协程有一派的实现方式是基于ucontext api实现的。理解协程的原理,首先要明白这几个api的用途。
1. ucontext的用法
创建、保存、切换用户态执行“上下文”(context)的API : ucontext
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);
int swapcontext(ucontext_t *oucp, ucontext_t *ucp);
int getcontext(ucontext_t *ucp);
int setcontext(const ucontext_t *ucp);
- ucontext的定义如下
typedef struct ucontext {
struct ucontext *uc_link;
sigset_t uc_sigmask;
stack_t uc_stack;
mcontext_t uc_mcontext;
...
} ucontext_t;
uc_link 是:字段保存当前context结束后继续执行的context记录;
uc_sigmask 是:记录该context运行阶段需要屏蔽的信号;
uc_stack 是:该context运行的栈信息;
uc_mcontext 是:保存具体的程序执行上下文(如PC值、堆栈指针、寄存器值等信息)其实现方式依赖于底层运行的系统架构,是平台、硬件相关的;
- getcontext 函数
int getcontext(ucontext_t *ucp)
# 这个函数的功能是把当前的上下文保存到ucp指针所指向的空间中
# 在执行正确的情况下,该函数直接切入到新的执行状态,不再会返回。
# 比如我们用上面介绍的makecontext初始化了一个新的上下文
# 并将入口指向某函数entry(),那么setcontext成功后就会马上运行entry()函数
- setcontext 函数
int setcontext(const ucontext_t *ucp)
# 这个函数的功能是将当前程序执行切换到参数ucp所指向的上下文状态
- makecontext 函数
int makecontext(ucontext_t *ucp, void (*func)(), int argc, ...)
# 这个函数的功能是初始化了一个用户的上下文
# func指明了setcontext的时候的入口函数(也是就setcontext立刻执行的函数)
# argc指明了函数的参数
- swapcontext 函数
int swapcontext(ucontext_t *oucp, ucontext_t *ucp)
# 首先执行getcontext(oucp); //保存当前上下文到oucp
# 执行setcontext(ucp);//执行ucp上下文的函数
# 为了简化切换操作的实现,ucontext 机制里提供了swapcontext这个函数
# 用来“原子”地完成旧状态的保存和切换到新状态的工作
# 这并非真正的原子操作
#include
#include
void func1(void * arg)
{
puts("1");
puts("11");
}
int main()
{
char stack[1024*128];
ucontext_t child,main;
getcontext(&child); //获取当前上下文
child.uc_stack.ss_sp = stack;//指定栈空间
child.uc_stack.ss_size = sizeof(stack);//指定栈空间大小
child.uc_stack.ss_flags = 0;
child.uc_link = &main;//设置后继上下文
makecontext(&child,(void (*)(void))func1,0);//设置child协程执行func1函数
swapcontext(&main,&child);//保存当前上下文到main,执行child上下文,因为child上下文后继是main,所以执行了func1函数后,会回到此处
puts("main");//如果设置了后继上下文,func1函数指向完后会返回此处
return 0;
}
# 输出:
1
11
main
#include
#include
#include
int main(int argc, char *argv[]) {
ucontext_t context;
getcontext(&context);
puts("Hello world");
sleep(1);
setcontext(&context);
return 0;
}
2. 基于ucontext的云风的协程库
基于context做了一个协程库,看看也挺有意思的。
- 这是一个非对称的协程库,协程之间切换的逻辑是:
# 非对称的协程的切换是要回到main函数的
co1 --> yeild --> main --> co2 ---> yeild -->
- 切换协程之前 原来的函数栈存在哪里?
// 协程调度器
struct schedule {
char stack[STACK_SIZE];
ucontext_t main; // 正在running的协程在执行完后需切换到的上下文,由于是非对称协程,所以该上下文用来接管协程结束后的程序控制权
int nco; // 调度器中已保存的协程数量
int cap; // 调度器中协程的最大容量
int running; // 调度器中正在running的协程id
struct coroutine **co; // 连续内存空间,用于存储所有协程任务
};
// 协程任务类型
struct coroutine {
coroutine_func func; // 协程函数
void *ud; // 协程函数的参数(用户数据)
ucontext_t ctx; // 协程上下文
struct schedule * sch; // 协程所属的调度器
// ptrdiff_t定义在stddef.h(cstddef)中,通常被定义为long int类型,通常用来保存两个指针减法操作的结果.
ptrdiff_t cap; // 协程栈的最大容量
ptrdiff_t size; // 协程栈的当前容量
int status; // 协程状态(COROUTINE_DEAD/COROUTINE_READY/COROUTINE_RUNNING/COROUTINE_SUSPEND)
char *stack; // 协程栈
};
// 创建协程调度器schedule
struct schedule * coroutine_open(void) {
struct schedule *S = malloc(sizeof(*S)); // 从堆上为调度器分配内存空间
S->nco = 0; // 初始化调度器的当前协程数量
S->cap = DEFAULT_COROUTINE; // 初始化调度器的最大协程数量
S->running = -1;
S->co = malloc(sizeof(struct coroutine *) * S->cap); // 为调度器中的协程分配存储空间
memset(S->co, 0, sizeof(struct coroutine *) * S->cap);
return S;
}
也就是说,切换协程的时候,schedule上面有一个存放协程栈的数组,通过这个数组,来保存原来的上下文。(先把原来的上下文存在new出来的堆空间上面,然后再进行切换。)
-
一个协程的栈多大?协程切换的开销在哪里? 线程的切换的开销在哪里?线程的栈有多大?
协程栈:128K
线程的栈:8Mulimit -a # 查看线程栈 为什么要使用协程? 协程可以干什么?
简单的来说,就是改造异步的逻辑。写了一个小例子: https://github.com/zhaozhengcoder/coroutine/blob/master/test_demo1.c
- 云风协程库的注释版本
https://github.com/zhaozhengcoder/coroutine
3. 函数调用的切换的逻辑
-
linux 内存空间的布局
 image.png
image.png
这里考虑的是函数栈,就只分析stack。
- stack
- 函数stack是从高地址向下增长
- stack有编译器来分配,它的数据结构是一个栈
- stack的大小是一般是8M
Linux中 ulimit -s 命令可查看和设置堆栈最大值
当函数进行调用的时候,这个栈是如何变化的?
- 每个函数栈有两个指针,一个是栈底(栈帧指针EBP),一个是栈顶指针(ESP),一个函数栈的大小是位于这两个指针之间(ESP, EBP 是两个寄存器,里面存放这指向栈底和栈顶的指针)。
- 函数调用的
第零步就是把调用函数的参数压栈
第一步就是把当前函数的返回地址压栈
第二步是把把原来的EBP压栈,然后更新型的EBP(指向func函数的 EBP)
第三步是ESP(func函数的ESP),创建变量,然后不停的放到里面。
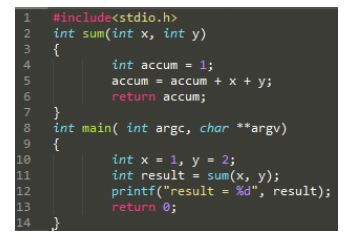
image.png
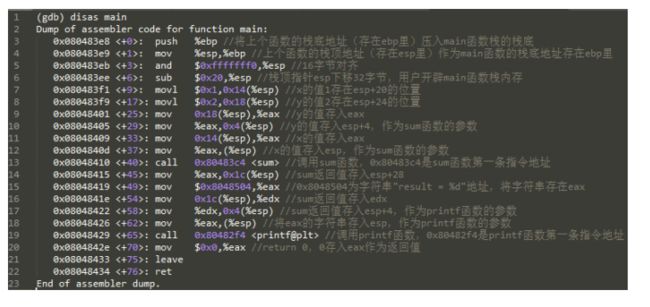
image.png
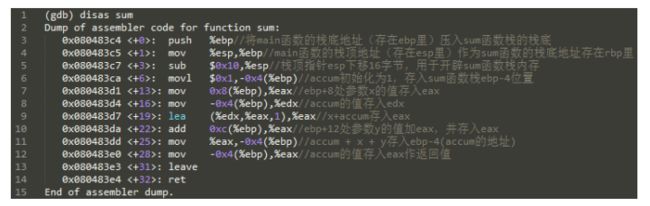
image.png
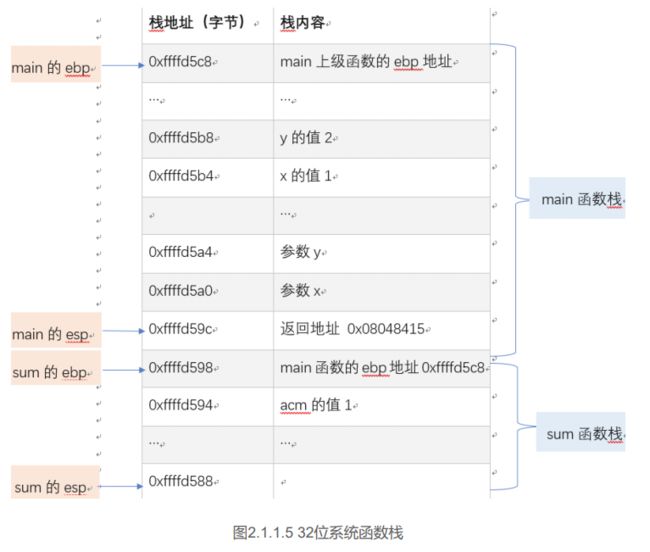
image.png
libco 协程库
todo
- 参考:
协程 : https://illx.ink/article/17
linux 进程空间 : https://www.cnblogs.com/clover-toeic/p/3754433.html
linux 进程空间 : https://www.jianshu.com/p/f9760cb3cea2