1 介绍
PhantomJS是一个×××面的,可脚本编程的WebKit浏览器引擎。它原生支持多种web 标准:DOM 操作,CSS选择器,JSON,Canvas 以及SVG。官方文档
2 安装
PhantomJS分别提供了win、linux等多个平台的安装包,大家可以直接下载相应平台版本安装即可。
安装包
我是安装在win10下,下载完配置截图如下:
记住phantomjs.exe目录,下面要用
点击我的电脑右键---属性---高级系统设置---环境变量---系统变量---path--添加上面的路径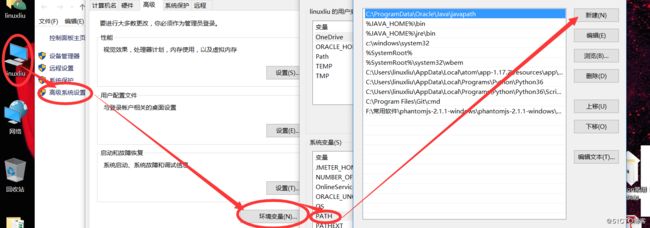
打开cmd,输入phantomjs -v查看:
图中返回版本信息表示成功。
3 快速开始
3.1 Hello, World!
创建一个hello.js文件,文件内容如下:
console.log('Hello, world!');
phantom.exit();在cmd或pycharm中直接执行,结果如下:
在第一行中,日志将把传递的字符串打印到终端。第二行,退出执行。
注意:phantomjs.exit()一定不要忘记加,不然js不会被终止。
3.2 页面加载
可以通过创建web页面对象来加载、分析和呈现web页面。
下面的脚本演示了页面对象最简单的用法。保存为文件baidu.js,它加载百度页面,然后将其保存为一个图像,图像被保存在脚本运行的目录中。
var page = require('webpage').create();
page.open('https://www.baidu.com', function(status) {
console.log("Status: " + status);
if(status === "success") {
page.render('baidu.png');
}
phantom.exit();
});
执行结果:
由于它的渲染特性,可以使用phantomjs来捕获web页面,本质上是对内容进行屏幕截图。
3.3 测试加载页面速度
以下loadspeed.js脚本加载指定的URL(不要忘记加http协议),并测量加载它所需的时间。
var page = require('webpage').create(),
system = require('system'),
t, address;
if (system.args.length === 1) {
console.log('Usage: loadspeed.js ');
phantom.exit();
}
t = Date.now();
address = system.args[1];
page.open(address, function(status) {
if (status !== 'success') {
console.log('FAIL to load the address');
} else {
t = Date.now() - t;
console.log('Loading ' + system.args[1]);
console.log('Loading time ' + t + ' msec');
}
phantom.exit();
});
脚本运行结果如下:
3.4 代码评估
使用evaluate()函数在web页面的内容评估JavaScript代码,评估是一个“沙盒”,代码无法访问其自身页面内容之外的任何JavaScript对象和变量,从evaluate()返回一个不能包含函数或闭包的简单对象。
下面是一个展示网页标题的例子:
var page = require('webpage').create();
page.open('https://www.taobao.com', function(status) {
var title = page.evaluate(function() {
return document.title;
});
console.log('Page title is ' + title);
phantom.exit();
});
执行结果: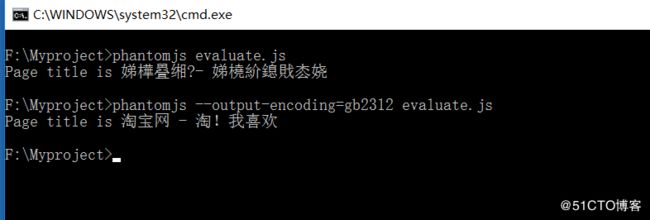
图片里可以看到我加了--output-encoding=gb2312,如果不加会乱码,后续会研究这个问题,现在想到的解决办法就是这样。
任何来自web页面的控制台消息,包括来自evaluate()中的代码,都不会在默认情况下显示。要纠正这中方式,可以使用onConsoleMessage回掉。前面的例子可以重写为:
var page = require('webpage').create();
page.onConsoleMessage = function(msg) {
console.log('Page title is ' + msg);
};
page.open('https://www.taobao.com', function(status) {
page.evaluate(function() {
console.log(document.title);
});
phantom.exit();
});
3.5 屏幕捕捉
因为 PhantomJS 使用了 WebKit内核,是一个真正的布局和渲染引擎,它可以像屏幕截图一样捕获一个web界面。因为PhantomJS 可以在web页面上呈现任何内容,所以它不仅用到HTML,CSS的内容转化,还用在SVG,Canvas的转化。
下面的例子展示了用PhantomJS加载github捕捉页面,生成github.png图片
var page = require('webpage').create();
page.open('http://github.com/', function() {
page.render('github.png');
phantom.exit();
});
PhantomJS除了支持png格式,还支持JPEG, GIF, and PDF格式。测试例子
你可以用页面的属性改变截图和网页的大小,见下面示例:
var page = require('webpage').create();
//viewportSize being the actual size of the headless browser
page.viewportSize = { width: 1024, height: 768 };
//the clipRect is the portion of the page you are taking a screenshot of
page.clipRect = { top: 0, left: 0, width: 1024, height: 768 };
//the rest of the code is the same as the previous example
page.open('https://www.baidu.com', function() {
page.render('github.png');
phantom.exit();
});
通过viewportSize 和 clipRect 属性。
viewportSize 是视区的大小,你可以理解为你打开了一个浏览器,然后把浏览器窗口拖到了多大。
clipRect 是裁切矩形的大小,需要四个参数,前两个是基准点,后两个参数是宽高。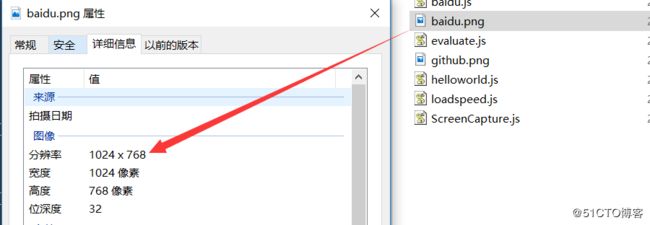
3.6 网络监控
由于PhantomJS允许对网络流量进行检查,因此可以对网络行为和性能进行各种分析,所有的资源请求和响应都可以使用onResourceRequested和onResourceReceived来进行嗅探。一个简单的日志记录每个请求和响应的例子,脚本名称netlog.js:
var page = require('webpage').create();
page.onResourceRequested = function(request) {
console.log('Request ' + JSON.stringify(request, undefined, 4));
};
page.onResourceReceived = function(response) {
console.log('Receive ' + JSON.stringify(response, undefined, 4));
};
page.open(url);
运行结果会打印出所有以JSON格式输出资源的请求和接收状态。
3.7 页面自动化
因为PhantomJS可以加载和操作网页,所以执行各种页面自动操作是非常完美的。
DOM操作
由于脚本的执行方式就像是在web浏览器上运行,所以执行标准的DOM脚本和CSS选择器完全没有问题。
以下useragent.js示例演示了读取User-Agent的id为qua的textContent属性
var page = require('webpage').create();
console.log('The default user agent is ' + page.settings.userAgent);
page.settings.userAgent = 'SpecialAgent';
page.open('http://www.httpuseragent.org', function(status) {
if (status !== 'success') {
console.log('Unable to access network');
} else {
var ua = page.evaluate(function() {
return document.getElementById('qua').textContent;
});
console.log(ua);
}
phantom.exit();
});
执行结果:
使用jQuery 和其它库
在1.6版中,您还可以使用页面将jQuery包含到页面中。
var page = require('webpage').create();
page.open('http://www.sample.com', function() {
page.includeJs("http://ajax.googleapis.com/ajax/libs/jquery/1.6.1/jquery.min.js", function() {
page.evaluate(function() {
$("button").click();
});
phantom.exit()
});
});上面的代码片段将打开一个web页面,将jQuery库包含到页面中,然后单击所有使用jQuery的按钮。它将从web页面退出。确保在页面中放置退出语句。包括js,或者它可能在javascript代码被包含之前就退出。
更多例子
好吧,看完这一节是不是感觉一脸懵逼,不知道再干什么,跟python爬虫有毛关系,上张图供大家理解:
图片来源:知乎用户yea yee