VALSE 2017 | 神经网络模型压缩优化方法
本文 首发在个人微信公众号:计算机视觉life上。
近年来,深度神经网络在计算机视觉、语音识别等领域取得了巨大成功。为了完成更加复杂的信息处理任务,深度神经网络变得越来越深,也使得其计算量越来越大。然而,手机、车载等移动端应用对深度神经网络的需求越来越多,因而深度神经网络模型的压缩、加速、优化变的越来越重要。这也是本届VALSE的热点之一。
深度学习算法是计算密集型和存储密集型的,这使得它难以被部署到资源有限的嵌入式系统上。优化一般有以下两个方向:
1、通过减少参数数量,达到模型压缩的目的。而压缩基于一个很重要的理论,即神经网络模型通常是过参数化的,也就是说,我们通常不需要那么多参数 就可以表达出模型特征。
2、通过节省计算,降低计算量,达到模型运算加速的目的。
今年的VALSE大会上,关于神经网络模型的压缩、加速、优化主要有如下几个报告:
1、原微软亚洲研究院首席研究员、旷世科技研究院院长孙剑,介绍了旷视科技在网络模型加速和压缩方面的工作。
2、中科院自动化研究所模式识别国家重点实验室研究员、人工智能与先进计算联合实验室主任程健,作了“深度神经网络快速计算方法”的tutorial。
3、新加坡国立大学教授、360人工智能研究院院长颜水成教授作了“深度学习的三个维度:Compactness,Speed, and Accuracy”的特邀报告。
下面通过几个讲者的PPT来介绍一下这方面的进展。
孙剑:简化网络设计方法
旷世科技研究院院长孙剑的报告中介绍了模型压缩优化。他举了个例子,比如在对图像分类的时候,随着层级的增加,应该把图像的空间分辨率慢慢缩小,但这同时也需要增加每一层中的filter 数。另外实践中发现用小的filter 是更经济的,还有用Low-rank分解逼近的方法也比较有效。

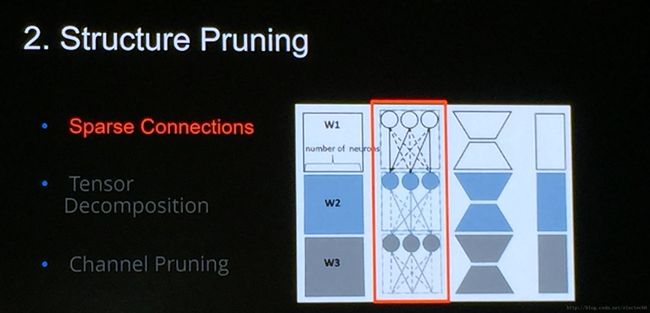
在简化网络方面,主要考虑结构剪枝。还有一个概念是结构化剪枝。虽然仅有一字之差,但是结构剪枝和结构化剪枝是两个不同的概念。结构剪枝是指对网络结构进行修剪,而结构化剪枝是属于结构剪枝的一种具体方法,指按照特定的结构(相对于随机)进行剪枝。结构剪枝如下图所示一共有3种方法。
- 第一种方法是稀疏连接,本来一个网络里有很多连接的,其基本思想是去除不重要的连接,让这个连接变稀疏。虽然它可以减少网络的模型大小,但是不一定能够减少网络的运行时间。
- 第二种就是张量分解的方法,就是把一个卷积网络参数矩阵通过张量分解,用它的低秩特性做逼近。
- 第三种是channel 剪枝,就是训练好一个网络后,简单粗暴的把一些channel 去掉。

还有一种方法就是Low-bit表达。如下图输入一个三维的feature map,feature map标准的话都是float表示的,卷积核其实也是一个三维的矩阵,它也是float表示的。Low-bit表达就是用低精度的表达来代替这些高精度的float,比如用8位或者更加极端的两位来表示。
有两篇比较著名的工作。一个是Binary connect,他的思想是把这个weight都变成01,这也是很夸张的一个想法。下面是更进一步的工作,它是将feature和weight全变成01,叫XNOR-Net,好处是卷积神经网络里的矩阵层,可以变成一个bitcount的指令,就可以完成它想要完成的计算,这个是在硬件中很有效的一个方法,也是Low-bit网络非常吸引人的地方。优点在于:1.内存可以降得非常多;2.潜在的加速比非常大。

Low-bit表达除了能量化weight或feature,还可以量化gridient,因为gridient其实也是float的。他们团队使用的设置是weight用01表示,activation用两位表示,gridient用4位表示,他们将这个网络取名为DOReFa-Net。该网络结构在并行训练或者FPGA/ASIC上训练时可以提高不少效率。

程健:深度神经网络优化计算
程健研究员的报告主要针对嵌入式平台的深度学习优化方法。他列举了近年来在深度神经网络模型加速和压缩方面的几个有效方法:
1、剪枝与稀疏
研究表明网络中很多连接都是接近0或者冗余的,如何对这些参数进行稀疏就变的很有意义。如下图所示是SVD分解的算法性能对比。SVD分解可以从模型压缩和提高运算速度两个方面进行优化。

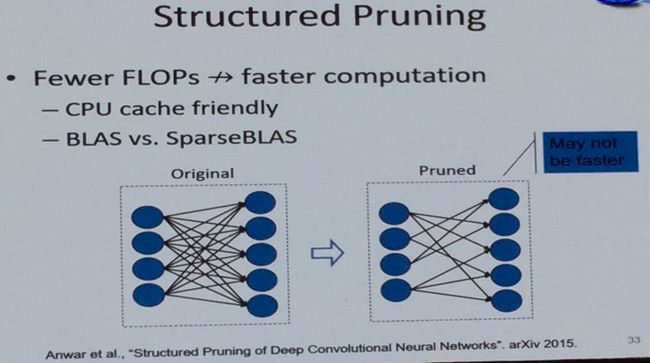
但是并不是只要剪枝就一定会提高运算速度。原因是如果剪枝过于随机,并不能有效提升运算速度。所以需要结构化剪枝(structured pruning)。
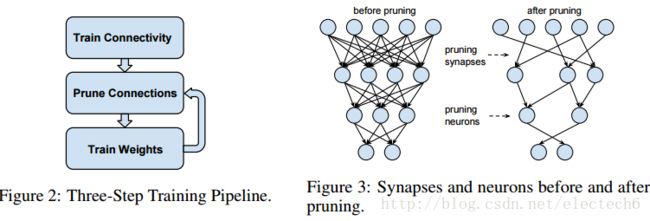
剪枝一般需要如下图左的三个步骤:先在原始的网络结构下训练网络,然后通过设置一个阈值,把一些权值较小的连接进行剪枝,重新训练权重,对训练好的模型再剪枝,再重新训练,直到满足设定条件为止。
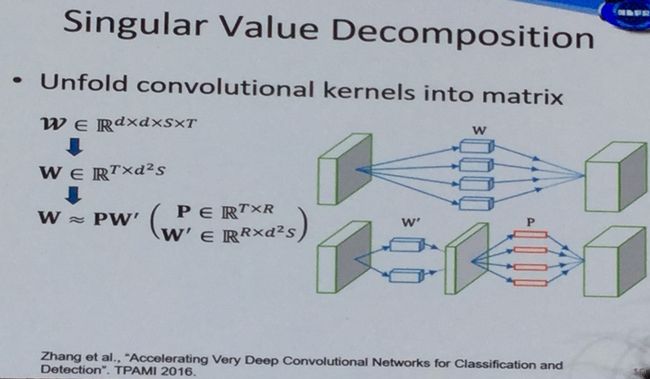
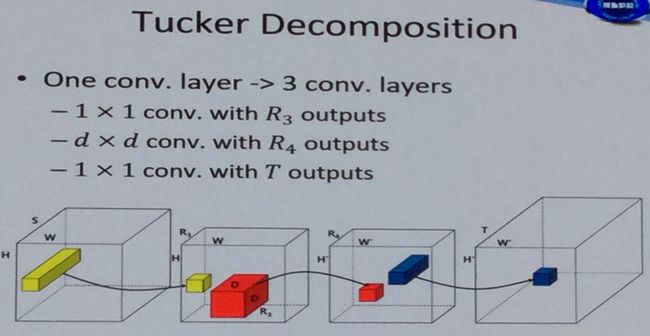
2、低秩分解
有很多种分解方法,比如奇异值分解、tucker分解、块分解。

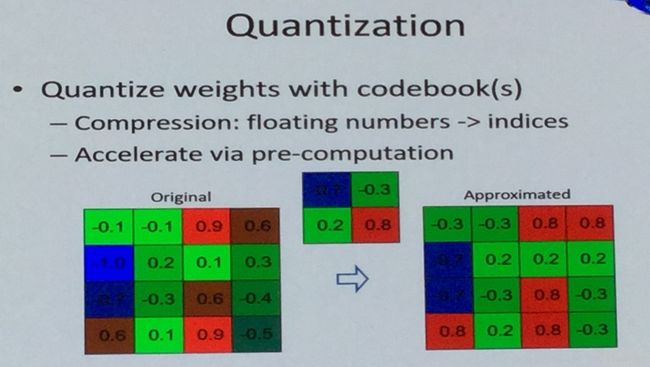
3、权值量化
通常神经网络中的权值一般用单精度的浮点数表示,需要占用大量的存储空间。而用码书对权值进行量化可以共享权值,从而减轻存储负担。
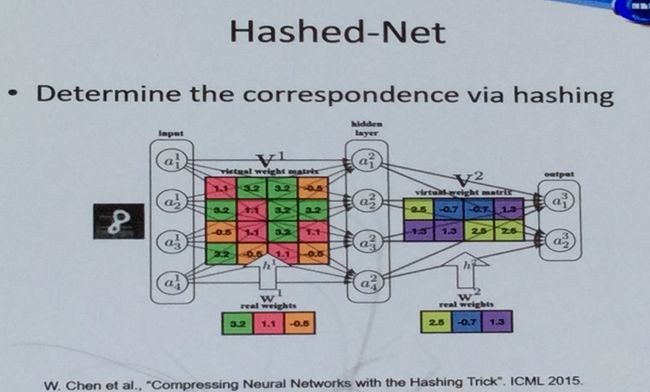
利用哈希编码对权重进行编码,从而达到压缩权重的目的。也是一种有效的方法,如下所示。
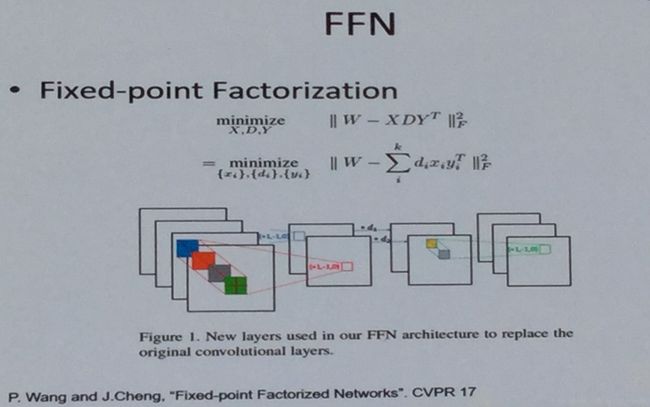
另外就是定点和二值化(fixed point / binary)的方法。量化方式有二值量化(0,1):

也有三值量化:

4、用定点来代替浮点数计算。
颜水成:深度学习的三个维度
新加坡国立大学颜水成教授介绍了深度学习的三个维度:Compactness, Speed, and Accuracy。也就是小模型、速度快、预测准。
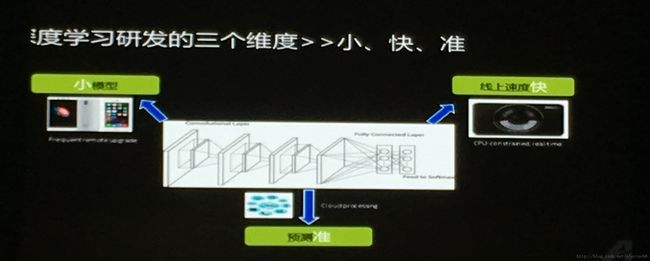
小模型可以考虑network in network。如下所示。

极端化一点,是否可以考虑设计全部由1x1的卷积层组成小模型?如下图所示就是使用1x1的卷积,它的基本结构包括以下三个部分:

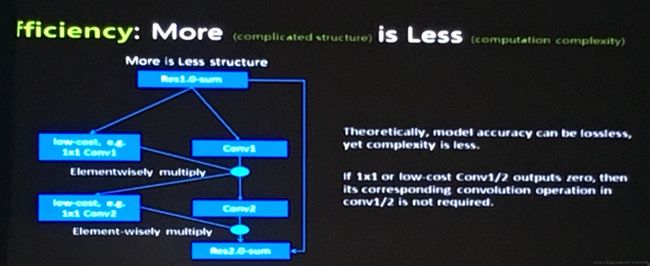
经过研究统计发现,网络在经过ReLU后,有平均超过40%的输出都是0,这些其实是无用信息,而且这些输出0值在经过ReLU前的操作也是没有意义的。可以想办法找到这些位置进行优化。


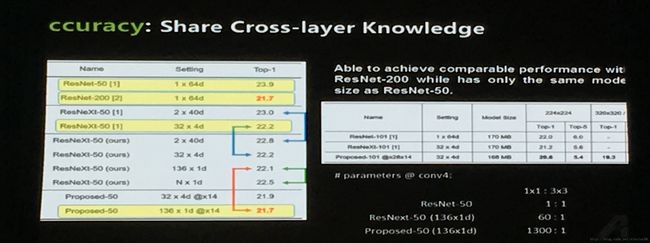
提高模型预测精度的一个有效方法是共享跨层信息,例如ResNet的跨层连接设计。
以上就是VALSE2017上关于深度学习网络模型压缩优化的部分选摘。
