AdaBoost概述
原创: 陈超 Refinitiv 创新实验室ARGO
“本文共3400余字,数学公式原理不深,预计阅读时间15分钟”
AdaBoost是Adaptive Boosting的简称,属于集成算法(Ensemble Method)中Boosting类别中的一种。AdaBoost是非常成功的机器学习算法,由Yoav Freund和RobertSchapire于1995年提出,他们因此获得了2003年的哥德尔奖(Gödel Prize)。本文将从下面几个方面对AdaBoost进行展开:
- 算法思想和算法简易流程
- 算法实例和算法总结
- 从广义加法模型看AdaBoost
- sklearn库相关函数
一 算法思想和算法简易流程
在Agro的《XGBOOST(一)》一文中介绍了集成算法以及作为集成算法典型代表的Boosting算法。XGBOOST算法属于Gradient Boosting框架,是Boosting算法家族的一种。作为Boosting算法家族中出现更早也同样闻名的另外一种算法便是本文要论述的AdaBoost算法。Gradient Boost和AdaBoost 最显著的相同点都在于前一轮训练结果将用来调整本轮训练的样本,从而优化本轮训练出的模型,使得整个的模型更加精确。不同点在于Grandient Boost改变的是本轮训练的样本标签,而AdaBoost 则侧重于调整本轮样本的样本权重,从而改变样本的分布。
读者可以通过AdaBoost的算法流程来发现这一不同。算法的简易流程表述如下:
1. 确定样本集
2. 初始化样本数据的权重,如每个样本的权重为1/n(假设样本个数为n)
3. 进行1,2,...,T轮迭代
a. 归一化样本权重
b. 对样本集进行训练,并计算训练误差
c. 选择误差最小的分类器作为本轮的分类器
d. 根据预测结果更新样本数据的权重:预测错误样本增加权重,预测正确样本降低权重
e. 计算分类器的权重
4. 根据分类器的预测结果及其权重加权表决最终结果
下面是一个AdaBoost的训练迭代变化图,我们可以看到在每次迭代中版本的权重的变化,分类错误的样本权重的逐渐加大,而分类正确的样本权重逐渐减少的过程。

(图片来源:https://github.com/purelyvivid/DeepLearningMachineLearning_tutorial)
接下来将通过实例展示AdaBoost的使用,归纳AdaBoost的算法详细流程,从广义加法模型(additive model)这一角度推导这一算法核心算法公式的由来。
二 算法实例和算法总结
假设训练样本如下,我们需要使用该样本对AdaBoost算法模型进行训练,训练轮数为3轮。x是特征值,y是标签(这个实例是AdaBoost的典型代表,在很多资料上都有提及)

第一轮(初始轮)
对训练数据设定为相等的权重。为了保证所有的权重值之和为1,权重一般设置为1/n,这里n=10,所以,权重值为0.1。如图所示,每个训练数据的权重如下,wn 代表的是对应x变量的权重。

i) 训练弱分类器:
因此,我们使用这个数据训练得到第一个弱分类器模型:深度为1的决策树(简单的分段函数),这个模型用数学公式表示为:

ii) 计算弱分类器决策权重
用这个模型对该第一轮训练集的数据分类,得到的结果是[ 1,1,1,-1, -1,-1,-1,-1,-1,-1],能够发现x为6,7,8的数据结果分类错误,计算得到其错误率为:
![]()
计算此 弱分类器的决策权重:
弱分类器的决策权重:

因此,可以得到第一轮的预测函数模型如下(参与决策时,我们将F预测结果值取sign):

按照sign(F₁(x))分类,训练集存在3个分类错误。
iii) 更新样本权重
根据公式
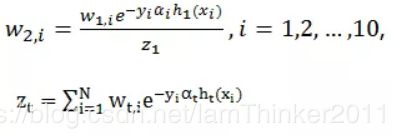
计算接下来第二轮的样本权重,其中Z为权重的归一化因子。这个公式虽然看上去复杂,但是指数部分中![]() ,
, ![]() 当预测相同时为-1,预测相反时结果为1。 所以,预测正确的样本的权重将下降,预测错误的样本权重将上升。通过上述公式计算得到第二轮的权重值如下表,红色表示分错样本的权重:
当预测相同时为-1,预测相反时结果为1。 所以,预测正确的样本的权重将下降,预测错误的样本权重将上升。通过上述公式计算得到第二轮的权重值如下表,红色表示分错样本的权重:

第二轮
i) 训练弱分类器:
用第一轮的样本权重训练弱分类器h₂(x),得:

ii) 计算弱分类器决策权重:
h₂(x)的预测结果为[1,1,1,1,1,1,1,1,-1,-1],发现x为3,4,5的数据分类错误。基于上轮样本权重,计算误差率:

计算该弱分类器的决策权重:

由此,更新第二轮的预测函数:
![]()
按照sign(F₂(x))分类,依然有3个分类错误。
iii) 更新样本权重:
根据初始轮提供的样本权重更新公式,计算得到第三轮的样本权重

第三轮(末轮)
i) 训练弱分类器:
用第二轮的权重样本训练得:

ii) 计算弱分类器决策权重:
依据此分类器的分类结果[-1,-1,-1,-1,-1,-1,1,1,1,1],发现0,1,2,9分类错误,计算错误率和弱分类器决策权重:


此时,最终的预测函数如下:![]()
按sign(F₃(x))分类,没有出现分类错误,训练终止。得到最终的训练模型:
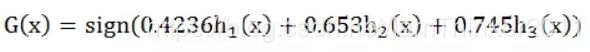
注:AdaBoost 通常迭代多次直至得到最终的强分类器。迭代范围可以自己定义,如限定收敛阈值,分类误差率小于某一个值就停止迭代;如限定迭代次数,迭代1000次停止。本例中数据简单,在第三轮迭代时,得到强分类器的分类误差率为0,结束迭代。
算法总结
由以上例子可知,AdaBoost的学习训练过程一般如下:

图片来源:https://www.cnblogs.com/ooon/p/5663975.html
AdaBoost最终得到的强学习器是:
![]()
AdaBoost算法有几个特点:
- 弱分类器系数
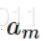 表示其在整个强分类器中的决策影响力大小,所有分类器权重之和并不为1。由其中的数学公式可知,当该弱分类器的错误率越低时,其系数越高。
表示其在整个强分类器中的决策影响力大小,所有分类器权重之和并不为1。由其中的数学公式可知,当该弱分类器的错误率越低时,其系数越高。
- 更新的样本权重在为下轮训练做准备,正确的样本权重降低,错误的分类样本权重升高,其新权重公式可以改写为:

所以,正确的样本和错误的样本的权重被放大到 倍。每轮训练结束后,错误的样本对于后续训练的影响力更大。
倍。每轮训练结束后,错误的样本对于后续训练的影响力更大。
- ooon在博客中说,“算法第 5 步中关于误差的判断,因为不满足准确性可能会带来负面效果,所以当误差率超过一半时,则会停止迭代,这样导致 Adaboost 执行不到预设的 M 轮,也就没有 M 个基学习器来做组合。这时可以抛弃当前误差较大的基学习器,按照该基学习器的结果重新调整样本权值,进而进入下一次迭代”。
三 从广义加法模型看AdaBoost
读者们看完上面的描述,一定有疑问:这个算法的样本更新权重公式是怎么来的,怎么看也不像是凭空想出来的? 为了解答这个疑问,我们从广义加法模型(additive model)来看AdaBoost,或许大家会有新的理解。
在XGBOOST一文中,曾提过广义加法模型,而且,了解广义加法模型,也是了解XGBOOST的重要基础。在通过广义加法模型推倒AdaBoost前,必须知道的三个基础是:
1 AdaBoost 是广义加法模型
2 广义加法模型优化方法是向前分步算法
2 AdaBoost的损失函数是指数损失函数
广义加法模型
加法模型预测函数:
其中,![]() 是基函数
是基函数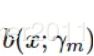 的参数,
的参数,![]() 是基函数的系数。
是基函数的系数。
假定在训练集D={(X,Y)}上广义加法模型的损失函数定义为:

求解最小化损失函数的优化函数形式如下:
要解上式这个优化参数,难度不低。所以,一般在优化加法模型时,用的方法是向前分步算法。也就是在AdaBoost中大家所看到的方法,从第一个优化方法起开始训练,逐个的训练基学习器的参数及其系数,以达到最终优化的目的。对于第M轮,有:

对于AdaBoost,其![]() ,
,![]() 怎么求呢?接下来看看广义加法模型中的AdaBoost。
怎么求呢?接下来看看广义加法模型中的AdaBoost。
广义加法模型的AdaBoost
AdaBoost采用的是指数损失函数,指数损失函数一般表示形式是:

基于该设定下,我们来推导AdaBoost算法的样本权重以及基学习器系数的公式。
在第m轮迭代时,预测函数如下:

求第m的优化值

对应AdaBoost,将上式改为

其中 。
。
观察上式可知,![]() 虽然不依赖于
虽然不依赖于![]() 和
和![]() ,但是每一轮的值不同。
,但是每一轮的值不同。![]() 最小和
最小和![]() 无关,对于任意大于0的
无关,对于任意大于0的![]() ,
,![]() 都必须取最小值:
都必须取最小值:

才能保证等式成立。所以,AdaBoost用 ![]() / Z 来重新分布样本,训练
/ Z 来重新分布样本,训练![]()
接下来极小化![]() :
:

对上式求导并使得导数为0,即可求得:

其中,

这样,从广义加法模型的角度就解释了为什么权重更新时要采用这种计算方式以及基分类器为什么要采用这种独特的权值计算方案。上述公式推导借鉴了李航的机器学习圣经《统计学习方法》,感兴趣的读者可以从书中了解更多的内容。同时,书中也专门解释了为什么AdaBoost 叫做 “自适应”提升算法,重点讲到AdaBoost的错误率是以指数速率下降,并且不考虑基学习器的错误率下界。
四 sklearn库相关函数
python sklearn库 sklearn.ensemble 包含了很多流行的提升算法,其中包括 AdaBoostClassifier和AdaBoostRegressor两个。 顾名思义,AdaBoostClassifier用于分类(可用于多分类问题),AdaBoostRegressor用于回归。
它们的构造函数如下:
class sklearn.ensemble.AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm=’SAMME.R’[9], random_state=None)
class sklearn.ensemble.AdaBoostRegressor(base_estimator=None, n_estimators=50, learning_rate=1.0, loss='linear', random_state=None)
[base_estimator] AdaBoostClassifier和AdaBoostRegressor都需要,弱学习器类型,默认是CART树,理论上可以选择任何一个学习器。常用的一般是CART决策树或者神经网络MLP。如果我们选择AdaBoostClassifier算法是SAMME.R,则我们的弱分类学习器还需要支持概率预测,也就是在scikit-learn中弱分类学习器对应的预测方法除了predict还需要有predict_proba。
[algorithm] 仅AdaBoostClassifier需要。实现了两种Adaboost分类算法,SAMME和SAMME.R,默认SAMME.R。两者的主要区别是弱学习器权重的度量,SAMME使用了上文中二元分类Adaboost算法的扩展,即用对样本集分类效果作为弱学习器权重,而SAMME.R使用了对样本集分类的预测概率大小来作为弱学习器权重。由于SAMME.R使用了概率度量的连续值,迭代一般比SAMME快。如果使用SAMME.R, 则弱分类学习器参数base_estimator必须限制使用支持概率预测的分类器,SAMME算法没有这个限制。
[loss] 仅AdaBoostRegressor需要,Adaboost.R2算法需要用到损失项。有线性‘linear’, 平方‘square’和指数 ‘exponential’三种选择, 默认是线性。
[n_estimators] AdaBoostClassifier和AdaBoostRegressor都需要。默认是50,表示最大的弱学习器的个数。
[learning_rate] AdaBoostClassifier和AdaBoostRegressor都需要。每个弱学习器的权重缩减系数,默认是1。对于同样的训练集拟合效果,较小的意味着需要更多的弱学习器。通常用步长和迭代最大次数一起来决定算法的拟合效果。
总结
AdaBoost属于Boosting算法家族的成员,其核心在于多次训练得到不同的弱学习器,而训练方式是改变训练集的样本分布。从广义加法模型更容易对其数学公式有深刻的理解。AdaBoost提出时间相对较早,很多的资料上都有提及,有兴趣或者想要深挖的读者可以通过参考资料了解更多。
AdaBoost一文就介绍到这了,谢谢大家耐心阅读,并关注我们的公众号。我们公众号发文有两个目的:1 知识成系统,2 重点讲透彻。如果读者们有更多的意见,欢迎留言给我们。
参考文献:
《统计学习方法》 李航
https://www.cnblogs.com/ooon/p/5663975.html
https://towardsdatascience.com/boosting-algorithm-adaboost-b6737a9ee60c
Ensemble learning:https://en.wikipedia.org/wiki/Ensemble_learning
Boosting:https://en.wikipedia.org/wiki/Boosting_(machine_learning)
AdaBoost:https://en.wikipedia.org/wiki/AdaBoost
AdaBoost:https://baike.baidu.com/item/adaboost
AdaBoost原理详解: https://www.cnblogs.com/ScorpioLu/p/8295990.html
Multi-class AdaBoost:https://web.stanford.edu/~hastie/Papers/samme.pdf
https://blog.csdn.net/sun_shengyun/article/details/54289955
http://sklearn.apachecn.org/cn/0.19.0/modules/generated/sklearn.ensemble.AdaBoostRegressor.html#sklearn.ensemble.AdaBoostRegressor
好资料推荐:
https://github.com/purelyvivid/DeepLearning-MachineLearning_tutorial 很多关于算法的工程实践
