Week3 结对编程总结-词频统计
这篇总结是关于上周的结对编程作业(词频统计)的一个总结。文中会大致介绍我们组的任务、分工方式、实现的细节,过程中遇到的问题及解决方法,和自己和收获与感悟。
代码仓库:https://dev.azure.com/v-zhilin/_git/TextStat
可执行程序(windows .exe 文件)
任务简介
这次作业是基于实现一个对文本文件做词频统计的功能,对于一个目录下的所有文件分别进行字母、单词、词组以及动词短语(根据给出的动词和介词集合做出判断)的出现频率统计、排序,并且要求支持在结果中过滤用户自定义的停止词(stop words)。
由于不限制编程语言,要完成这个功能并不算一件很难的事情,我觉得这次作业的重点在于效能分析,最终的评判标准中重要的一项就是运行速度。 要提升运行速度可以从很多方面考虑:编程语言的选择、框架设计、具体实现的细节等。另外,为了帮助分析和提高运行速度,学习使用效能分析工具我想也是这次作业的目的之一。
分工合作
这次的结对编程由于换了队友,结对编程方式也发生了变化,我觉得能体验不同的结对编程模式是很有意思的。这次队友超厉害,所以如果一定要说是领航员-驾驶员模式的话,我大概是个实习驾驶员。我们把代码仓库放在 AzureDevOps 上, 将具体的四个功能分到每个人完成两个(我负责单词和动词短语,队友负责字母和词组),在最终完成之前,我们的项目除了 master 之外还有四个 branch 分别对应四个功能由我们两个各自维护。主分支定义了基础的程序并行流水线框架,除了基础的公用的函数(如处理命令行参数、读文件)之外没有其他具体功能。
由于这次作业的重心在提高效能,而我队友碰巧又是“多线程小能手”,所以在我们第一次讨论之前,他就构思好了整个程序的框架:一共三个线程分别负责读数据、数据处理和结果统计,用“生产者-消费者”模式控制多线程。编程语言我们选择的是 C++, 很遗憾这是一个我不太熟悉的语言,但是我高兴能通过这次作业写一点 C++ 代码。
除了第一次讨论在讨论室面对面meeting之外,后面的整个过程比较独立,遇到问题再讨论,或者用 Skype 共享桌面 debug。如果对主分支有重要的更新会通知对方,自己看一下相应的 commit 大概就知道是怎么回事了。
框架设计
项目框架设计
前面说到框架是队友提出的,我觉得他对问题的分析非常有道理,线程的设计很合理。引用他的话:
框架的总体流程是我提出的,决定采用并行流水线的原因也是因为这个程序的逻辑存在着明显的分离、并行空间
代码框架设计
我们的源码框架遵循 C++ 开源工程项目规范(包括 src, include 等文件路径)。
建立一个 TextStat 基类, 在其中提供所有功能都会用到的方法和数据存储类型。
其他功能模式继承基类,并定义对应功能的新方法,或者重载原有的方法,以实现相应的功能。
代码风格
Google Code Style
这是一个非常详细的 Docs,几乎所有的细节在上面都有参考,所以我们是通过这个达成一致的。
优化
数据结构
在数据结构方面,我们使用 std::unordered_map 和 std::unordered_set 存储字典和词表。这种数据结构通过哈希值和哈希函数快速查找元素,这是能帮助效能的一种方法。
程序框架
我们基于并行流水线框架,三个线程分别负责一个模块的功能:读取文件(I/O), 文本分析(计算),统计(访存),这三个线程相互依赖。例如计算模块需要IO模块的输出作为输入,并且它的输出再作为统计模块的输入。所以这样每两个线程之间可以采用 生产者-消费者 模型控制。
算法的选择
根据作业要求,我们最终需要的结果,是对于一个无序的集合进行排序:可能是全排序,也可能是只要知道最大的前 n 个元素。对于后面那种情况,我们最开始的想法就是简单直接的,不管怎样,先做全排序再说,如果要前 n 个就取前 n 个输出就行了。但是后来想到,部分排序可以使用 std::partial_sort,这种方法会比全排序更快。
进一步的优化
对生产者-消费者模型的优化,主要是针对互斥信号的优化,每个线程持有锁的时间越短,并发程度就越大。一个重要的优化就是控制一个线程持有信号量的的时间,把所有的计算任务放到临界区的外面,内部只负责读数据和放数据。
另外,为了提高并发程度,对每个线程的任务的划分也应该更明确,将 I/O 密集型任务和计算密集型任务分得清楚一些。刚开始我们在读取文件的线程中也对读入的内容做了初步的处理,例如判断是否为完整单词,是否是数字或字母等,但是这样 IO 线程就会更慢了(本身 IO 就容易成为程序运行的瓶颈)。所以我们将所有的文本处理全部放在第二个线程(文本分析)中,这样做的运行速度可以比原来提升 25%。
还可以尝试的优化
事实上这个程序还有很多可以优化的地方,从程序框架设计来说,可以设计更加细粒度的并行:使用更多的线程,维护一个优先对列表,这样可以不需要等全部统计完成后再进行排序;也可以使用 OpenMP 多线程库,做到分词、排序的并行。
但是由于时间分配的问题,我们没有在这次作业中进一步的从这方面做优化。
Pair Work
关于我的队友:
三个优点:
- 经验丰富(尤其是多线程编程)。
- 代码框架设计很规范很专业。
- 执行力高,每次都能很快的把当前阶段要做的事情完成。
缺点:
- 程序的测试不够细致,一开始他的branch里我有找到一些奇怪的 bug。
效能分析
我们采用的效能分析工具是 Visual Studio Performance Profiler
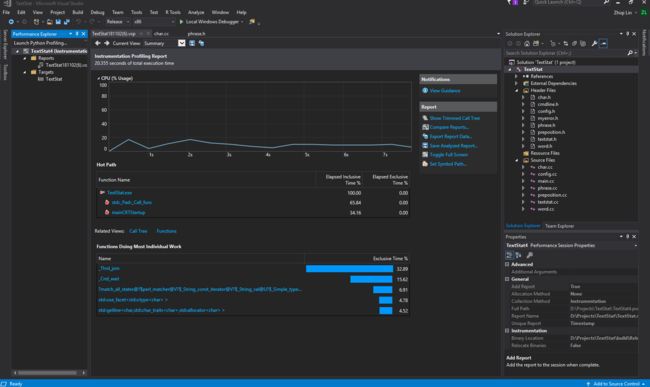
我们主要统计的是热点函数,针对热点函数来优化运行时间。

下图是我们获得各个函数的执行情况表(in -p mode),从墙上函数内运行时间(Elapsed Exclusive Time)来看,第一个热点函数是正则匹配中使用到的,说明正则匹配在整个过程中占较大开销。注意到第三大开销,std::getline(),来自于文件读取(I/O)。
实际上,更加适合我们的程序做效能分析的是 Concurrency 模块,它可以看到哥哥线程的负载情况,帮助进一步做到线程间的负载均衡。但是因为权限问题,这个模块无法使用,没能进一步的效能分析。
心得
这次的结对编程,我感觉收获很大,虽然在这个作业中我并没有起主导作用,但是我接触到了很多新东西:规范的代码框架、多线程编程、效能分析等等。还有一个非常重要的收获就是熟悉了 git 的使用和版本管理的方法,切实感受到了这个工具的强大之处,在结对编程和团队合作中都带来的很大的便利。现在我也开始用 Azure 管理同步一些自己的实验代码。