) * 2
y += err
data = np.vstack((x,y))
plt.scatter(data[0,:], data[1,:])
上面的数据绘图的结果如下所示:
 我们可以求出两个特征的均值,再让全体数据减去均值,使得整体数据的均值为0:
我们可以求出两个特征的均值,再让全体数据减去均值,使得整体数据的均值为0:
mean = np.mean(data, axis=1)
data -= mean.reshape((mean.shape[0],1))
plt.scatter(data[0,:], data[1,:])
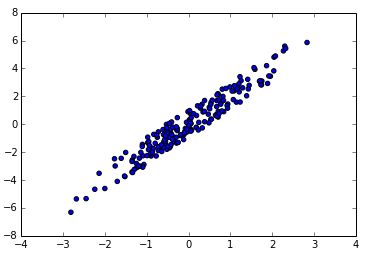 下面才是ZCA的关键部分。我们都知道训练数据中有时会出现特征之间相互关联的问题,对于图像数据,相互关联的问题则更为严重。虽然卷积层可以通过学习来解决这些局部相关性,但是通过学习来得到总是不够直接,如果直接对输入数据进行操作来解决一些数据相关性问题,一定会让训练更容易些。
下面才是ZCA的关键部分。我们都知道训练数据中有时会出现特征之间相互关联的问题,对于图像数据,相互关联的问题则更为严重。虽然卷积层可以通过学习来解决这些局部相关性,但是通过学习来得到总是不够直接,如果直接对输入数据进行操作来解决一些数据相关性问题,一定会让训练更容易些。
为了解决数据相关问题,我们希望不同特征之间的协方差能够控制在一定范围内,我们首先来计算一下上面数据的协方差,由于我们的数据已经减去了均值,那么现在数据的均值为0,计算协方差就简化成了如下的计算:
conv = np.dot(data, data.T) / (data.shape[1] - 1)
print conv
[[ 0.88200859 1.80316947]
[ 1.80316947 4.033871 ]]
让每个特征自身的方差变为1,让特征之间的协方差变为0。
为了达到这个效果,我们可以给每个输入数据做一次线性变换,使最终的结果满足我们所设定的效果。那么就有:
# 如果有数据矩阵x,那么我们要寻找一个线性变换矩阵W,满足
Y = np.dot(W, X)
# 且
np.dot(Y, Y.T) / (Y.shape[1] - 1) == np.eye(Y.shape[0])
为了达到这个目标,我们首先做如下的假设
线性变换矩阵W是一个对称矩阵:
我们的目标是令
于是有:
,同时去掉左右两式右边的,有
,
由于是一个对称矩阵,对称矩阵具有一个特性。我们先求出的特征值和特征向量:
对称矩阵具有一个特性,它的特征向量可以构成一个标准正交矩阵,根据标准正交矩阵的特性,于是我们可以得到:
(关于这个定理,我们可以等后续进行证明,在此先直接使用)继续推导,可以得到:
(这里其实也稍有跳跃,再后续证明)于是最终的
实际上上面的推导还缺少一些细节,比如对称矩阵相关的一些性质,对于这一部分的详细无脑推导我们之后可以再详细叙述。以下是根据定义对应的代码:
# 由于conv中已经除掉了1/(Y.shape[1] - 1),所以后面的计算中我们将不再去除它
eig_val, eig_vec = np.linalg.eig(conv)
S_sqrt = np.sqrt(np.diag(eig_val))
W = np.dot(eig_vec, np.dot(np.linalg.inv(S_sqrt), eig_vec.T))
print W
结果得到
[[ 3.37642486 -1.32714676]
[-1.32714676 1.05662959]]
现在我们得到了W,就可以进行线性变换,可以得到:
Y = np.dot(W, data)
plt.scatter(Y[0,:], Y[1,:])
conv2 = np.dot(Y, Y.T) / (data.shape[1] - 1)
print conv2
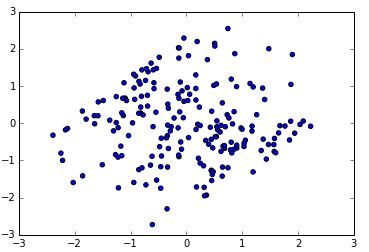
此时对应的协方差为
[[ 1.00000000e+00 -1.29433036e-16]
[ -1.29433036e-16 1.00000000e+00]]
无论从图像结果还是协方差的数值结果上看,ZCA都完成了我们想要的目标。以上的ZCA算法推导来自论文《Learning Multiple Layers of Features from Tiny Images》的附录。
ZCA初始化在一些经典的数据集(比方说cifar10)已经得到验证,采用这样的初始化可以得到更好地训练精度。不妨动手一试吧!