vrrp:虚拟路由冗余协议(Virtual Router Redundancy Protocol),冗余路由单点故障,实现把一个地址绑定到n台服务器上(只生效一台),通过组播传递信号,当一个点故障时候,选举另外节点来当路由。
keepalive工作流程:监视进程watchDog监视 vrrp跟checkers是否正常,vrrp跟监测进程相互配合使用,如有异常触发系统调用跟邮件服务,调整浮动ip节点,keepalive还内置ipvs规则装饰跟启动ipvs脚本。
安装
网卡组播必须开启
ens34: flags=4163 mtu 1500
ip link set multicast on dev ens33
ip link set multicast off dev ens33 安装
[root@node1 ~]# yum -y install keepalivedvrrp使用
主节点配置
[root@node1 keepalived]# vim /etc/keepalived/keepalived.conf
global_defs {
notification_email {
root@localhost
}
notification_email_from Alexandre.Cassen@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node1 #单个id
vrrp_mcast_group4 224.1.101.33 #组播地址
}
vrrp_instance VI_1 {
state MASTER #当前节点在此虚拟路由器上的初始状态;只能有一个是MASTER,余下的都应该为BACKUP
interface ens34 #通告进行所需 接口
virtual_router_id 51 #虚拟路由器标识:VRID(0-255),唯一标识虚拟路由器
priority 100 #优先级
advert_int 1 #vrrp通告的时间间隔,默认1s
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.199
}
#状态改变时候出发钩子函数
notify_master "/etc/keepalived/notify.sh master" #当前节点成为主节点时触发的脚本
notify_backup "/etc/keepalived/notify.sh backup" #当前节点转为备节点时触发的脚本
notify_fault "/etc/keepalived/notify.sh fault" #当前节点转为“失败”状态时触发的脚本
}从节点(区别主节点有3个地方)
global_defs {
notification_email {
root@localhost
}
notification_email_from Alexandre.Cassen@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node2 #1.标识
vrrp_mcast_group4 224.1.101.33
}
vrrp_instance VI_1 {
state BACKUP #2.备用
interface ens34
virtual_router_id 51
priority 96 #3.优先级
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.199
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}邮件通知脚本(如果是双主,脚本后面加参数区分)
[root@node1 keepalived]# vim notify.sh
#!/root/.virtualenvs/shellenv/bin/python
from raven import Client
import subprocess
import sys
if len(sys.argv) < 2:
exit()
notify = sys.argv[1]
interface = 'ens34'
res = subprocess.getstatusoutput("ip addr show %s|egrep -o 'inet [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'|egrep -o '[^a-z ].*'"%(interface))
ip = res[1]
ip = ip.replace('\n', ' ')
res = subprocess.getstatusoutput("hostname")
hostname = res[1]
res = subprocess.getstatusoutput("uptime")
cpu = res[1]
res = subprocess.getstatusoutput("free -h")
memory = res[1]
res = subprocess.getstatusoutput("df -h")
disk = res[1]
notify_message = {'master':'Change to master', 'backup':'Change to backup', 'fault':'Server error'}
message = notify_message.get(notify,'{%s} no this notify'%(notify))
info = '''
-------- info of %s -----
Hostname:%s
Interface:%s
IP:%s
CPU:%s
Memory:
%s
Disk:
%s
Message: %s
''' % (hostname, hostname, interface, ip, cpu, memory,disk, message)
client = Client('https://[email protected]/1219450')
client.captureMessage(info)启动
[root@node1 keepalived]# systemctl start keepalived主节点通告
[root@node1 keepalived]# tcpdump -i ens34 -nn host 224.1.101.33
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens34, link-type EN10MB (Ethernet), capture size 262144 bytes
13:04:17.240395 IP 192.168.1.200 > 224.1.101.33: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20备用节点收通告
[root@node2 keepalived]# tcpdump -i ens34 -nn host 224.1.101.33
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens34, link-type EN10MB (Ethernet), capture size 262144 bytes
13:05:36.437749 IP 192.168.1.200 > 224.1.101.33: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20主节点查看
[root@node1 keepalived]# ip a
3: ens34: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:46:a6:40 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.200/24 brd 192.168.1.255 scope global ens34
valid_lft forever preferred_lft forever
inet 192.168.1.198/32 scope global ens34:0
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe46:a640/64 scope link
valid_lft forever preferred_lft forever 从节点
此时从节点没有 ens34:0主节点故障
#ip到从节点上
[root@node2 keepalived]# ifconfig
ens34:0: flags=4163 mtu 1500
inet 192.168.1.199 netmask 255.255.255.255 broadcast 0.0.0.0
ether 00:0c:29:34:f5:84 txqueuelen 1000 (Ethernet) 主节点恢复,因为优先级比从节点高,所以ip又到主节点上
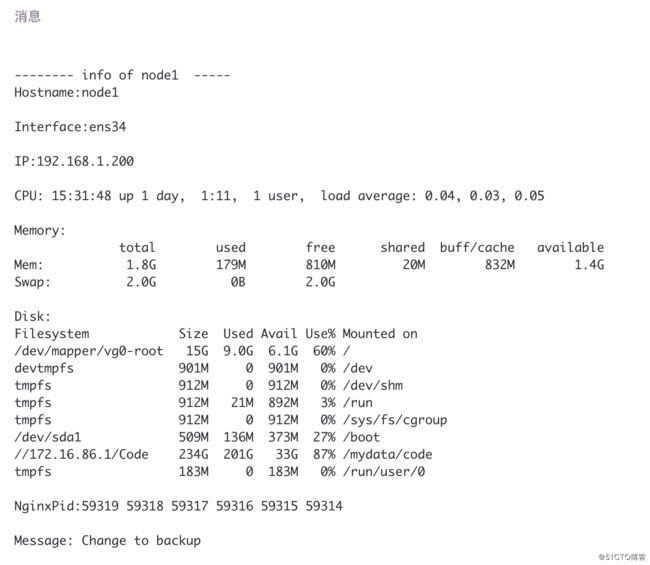
邮箱读取
主服务开启:

主节点停掉服务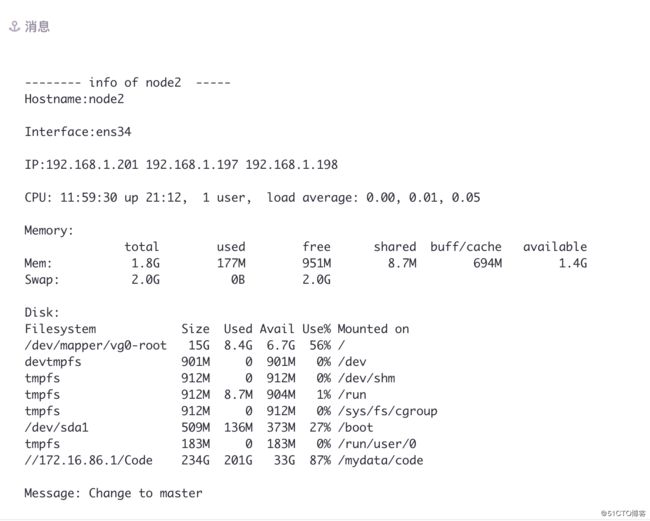
日志配置
[root@node1 keepalived]# vim /etc/sysconfig/keepalived
KEEPALIVED_OPTIONS="-D -S 3"
[root@node1 keepalived]# vim /etc/rsyslog.conf
local3.* /var/log/keepalive.log
[root@node1 keepalived]# systemctl restart rsyslog
[root@node1 keepalived]# systemctl restart keepalivedlvs双主模型
双主配置单节点配置,另外节点只需改动主从、routerid、优先级即可
global_defs {
notification_email {
root@localhost
}
notification_email_from Alexandre.Cassen@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node1
vrrp_mcast_group4 224.1.101.33
}
vrrp_instance VI_1 {
state MASTER
interface ens34
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.198 dev ens34 label ens34:0
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
vrrp_instance VI_2 {
state BACKUP
interface ens34
virtual_router_id 52
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
192.168.1.197
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
virtual_server 192.168.1.198 80 {
delay_loop 1
lb_algo wrr
lb_kind DR
protocol TCP
sorry_server 192.168.1.200 80
real_server 192.168.1.202 80{
weight 1
HTTP_GET {
url {
path /index.html
status_code 200
}
nb_get_retry 3
delay_before_retry 2
connect_timeout 3
}
}
real_server 192.168.1.203 80{
weight 1
TCP_CHECK {
nb_get_retry 3
delay_before_retry 2
connect_timeout 3
}
}
}
virtual_server 192.168.1.197 80 {
delay_loop 1
lb_algo wrr
lb_kind DR
protocol TCP
sorry_server 192.168.1.200 80
real_server 192.168.1.202 80{
weight 1
HTTP_GET {
url {
path /index.html
status_code 200
}
nb_get_retry 3
delay_before_retry 2
connect_timeout 3
}
}
real_server 192.168.1.203 80{
weight 1
TCP_CHECK {
nb_get_retry 3
delay_before_retry 2
connect_timeout 3
}
}
}[root@node1 keepalived]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.1.197:80 wrr
-> 192.168.1.202:80 Route 1 0 0
-> 192.168.1.203:80 Route 1 0 0
TCP 192.168.1.198:80 wrr
-> 192.168.1.202:80 Route 1 0 0
-> 192.168.1.203:80 Route 1 0 0[root@node2 keepalived]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.1.197:80 wrr
-> 192.168.1.202:80 Route 1 0 0
-> 192.168.1.203:80 Route 1 0 0
TCP 192.168.1.198:80 wrr
-> 192.168.1.202:80 Route 1 0 0
-> 192.168.1.203:80 Route 1 0 0由此可见:ipvs规则两台机器配置是一样的,只是vip是飘动的,keepalive针对lvs还实现了健康状态监测
marvindeMacBook-Pro:~ marvin$ curl http://192.168.1.197/
node4
marvindeMacBook-Pro:~ marvin$ curl http://192.168.1.197/
node3
#停掉node3节点
marvindeMacBook-Pro:~ marvin$ curl http://192.168.1.197/
node4
marvindeMacBook-Pro:~ marvin$ curl http://192.168.1.197/
node4自定义监测模型-nginx
配置手动下线文件脚本
[root@node1 keepalived]# vim down.sh
[[ -f /etc/keepalived/down ]] && exit 1 || exit 0配置文件
[root@node1 keepalived]# vim keepalived.conf
global_defs {
notification_email {
root@localhost
}
notification_email_from Alexandre.Cassen@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node1
vrrp_mcast_group4 224.1.101.33
}
vrrp_script chk_down {
script "/etc/keepalived/down.sh"
interval 1
weight -20
fall 1
rise 1
}
vrrp_script chk_nginx {
script "pidof nginx && exit 0 || exit 1"
interval 1
weight -3
fall 2
rise 2 #有可能重启后又down 所以2次比较合理
}
vrrp_instance VI_1 {
state MASTER
interface ens34
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_down
chk_nginx
}
virtual_ipaddress {
192.168.1.198/24
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}/etc/keepalived/notify.sh主要在里面加入
res = subprocess.getstatusoutput("systemctl start mynginx")
res = subprocess.getstatusoutput("pidof nginx")
nginxpid = res[1]测试
[root@node2 keepalived]# tcpdump -i ens34 -nn host 224.1.101.33
[root@node1 keepalived]# touch down
15:29:27.073406 IP 192.168.1.200 > 224.1.101.33: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20
15:29:28.074393 IP 192.168.1.200 > 224.1.101.33: VRRPv2, Advertisement, vrid 51, prio 80, authtype simple, intvl 1s, length 20
15:29:28.074710 IP 192.168.1.201 > 224.1.101.33: VRRPv2, Advertisement, vrid 51, prio 99, authtype simple, intvl 1s, length 20
[root@node1 keepalived]# rm -f down
15:30:17.179289 IP 192.168.1.201 > 224.1.101.33: VRRPv2, Advertisement, vrid 51, prio 99, authtype simple, intvl 1s, length 20
15:30:17.180088 IP 192.168.1.200 > 224.1.101.33: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20
[root@node1 keepalived]# systemctl stop mynginx
15:31:01.251469 IP 192.168.1.200 > 224.1.101.33: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20
15:31:02.253183 IP 192.168.1.200 > 224.1.101.33: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20
15:31:03.254806 IP 192.168.1.200 > 224.1.101.33: VRRPv2, Advertisement, vrid 51, prio 97, authtype simple, intvl 1s, length 20
15:31:03.255137 IP 192.168.1.201 > 224.1.101.33: VRRPv2, Advertisement, vrid 51, prio 99, authtype simple, intvl 1s, length 20
15:30:17.180088 IP 192.168.1.200 > 224.1.101.33: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20
15:30:18.181628 IP 192.168.1.200 > 224.1.101.33: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s,
随后自动启动 是因为 notify_backup "/etc/keepalived/notify.sh backup"
这个脚本写了nginx 启动邮件查看