Druid具有高可用、高容错的特性。
本文将搭建一个简单的Druid集群,并且将会讨论如何进一步配置以满足您的需求。这个简单的集群只有Historical和MiddleManager采用高可用、高容错的方式搭建,coordination和Overlord都是单节点。在生产环境中,我们建议coordination、Overlord节点也都采用高可用、高容错的方式部署。
硬件选择
Coordinator和Overlord可以部署在一个配置一般的服务器上,负责管理元数据和集群的协调。亚马逊的m3.xlarge完全可以满足大部分的集群的硬件需求。硬件配置如下:
4 vCPUs
15 GB RAM
80 GB SSD storage
Historicals和MiddleManagers可以部署在相同的服务器上处理集群的数据。需要配置性能好一点CPU、内存和SSD(固态硬盘)的服务器,亚马逊的r3.2xlarge环境是一个不错的选择,硬件配置如下:
8 vCPUs
61 GB RAM
160 GB SSD storage
Broker节点需要接收查询请求并且把这些请求分发到集群空闲的节点。Broker可以在内存中缓存查询过的数据,所以Broker节点需要高性能的cpu和内存,亚马逊r3.2xlarge环境也可以部署,硬件配置如下:
8 vCPUs
61 GB RAM
160 GB SSD storage
非常大的集群应该考虑选择性能更好的服务器。
操作系统选择
使用自己习惯的Linux操作系统,要求jdk1.7集以上版本。
下载安装文件并解压
curl -Ohttp://static.druid.io/artifacts/releases/druid-0.9.0-bin.tar.gz
tar -xzf druid-0.9.0-bin.tar.gz
cddruid-0.9.0
解压之后的目录结构如下:
LICENSE-license文件
bin/-单机快速启动下的启动脚本
conf/*-集群模式下的配置文件目录
conf-quickstart/*-单机快速启动的配置文件目录
extensions/*-Druid扩展文件.
hadoop-dependencies/*-
Druid的Hadoop依赖
lib/*-
Druid引用的jar包
quickstart/*-单机快速启动的文件
需要配置conf目录下的配置文件。
配置”deepstorage”
Druid依赖一个分布式文件系统或者大对象存储系统,最常用的deep storage是S3(亚马逊云服务中比较流行使用)和HDFS(如果你已经部署了Hadoop)。
S3
在conf/druid/_common/common.runtime.properties文件中
设置druid.extensions.loadList=["druid-s3-extensions"].
配置"Deep Storage"和"Indexing service logs".的存储路径
注释部分是本地的存储路径,应该修改成如下所以的S3的路径
druid.extensions.loadList=["druid-s3-extensions"]
#druid.storage.type=local
#druid.storage.storageDirectory=var/druid/segments
druid.storage.type=s3
druid.storage.bucket=your-bucket
druid.storage.baseKey=druid/segments
druid.s3.accessKey=...
druid.s3.secretKey=...
#druid.indexer.logs.type=file
#druid.indexer.logs.directory=var/druid/indexing-logs
druid.indexer.logs.type=s3
druid.indexer.logs.s3Bucket=your-bucket
druid.indexer.logs.s3Prefix=druid/indexing-logs
HDFS
修改conf/druid/_common/common.runtime.properties,文件
设置druid.extensions.loadList=["io.druid.extensions:druid-hdfs-storage"].
配置"Deep Storage"和"Indexing service logs".的存储路径
注释部分是本地的存储路径,应该修改成如下所以的HDFS的路径
将Hadoop的配置文件core-site.xml, hdfs-site.xml, yarn-site.xml,
mapred-site.xml配置到Druid的classpath里,拷贝hadoop的配置文件到Druid的conf/druid/_common/文件夹下。
配置加载流式数据(选做)
数据流通过HTTP API的方式发送到Druid,如果使用此功能请参考如下链接对应的文档配置http://druid.io/docs/0.9.0/ingestion/stream-ingestion.html#server。
配置接入kafka数据(选做)
Druid以流的方式从kafka中持续的消费数据。如果使用此功能请参考如下链接对应的文档配置http://druid.io/docs/0.9.0/ingestion/stream-ingestion.html#kafka。
配置连接Hadoop(选做)
如果从Hadoop集群加载数据,应该配置Druid可以识别到Hadoop集群:
设置conf/middleManager/runtime.properties文件druid.indexer.task.hadoopWorkingPath属性为HDFS路径,因为在创建索引的过程中会产生临时文件存储到HDFS路径下。druid.indexer.task.hadoopWorkingPath=/tmp/druid-indexing是常用的配置方式。
把Hadoop中的xml配置文件配置到Druid的所有节点的classpath中,同时将Hadoop的这些配置文件拷贝到Druid每个节点的conf/druid/_common/目录下。
注意,不要为了从Hadoop加载数据到Druid而把HDFS作为Druid的deep storage,如果你的集群在亚马逊的Web服务中运行,即使是从Hadoop或者MapReduce加载数据,也可以将S3作为Druid的deep storage。
想了解更多的信息请参考如下链接http://druid.io/docs/0.9.0/ingestion/batch-ingestion.html。
为Druid的协调配置地址
在这个简单的集群部署例子中,在同一台服务器上配置了一个Coordinator,一个Overlord,一个Zookeeper实例,一个嵌入式Derby数据库用于存储元数据。
在conf/druid/_common/common.runtime.properties文件中将“zk.host.ip”替换为Zookeeper实例运行的IP地址:druid.zk.service.host
在conf/_common/common.runtime.properties文件中将"metadata.store.ip"替换为元数据存储的实例地址:
druid.metadata.storage.connector.connectURI
druid.metadata.storage.connector.host
注意:在生产环境中,我们推荐使用两台服务器,一台部署Coordinator一台部署Overlord,我们也推荐在独立的服务器上采用集群的模式部署Zookeeper服务,以及元数据存储服务器也在单独的服务器进行部署,比如数据库使用MySql、PostgreSQL等,并备份(参考地址:http://druid.io/docs/latest/dependencies/metadata-storage.html)。
设置Druid的服务请求
Historicals和MiddleManagers可以使用相同硬件配置,这两个组件的良好运行服务得益于好的硬件配置,如果有稳定的服务器或者kafka,也可以将Historicals和MiddleManagers运行在上面。如果使用的是r3.2xlarge EC2实例或者类似的硬件配置,这是一个不错的选择。
如果你使用不同的硬件,我们建议调整配置为你的特定硬件。最常用的调整配置是:
-Xmxand-Xms
druid.server.http.numThreads
druid.processing.buffer.sizeBytes
druid.processing.numThreads
druid.query.groupBy.maxIntermediateRows
druid.query.groupBy.maxResults
druid.server.maxSizeanddruid.segmentCache.locations(在Historical节点配置)
druid.worker.capacity(在MiddleManager节点配置)
注意:设置-XX:MaxDirectMemory >= numThreads*sizeBytes否则Druid会启动失败。
请参考完整的配置:http://druid.io/docs/0.9.0/configuration/index.html。
Broker配置
Borker良好运行服务得益于好的硬件配置,如果有稳定的服务器或者kafka,也可以将Historicals和MiddleManagers运行在上面。如果使用的是r3.2xlarge EC2实例或者类似的硬件配置,这是一个不错的选择。
如果你使用不同的硬件,我们建议调整配置为你的特定硬件。最常用的调整配置是:
-Xmxand-Xms
druid.server.http.numThreads
druid.cache.sizeInBytes
druid.processing.buffer.sizeBytes
druid.processing.numThreads
druid.query.groupBy.maxIntermediateRows
druid.query.groupBy.maxResults
注意:设置-XX:MaxDirectMemory >= numThreads*sizeBytes否则Druid会启动失败。
请参考完整的配置:http://druid.io/docs/0.9.0/configuration/index.html。
启动Coordinator,Overlord, Zookeeper,和metadata store
拷贝Druid的安装文件和配置好的Coordinator的配置文件,如果你已经在本地机器编辑好了配置文件,请使用rsync拷贝到Coordinator服务器。
rsync -az druid-0.9.0/
COORDINATION_SERVER:druid-0.9.0/
登录到coordination服务器安装Zookeeper
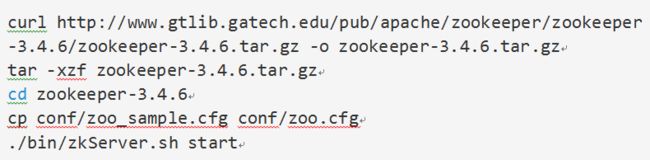
注意:在生产环境中推荐zookeeper采用单独的机器以集群模式部署。
在coordination服务器上进入到安装文件夹启动coordination服务。(应该在不同的窗口查看日志或者将日志输出到文件)
java`cat conf/druid/coordinator/jvm.config | xargs`-cp
conf/druid/_common:conf/druid/coordinator:lib/*io.druid.cli.Main server coordinator
java`cat conf/druid/overlord/jvm.config | xargs`-cp
conf/druid/_common:conf/druid/overlord:lib/*io.druid.cli.Main server overlord
启动的时候通过查看日志观察每个服务打印出的启动信息,在var/log/druid目录下可以查看所有服务的日志。
启动Historicals和MiddleManagers
拷贝安装文件及已经编辑好的Historicals和MiddleManagers的配置文件到部署服务器。通过如下的命令分别启动Historicals和MiddleManager:
java`cat conf/druid/historical/jvm.config | xargs`-cp
conf/druid/_common:conf/druid/historical:lib/*io.druid.cli.Main server historical
java`cat conf/druid/middleManager/jvm.config | xargs`-cp
conf/druid/_common:conf/druid/middleManager:lib/*io.druid.cli.Main server middleManager
你可以在更多的服务器上部署Historicals和MiddleManagers
如果集群有复杂的资源分配的需求,你可以将Historicals和MiddleManagers分离开,评估每个组件需要的资源单独部署,也可以使用Druid内置的自动缩放功能。
如果你是从kafka或者http数据流的方式加载数据,也可以使用相同的硬件部署Historicals和MiddleManagers,对于大规模的生产环境Historicals和MiddleManagers也可以部署到一起
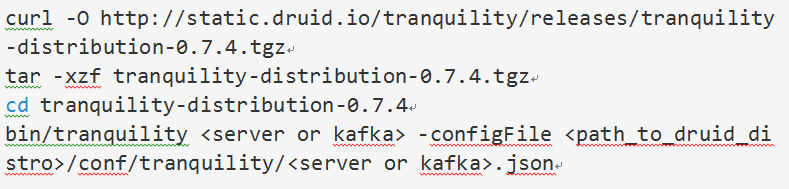
启动broker
拷贝安装文件及已经编辑好的brokers的配置文件到部署服务器。通过如下的命令启动broker
java`cat conf/druid/broker/jvm.config | xargs`-cp
conf/druid/_common:conf/druid/broker:lib/*io.druid.cli.Main server broker
为了降低查询的负载可以在多个服务器部署多个broker。
加载数据
恭喜你,现在已经部署成功了一个Druid集群,下一步就是将数据加载到Druid,更多关于加载数据到Druid的说明请参考http://druid.io/docs/0.9.0/tutorials/ingestion.html。