上一篇内容介绍了爬虫的基础架构及环境配置,这一篇我们将用一个简单的爬虫例子来熟悉一下scrapy框架。
1 创建项目
首先要创建一个项目,注意:在你想要放代码的目录中执行下面的命令(具体如何在pycharm中调试可以看上一篇文章运维学python之爬虫高级篇(一)Scrapy框架入门
scrapy startproject sp创建完成后,项目结构如下:
2 第一个spider
2.1 寻找目标并编写spider
爬取的网站是:中国图书网
爬取的内容是:搜索python关键字返回的页面信息中书籍名称。如下图: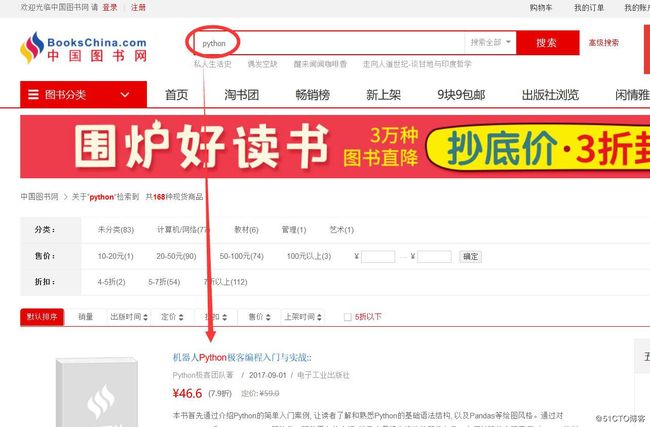
spider是你定义的类,而Scrapy用来从网站(或一组网站)中抓取信息。spider必须继承scrapy.Spider子类和定义初始化的请求,可以选择如何跟踪页面中的链接,以及如何解析下载的页面内容以和提取数据。首先,在我们的项目中spiders目录下创建tushu_spider.py,代码内容如下:
# -*- coding: utf-8 -*-
import scrapy
class TushuSpider(scrapy.Spider):
"""
定义图书网爬虫类,爬取搜索python后的图书名称
"""
# name必须要有,而且再整个项目中是唯一的不能重复
name = "tushu"
def start_requests(self):
"""
start_requests方法必须返回一个可迭代的请求(可以返回一个请求列表,或者编写一个生成器函数),
这将使爬虫开始爬取数据。后续请求将依次从这些初始请求中生成。
"""
# 定义urls列表
urls = [
'http://www.bookschina.com/book_find2/?stp=python&sCate=0',
'http://www.bookschina.com/book_find2/default.aspx?stp=python&scate=0&f=1&sort=0&asc=0&sh=0&so=1&p=2&pb=1',
]
for url in urls:
# 这里为了返回一个可迭代的对象,使用了yield,yield的作用就是函数运行到这里后中断,
# 并返回一个迭代值,下次执行时从yield的下一个语句继续执行。
yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
"""
parse()方法通常解析response,提取数据,并找到新的url来跟踪和创建新的请求(Request)。
:param response: start_requests方法实例化的网页
"""
# 获取response中class为infor的div中class为name的h2元素
p = response.css("div.infor h2.name")
# 从上面获取的对象中提取出属性为title的标签a的内容(列表形式)
titles = p.css("a::attr(title)").extract()
# 打印获取的内容
for title in titles:
print(title)上面的代码已经详细注释了,过多的就不再说明。
其中的name、start_requests、parse等属性和方法都是继承scrapy.Spiders类。
2.2 运行
方法一:进入项目目录,执行下面命令(其中tushu为爬虫类中定义的name=“tushu”)
scrapy crawl tushu方法二:
在pycharm中运行main.py,main.py的内容如下:
# -*- coding: utf-8 -*-
from scrapy import cmdline
cmdline.execute("scrapy crawl tushu".split())其实原理和方法一相同,只不过为了方便在pycharm中使用,输出结果如下: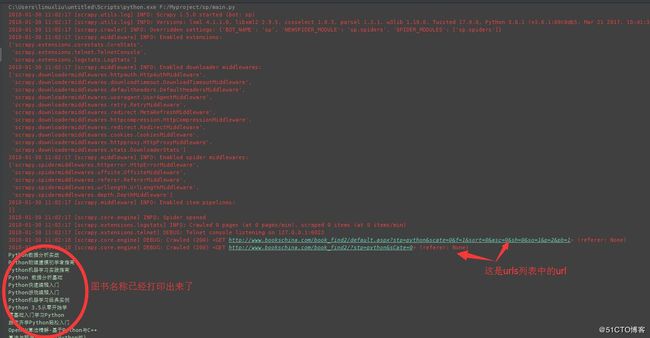
上面操作的流程如下:
1.通过start_requests中的scrapy.Request请求url;
2.收到response后,实例化为对象,调用回调函数;
3.将实例化后的对象作为参数,通过parse方法进行解析。
2.3 start_requests简单格式
可以使用一个url列表来定义一个start_urls类属性替代通过执行start_requests()方法从urls中生成scrapy.Request对象,然后,这个url列表将被用于start_requests()的默认实现来为爬虫创建初始请求,代码如下:
# -*- coding: utf-8 -*-
import scrapy
class TushuSpider(scrapy.Spider):
"""
定义图书网爬虫类,爬取搜索python后的图书名称
"""
# name必须要有,而且再整个项目中是唯一的不能重复
name = "tushu"
# 定义urls列表,注意要写成start_urls
start_urls = [
'http://www.bookschina.com/book_find2/?stp=python&sCate=0',
'http://www.bookschina.com/book_find2/default.aspx?stp=python&scate=0&f=1&sort=0&asc=0&sh=0&so=1&p=2&pb=1',
]
def parse(self, response):
"""
parse()方法通常解析response,提取数据,并找到新的url来跟踪和创建新的请求(Request)。
:param response:下载的网页内容
"""
# 获取response中class为infor的div中class为name的h2元素
p = response.css("div.infor h2.name")
# 从上面获取的对象中提取出属性为title的标签a的内容(列表形式)
titles = p.css("a::attr(title)").extract()
# 打印获取的内容
for title in titles:
print(title)
上面的代码执行效果与通过start_reuquests的方式是相同的,不过代码省略了一些。之所以能这样写是因为parse()是Scrapy的默认的回调方法,没有明确指定回调的情况下,默认会调用parse()。
2.4 提取数据
如果光靠程序去跑,而不提前验证我们的提取语句是否正确显然是不高效的,最好的方式是使用scrapy的Scrapy shell 的方式去执行,如下例:
scrapy shell "http://www.bookschina.com/book_find2/?stp=python&sCate=0"注意:网址要加引号,linux下可以单引号或双引号,win下必须要用双引号,防止因为“?”、“&”等字符造成错误。
运行命令后,输出结果如下: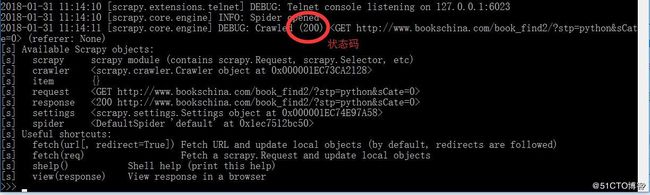
如果我们不确定是否获取页面成功可以看图中标记出来的状态码,或者直接运行命令view(response)就会打开你获取的response,如下: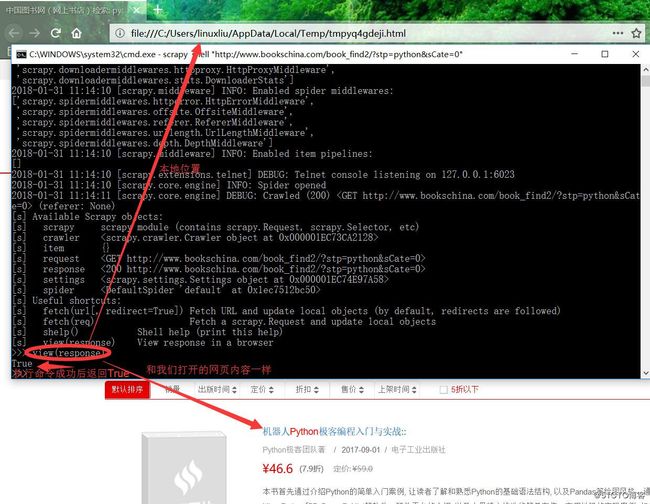
接下来我们就要通过工具分析,来获取我们需要的内容了: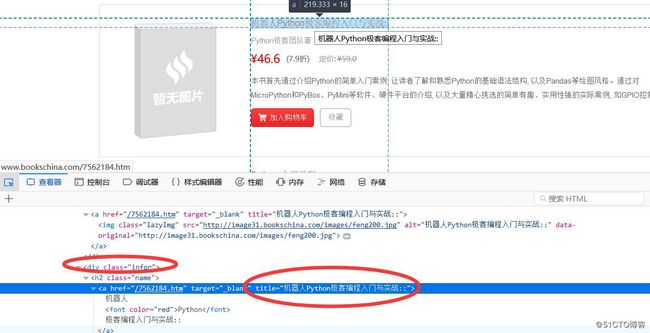
从图中可以看到,我们需要的是class为infor的div标签中的a标签的title属性。使用scrapy shell,可以使用CSS选择response对象中的元素:
response.css("div.infor a::attr(title)")结果如下: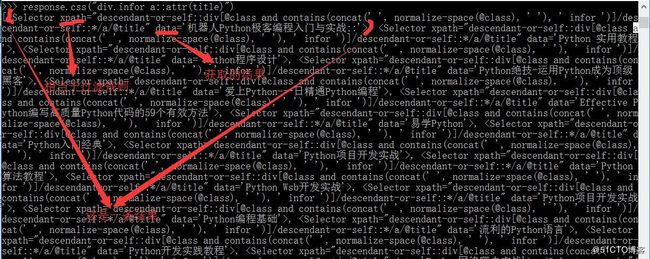
运行response.css("div.infor a::attr(title)")的结果是一个类似于列表的对象,名为SelectorList,它代表了一个包含xml/html元素的选择器对象列表,允许运行进一步的查询,以便细粒度选择或提取数据。
我们可以进一步获取到title的内容,也就是上图中data的部分,如下:
>>> response.css("div.infor a::attr(title)").extract()结果如下:
如果只想获取第一个结果,可以直接运行:
>>> response.css("div.infor a::attr(title)").extract_first()当然获取的结果是列表,也可以使用如下命令:
>>> response.css("div.infor a::attr(title)")[0].extract()以上两种方法结果都是一样的,均为:'机器人Python极客编程入门与实战::',不过使用.extract_first可以避免没有获取结果时返回的错误IndexError。
当然也可以是用正则re方式来匹配:
>>> response.css("div.infor a::attr(title)").re("python.*")
['python开始学编程']还可以使用我们之前讲过的xpath方式来获取:
>>> response.xpath("//h2[@class='name']/a/@title").extract()
['机器人Python极客编程入门与实战::', 'Python 实用教程', 'Python程序设计', 'Python绝技-运用Python成为顶级***', '爱上Python-一日精通Python编程', 'Effective Python编写高质量Python代码的59个有效方法', '易学Python', 'Python入门经典', 'Python项 目开发实战', 'Python算法教程', 'Python Wsb开发实战', 'Python项目开发实战', 'Python编程基础', '流利的Python语言', 'Python开发实践教程', 'Python网络爬虫实战', 'Python金融实战', 'Python开发向导', '毫无障碍学Python', '流畅的Python', 'Python数据分析', '用Python写网络爬虫', 'Python即学即用', 'Python机器学习算法', 'Python漫游指南-(影印版)', '人工智能:Python实现', 'Python大学教程', 'Python自然语言处理', 'Python游戏编程入门', 'Python硬件编程实战', 'Python测试驱动开发-(影印版)', 'Python程序设计', 'Python网络数据采集', 'Python语言程序设计', 'Python密码学编程', 'Python 3基础教程', '零基础入门学习Python', '从python开始学编程', 'Python数据可视化', 'Python机器学习实践指南', 'Python数据科学实践指南', 'Python爬虫开发与项目实战', 'Python高性能编程', 'Python 3.5从零开始学', '预测分析-Python语言实现', 'Python 数据分析基础', 'Python 数据分析实践', 'Python机器学习经典实例', 'Python数据分析基础', '跟9787121325601老齐学Python实战', 'Python程序设计教程', 'Python语言程序 设计']至于css和xpath方式,需要大家多练习,可以用scrapy shell方式去尝试获取response的内容,不知道怎么获取的用搜索引擎查一查,因为这样记忆起来比去被背每一个的作用会好(个人拙见)。
2.5 存储数据
最简单的存储方式是使用-o参数指定输出:
scrapy crawl tushu -o title.json如果是小项目,我们用上面的这种方式就可以,但大项目就要用到scrapy的Item pipline功能了,后续我们会介绍。
3 翻页
爬取一页数据肯定不是我们希望的,我们想要爬取搜索结果的所有页面title,那要怎么办呢?好的,接下来介绍如何实现翻页,其实更准确的是提取链接,不光可以用来翻页,可以提取出初始网页的链接进行进一步爬取。
我们使用翻页是为了更好理解,页面信息如下: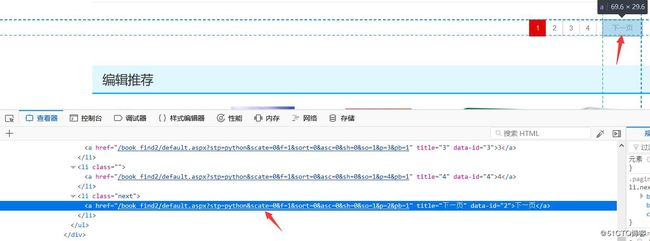
我们要获取箭头所指出的链接,如下:
>>> response.css("li.next a::attr(href)").extract_first()
'/book_find2/default.aspx?stp=python&scate=0&f=1&sort=0&asc=0&sh=0&so=1&p=2&pb=1'现在看一看我们的spider,可以实现递归地跟踪到下一个页面的链接,从中提取数据:
# -*- coding: utf-8 -*-
import scrapy
class TushuSpider(scrapy.Spider):
"""
定义图书网爬虫类,爬取搜索python后的图书名称
"""
# name必须要有,而且再整个项目中是唯一的不能重复
name = "tushu"
# 定义urls列表
start_urls = [
'http://www.bookschina.com/book_find2/?stp=python&sCate=0',
]
def parse(self, response):
"""
parse()方法通常解析response,提取数据,并找到新的url来跟踪和创建新的请求(Request)。
:param response:下载的网页内容
"""
# 获取response中class为infor的div中class为name的h2元素
p = response.css("div.infor h2.name")
# 从上面获取的对象中提取出属性为title的标签a的内容(列表形式)
titles = p.css("a::attr(title)").extract()
# 打印获取的内容
for title in titles:
print(title)
# 获取下一页中的链接
next_page = response.css("li.next a::attr(href)").extract_first()
if next_page is not None:
# 通过urljoin将相对链接拼接成绝对链接
next_page = response.urljoin(next_page)
# 通过Request获取next_page对象作为参数传入parse方法
yield scrapy.Request(next_page, callback=self.parse)
输出结果就是4页的内容,太多就不截图了。使用这个功能,就可以构建复杂的爬虫程序,根据定义的规则来跟踪链接,并根据所访问的页面提取不同类型的数据。
我们还可以使用response.follow来实现创建请求对象的快捷方式,代码如下:
重复代码略
# 获取下一页中的链接
next_page = response.css("li.next a::attr(href)").extract_first()
if next_page is not None:
# 使用response.follow拼接为绝对路径后获取请求,调用回调函数处理
yield response.follow(next_page, callback=self.parse)不像scrapy.Request, response.follow直接支持相对url——不需要调用urljoin。注意response.follow只返回一个请求实例;仍然需要yield这个请求。
4 使用spider 参数
你可以使用命令行参数通过-a参数,指定spider的默认属性,如下面命令中的tag:
scrapy crawl quotes -o quotes-humor.json -a tag=index参数被传递给spider的init方法,并在默认情况下成为了spider属性。我们再用例子说明:
# -*- coding: utf-8 -*-
import scrapy
class TushuSpider(scrapy.Spider):
"""
定义图书网爬虫类,爬取搜索python后的图书名称
"""
# name必须要有,而且再整个项目中是唯一的不能重复
name = "tushu"
def start_requests(self):
# 初始链接
urls = 'http://www.bookschina.com/'
# 通过getattr获取tag属性,不存在默认为None
tag = getattr(self, 'tag', None)
if tag is not None:
url = urls + tag
yield scrapy.Request(url, self.parse)
def parse(self, response):
"""
parse()方法通常解析response,提取数据,并找到新的url来跟踪和创建新的请求(Request)。
:param response:下载的网页内容
"""
# 获取response中class为infor的div中class为name的h2元素
p = response.css("div.infor h2.name")
# 从上面获取的对象中提取出属性为title的标签a的内容(列表形式)
titles = p.css("a::attr(title)").extract()
# 打印获取的内容
for title in titles:
print(title)
# 获取下一页中的链接
next_page = response.css("li.next a::attr(href)").extract_first()
if next_page is not None:
# 使用response.follow拼接为绝对路径后获取请求,调用回调函数处理
yield response.follow(next_page, callback=self.parse)执行命令:
scrapy crawl quotes -a tag=index传入的tag为index,执行结果如下: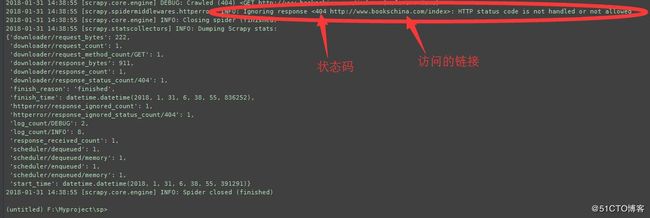
因为页面不存在,所以是404,而且我们也可以看到,访问的地址只有:http://www.bookschina.com/index 这一个。
好了,这一篇就到这里了,虽然只是做了一个简单的基础部分介绍,但篇幅还是比较长,许多功能仍没有展开,后续我也会梳理条目来写,主要还是多练习。