
【大数据教程】
一、Iptables教程
1. iptables防火墙简介
Iptables也叫netfilter是Linux下自带的一款免费且优秀的基于包过滤的防火墙工具,它的功能十分强大,使用非常灵活,可以对流入、流出、流经服务器的数据包进行精细的控制。iptables是Linux2.4及2.6内核中集成的模块。
2. Iptables服务相关命令
1.查看iptables状态
service iptables status
2.开启/关闭iptables
service iptables start
service iptables stop
3.查看iptables是否开机启动
chkconfig iptables --list
4.设置iptables开机启动/不启动
chkconfig iptables on
chkconfig iptables off
3. iptables原理简介
3.1. iptables的结构
在iptables中有四张表,分别是filter、nat、mangle和raw每一个表中都包含了各自不同的链,最常用的是filter表。
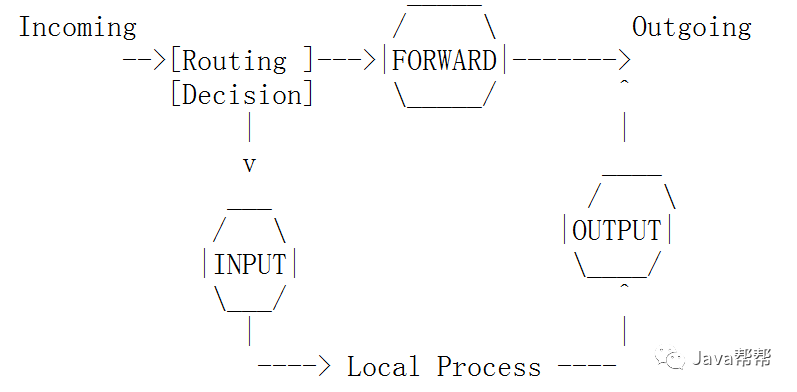
l filter表:
filter是iptables默认使用的表,负责对流入、流出本机的数据包进行过滤,该表中定义了3个链:
INPOUT 负责过滤所有目标地址是本机地址的数据包,就是过滤进入主机的数据包。
FORWARD 负责转发流经本机但不进入本机的数据包,起到转发的作用。
OUTPUT 负责处理所有源地址是本机地址的数据包,就是处理从主机发出去的数据包。
二、Redis3集群安装
1. 什么是Redis
Redis是目前一个非常优秀的key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set有序集合)和hash(哈希类型)。
2. 为什么要安装Redis3集群
Redis3.x支持集群模式,更加可靠!
3. 安装Redis3集群(6台Linux)
参考文章:http://blog.csdn.net/myrainblues/article/details/25881535
1.下载redis3的稳定版本,下载地址http://download.redis.io/releases/redis-3.0.7.tar.gz
2.上传redis-3.0.7.tar.gz到服务器
3.解压redis源码包
tar -zxvf redis-3.0.7.tar.gz -C /usr/local/src/
4.进入到源码包中,编译并安装redis
cd /usr/local/src/redis-3.0.7/
make && make install
5.报错,缺少依赖的包
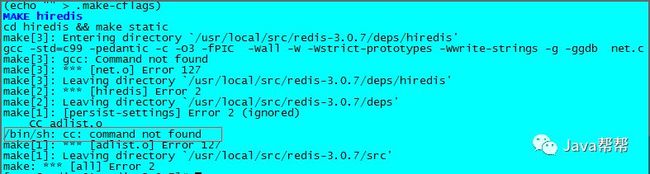
6.配置本地YUM源并安装redis依赖的rpm包
yum -y install gcc
7.编译并安装
make && make install
8.报错,原因是没有安装jemalloc内存分配器,可以安装jemalloc或直接输入
make MALLOC=libc && make install

9.重新编译安装
make MALLOC=libc && make install
10.用同样的方式在其他的机器上编译安装redis
11.在所有机器的/usr/local/下创建一个redis目录,然后拷贝redis自带的配置文件redis.conf到/usr/local/redis
mkdir /usr/local/redis
cp /usr/local/src/redis-3.0.7/redis.conf /usr/local/redis
12.修改所有机器的配置文件redis.conf
daemonize yes #redis后台运行
cluster-enabled yes #开启集群把注释去掉
appendonly yes #开启aof日志,它会每次写操作都记录一条日志
sed -i 's/daemonize no/daemonize yes/' /usr/local/redis/redis.conf
sed -i 's/# cluster-enabled yes/cluster-enabled yes/' /usr/local/redis/redis.conf
sed -i 's/appendonly no/appendonly yes/' /usr/local/redis/redis.conf
sed -i 's/# cluster-node-timeout 15000/cluster-node-timeout 5000/' /usr/local/redis/redis.conf
13.启动所有的redis节点
cd /usr/local/redis
redis-server redis.conf
14.查看redis进程状态
ps -ef | grep redis
15.配置集群:安装ruby和ruby gem工具(redis3集群配置需要ruby的gem工具,类似yum)
yum -y install ruby rubygems
(centos6.5的光盘可能缺失rubygems包,需要这样处理:
先安装yum -y install ruby,
再安装rubygems的依赖:
yum install -y ruby-irb
yum install -y ruby-rdoc
再用rpm命令安装rubygems包
rpm -ivh /root/rubygems-1.3.7-5.el6.noarch.rpm
)
16.使用gem下载redis集群的配置脚本
gem install redis
17.gem需要上网才能下载,由于安装redis的服务器可能无法访问外网,可以找一台可以上网的服务器执行下面的命令
yum -y install ruby rubygems
gem install redis
将下载好的redis gem(/usr/lib/ruby/gems/1.8/cache/redis-3.2.2.gem)拷贝到其他服务器
cd /usr/lib/ruby/gems/1.8/cache
for n in {2..6}; do scp redis-3.2.2.gem 192.168.0.3$n:$PWD; done
18.使用gem本地模式安装redis-3.2.2.gem
gem install --local /usr/lib/ruby/gems/1.8/cache/redis-3.2.2.gem
19.使用脚本配置redis集群(在一台机器上执行即可,想要把哪些节点配置成Master节点就放在后面)
cd /usr/local/src/redis-3.0.7/src/
service iptables stop
./redis-trib.rb create --replicas 1 192.168.0.34:6379 192.168.0.35:6379 192.168.0.36:6379 192.168.0.31:6379 192.168.0.32:6379 192.168.0.33:6379
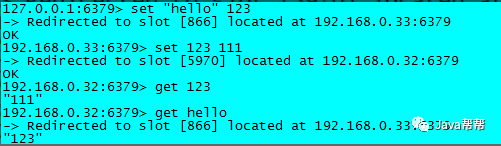
20.测试
redis-cli -c -p 6379
4. Redis3伪分布式安装(1台Linux)
1.下载redis3的稳定版本,下载地址http://download.redis.io/releases/redis-3.0.7.tar.gz
2.上传redis-3.0.7.tar.gz到服务器
3.解压redis源码包
tar -zxvf redis-3.0.7.tar.gz -C /usr/local/src/
4.进入到源码包中,编译并安装redis
cd /usr/local/src/redis-3.0.7/
make && make install
5.在/usr/local/下创建一个redis目录,然后分别在/usr/local/redis目录创建6个文件夹7000,7001,7002,7003,7004,7005然后拷贝redis自带的配置文件redis.conf到这六个目录中
mkdir /usr/local/redis
mkdir /usr/local/redis/{7000,7001,7002,7003,7004,7005}
cp /usr/local/src/redis-3.0.7/redis.conf /usr/local/redis/7000
cp /usr/local/src/redis-3.0.7/redis.conf /usr/local/redis/7001
cp /usr/local/src/redis-3.0.7/redis.conf /usr/local/redis/7002
cp /usr/local/src/redis-3.0.7/redis.conf /usr/local/redis/7003
cp /usr/local/src/redis-3.0.7/redis.conf /usr/local/redis/7004
cp /usr/local/src/redis-3.0.7/redis.conf /usr/local/redis/7005
6.分别修改这六个目录中的配置文件
port 7000 #端口要与其所在的文件名一致
pidfile /var/run/redis-7000.pid #pid要与其所在的文件名一致
daemonize yes
cluster-enabled yes
appendonly yes
7.分别进入到这六个目录启动redis进程
cd /usr/local/redis/7000
redis-server redis.conf
cd /usr/local/redis/7001
redis-server redis.conf
cd /usr/local/redis/7002
redis-server redis.conf
cd /usr/local/redis/7003
redis-server redis.conf
cd /usr/local/redis/7004
redis-server redis.conf
cd /usr/local/redis/7005
redis-server redis.conf
三、Nginx教程
1. Nginx相关概念
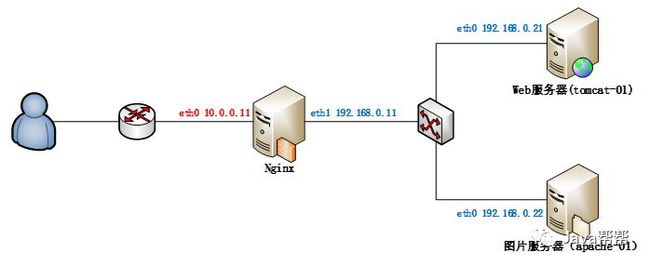
1.1. 反向代理
反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。
1.2. 负载均衡
负载均衡,英文名称为Load Balance,是指建立在现有网络结构之上,并提供了一种廉价有效透明的方法扩展网络设备和服务器的带宽、增加吞吐量、加强网络数据处理能力、提高网络的灵活性和可用性。其原理就是数据流量分摊到多个服务器上执行,减轻每台服务器的压力,多台服务器共同完成工作任务,从而提高了数据的吞吐量。
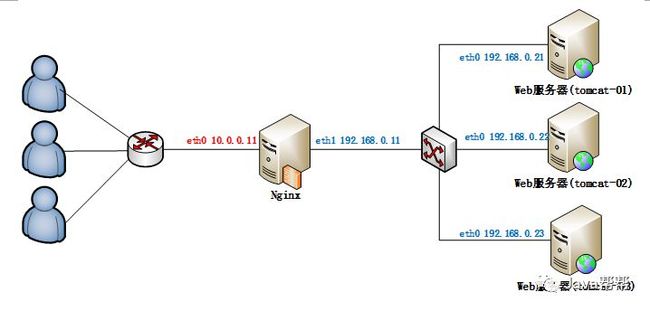
2. Nginx的安装
2.1. 下载nginx
官网:http://nginx.org/
2.2. 上传并解压nginx
tar -zxvf nginx-1.8.1.tar.gz -C /usr/local/src
2.3. 编译nginx
#进入到nginx源码目录
cd /usr/local/src/nginx-1.8.1
#检查安装环境,并指定将来要安装的路径
./configure --prefix=/usr/local/nginx
#缺包报错 ./configure: error: C compiler cc is not found
#使用YUM安装缺少的包
yum -y install gcc pcre-devel openssl openssl-devel
#编译安装
make && make install
安装完后测试是否正常:
/usr/loca/nginx/sbin/nginx
查看端口是否有ngnix进程监听
netstat -ntlp | grep 80
3. 配置nginx
3.1. 配置反向代理
1.修改nginx配置文件
server {
listen 80;
server_name nginx-01.itcast.cn; #nginx所在服务器的主机名
#反向代理的配置
location / { #拦截所有请求
root html;
proxy_pass http://192.168.0.21:8080;#这里是代理走向的目标服务器:tomcat
}
}
2.启动tomcat-01上的tomcat
3.启动nginx-01上的nginx
./nginx
重启:
kill -HUP `cat /usr/local/nginx/logs/nginx.pid `
参考网址:http://www.cnblogs.com/jianxie/p/3990377.html
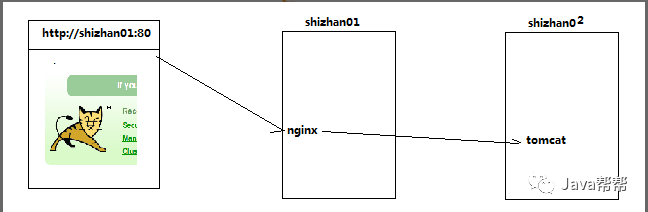
3.2. 动静分离
#动态资源 index.jsp
location ~ .*\.(jsp|do|action)$ {
proxy_pass http://tomcat-01.itcast.cn:8080;
}
#静态资源
location ~ .*\.(html|js|css|gif|jpg|jpeg|png)$ {
expires 3d;
}
3.3. 负载均衡
在http这个节下面配置一个叫upstream的,后面的名字可以随意取,但是要和location下的proxy_pass http://后的保持一致。
http {
是在http里面的, 已有http, 不是在server里,在server外面
upstream tomcats {
server shizhan02:8080 weight=1;#weight表示多少个
server shizhan03:8080 weight=1;
server shizhan04:8080 weight=1;
}
#卸载server里
location ~ .*\.(jsp|do|action) {
proxy_pass http://tomcats;#tomcats是后面的tomcat服务器组的逻辑组号
}
}
4. 利用keepalived实现高可靠(HA)
4.1. 高可靠概念
HA(High Available), 高可用性集群,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点。
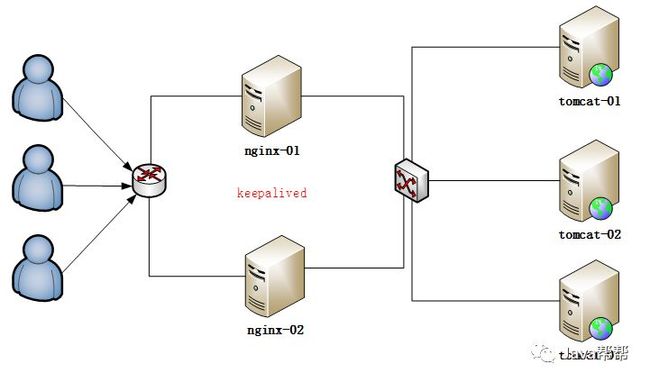
4.2. 高可靠软件keepalived
keepalive是一款可以实现高可靠的软件,通常部署在2台服务器上,分为一主一备。Keepalived可以对本机上的进程进行检测,一旦Master检测出某个进程出现问题,将自己切换成Backup状态,然后通知另外一个节点切换成Master状态。
4.3. keepalived安装
下载keepalived官网:http://keepalived.org
将keepalived解压到/usr/local/src目录下
tar -zxvf keepalived-1.2.19.tar.gz -C /usr/local/src
进入到/usr/local/src/keepalived-1.2.19目录
cd /usr/local/src/keepalived-1.2.19
开始configure
./configure --prefix=/usr/local/keepalived
#编译并安装
make && make install
4.4. 将keepalived添加到系统服务中
拷贝执行文件
cp /usr/local/keepalived/sbin/keepalived /usr/sbin/
将init.d文件拷贝到etc下,加入开机启动项
cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/keepalived
将keepalived文件拷贝到etc下
cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
创建keepalived文件夹
mkdir -p /etc/keepalived
将keepalived配置文件拷贝到etc下
cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf
添加可执行权限
chmod +x/etc/init.d/keepalived
##以上所有命令一次性执行:
cp /usr/local/keepalived/sbin/keepalived /usr/sbin/
cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/keepalived
cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
mkdir -p /etc/keepalived
cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf
chmod +x /etc/init.d/keepalived
chkconfig --add keepalived
chkconfig keepalived on
添加keepalived到开机启动
chkconfig --add keepalived
chkconfig keepalived on
4.5. 配置keepalived虚拟IP
修改配置文件: /etc/keepalived/keepalived.conf
#MASTER节点
global_defs {
}
vrrp_instance VI_1 {
state MASTER #指定A节点为主节点 备用节点上设置为BACKUP即可
interface eth0 #绑定虚拟IP的网络接口
virtual_router_id 51 #VRRP组名,两个节点的设置必须一样,以指明各个节点属于同一VRRP组
priority 100 #主节点的优先级(1-254之间),备用节点必须比主节点优先级低
advert_int 1#组播信息发送间隔,两个节点设置必须一样
authentication { #设置验证信息,两个节点必须一致
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { #指定虚拟IP, 两个节点设置必须一样
192.168.33.60/24 #如果两个nginx的ip分别是192.168.33.61,,...62,则此处的虚拟ip跟它俩同一个网段即可
}
}
#BACKUP节点
global_defs {
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.33.60/24
}
}
#分别启动两台机器上的keepalived
service keepalived start
测试:
杀掉master上的keepalived进程,你会发现,在slave机器上的eth0网卡多了一个ip地址
查看ip地址的命令: ip addr
4.6. 配置keepalived心跳检查
原理:
Keepalived并不跟nginx耦合,它俩完全不是一家人
但是keepalived提供一个机制:让用户自定义一个shell脚本去检测用户自己的程序,返回状态给keepalived就可以了
#MASTER节点
global_defs {
}
vrrp_script chk_health {
script "[[ `ps -ef | grep nginx | grep -v grep | wc -l` -ge 2 ]] && exit 0 || exit 1"
interval 1 #每隔1秒执行上述的脚本,去检查用户的程序ngnix
weight -2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 1
priority 100
advert_int 2
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_health
}
virtual_ipaddress {
10.0.0.10/24
}
notify_master "/usr/local/keepalived/sbin/notify.sh master"
notify_backup "/usr/local/keepalived/sbin/notify.sh backup"
notify_fault "/usr/local/keepalived/sbin/notify.sh fault"
}
#添加切换通知脚本
vi /usr/local/keepalived/sbin/notify.sh
#!/bin/bash
case "$1" in
master)
/usr/local/nginx/sbin/nginx
exit 0
;;
backup)
/usr/local/nginx/sbin/nginx -s stop
/usr/local/nginx/sbin/nginx
exit 0
;;
fault)
/usr/local/nginx/sbin/nginx -s stop
exit 0
;;
*)
echo 'Usage: notify.sh {master|backup|fault}'
exit 1
;;
esac
#添加执行权限
chmod +x /usr/local/keepalived/sbin/notify.sh
global_defs {
}
vrrp_script chk_health {
script "[[ `ps -ef | grep nginx | grep -v grep | wc -l` -ge 2 ]] && exit 0 || exit 1"
interval 1
weight -2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 1
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_health
}
virtual_ipaddress {
10.0.0.10/24
}
notify_master "/usr/local/keepalived/sbin/notify.sh master"
notify_backup "/usr/local/keepalived/sbin/notify.sh backup"
notify_fault "/usr/local/keepalived/sbin/notify.sh fault"
}
#在第二台机器上添加notify.sh脚本
#分别在两台机器上启动keepalived
service keepalived start
chkconfig keepalived on
Linux shell编程
1.什么是shell
Shell是用户与内核进行交互操作的一种接口,目前最流行的Shell称为bash Shell
Shell也是一门编程语言<解释型的编程语言>,即shell脚本
一个系统可以存在多个shell,可以通过cat /etc/shells命令查看系统中安装的shell,不同的shell可能支持的命令语法是不相同的
2.shell脚本的执行方法
第一种:输入脚本的绝对路径或相对路径
首先要赋予+x权限
/root/helloWorld.sh
./helloWorld.sh
或者,不用赋予+x权限,而用解释器解释执行
sh helloworld.sh
第二种:bash或sh +脚本
sh /root/helloWorld.sh
sh helloWorld.sh
第三种:在脚本的路径前再加". "
. /root/helloWorld.sh
. ./helloWorld.sh
区别:第一种和第二种会新开一个bash,不同bash中的变量无法共享
3.shell中的变量
Linux Shell中的变量分为“系统变量”和“用户自定义变量”,可以通过set命令查看那系统变量
系统变量:$HOME、$PWD、$SHELL、$USER等等
显示当前shell中所有变量 : set
4.定义变量
变量=值 (例如STR=abc)
等号两侧不能有空格
变量名称一般习惯为大写
双引号和单引号有区别,双引号仅将空格脱意,单引号会将所有特殊字符脱意
STR="hello world"
A=9
unset A 撤销变量 A
readonly B=2 声明静态的变量 B=2 ,不能 unset
export 变量名 可把变量提升为全局环境变量,可供其他shell程序使用
5.将命令的返回值赋给变量
A=`ls -la` 反引号,运行里面的命令,并把结果返回给变量A
A=$(ls -la) 等价于反引号
6.shell中特殊变量
$? 表示上一个命令退出的状态
$$ 表示当前进程编号
$0 表示当前脚本名称
$n 表示n位置的输入参数(n代表数字,n>=1)
$# 表示参数的个数,常用于循环
$*和$@ 都表示参数列表
7.$与$@的区别
$* 和 $@ 都表示传递给函数或脚本的所有参数,不被双引号" "包含时,都以$1 $2 … $n 的形式输出所有参数
当它们被双引号" "包含时,"$*" 会将所有的参数作为一个整体,以"$1 $2 … $n"的形式输出所有参数;"$@" 会将各个参数分开,以"$1" "$2" … "$n" 的形式输出所有参数
8.shell中的运算法
格式 :expr m + n 或$((m+n)) 注意expr运算符间要有空格
例如计算(2 +3 )×4 的值
1 .分步计算 S=`expr 2 + 3` expr $S \* 4
2.一步完成计算
expr `expr 2 + 3 ` \* 4
echo `expr \`expr 2 + 3\` \* 4`
或
$(((2+3)*4))
9.shell中for循环
第一种:
for N in 1 2 3
do
echo $N
done
或
for N in 1 2 3; do echo $N; done
或
for N in {1..3}; do echo $N; done
第二种:
for ((i = 0; i <= 5; i++))
do
echo "welcome $i times"
done
或
for ((i = 0; i <= 5; i++)); do echo "welcome $i times"; done
10.shell中的while循环
第一种
while expression
do
command
…
done
第二种
i=1
while ((i<=3))
do
echo $i
let i++
done
11.shell中的case语句
格式
case $1 in
start)
echo "starting"
;;
stop)
echo "stoping"
;;
*)
echo "Usage: {start|stop} “
esac
12.shell中的read命令
read -p(提示语句)-n(字符个数) -t(等待时间)
read -p "please input your name: " NAME
使用示例:

13.shell中的if判断

14.if例子
#!/bin/bash
read -p "please input your name:" NAME
#printf '%s\n' $NAME
if [ $NAME = root ]
then
echo "hello ${NAME}, welcome !"
elif [ $NAME = itcast ]
then
echo "hello ${NAME}, welcome !"
else
echo "SB, get out here !"
fi
15.判断语句
[ condition ] (注意condition前后要有空格)
#非空返回true,可使用$?验证(0为true,>1为false)
[ itcast ]
#空返回false
[ ]
[ condition ] && echo OK || echo notok
条件满足,执行后面的语句
16.常用判断条件
= 字符串比较
-lt 小于
-le 小于等于
-eq 等于
-gt 大于
-ge 大于等于
-ne 不等于
-r 有读的权限
-w 有写的权限
-x 有执行的权限
-f 文件存在并且是一个常规的文件
-s 文件存在且不为空
-d 文件存在并是一个目录
-b文件存在并且是一个块设备
-L 文件存在并且是一个链接
17.shell自定义函数
语法
[ function ] funname [()]
{
action;
[return int;]
}
function start() / function start / start()
注意
1.必须在调用函数地方之前,先声明函数,shell脚本是逐行运行。不会像其它语言一样先预编译
2.函数返回值,只能通过$? 系统变量获得,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值。 return后跟数值n(0-255)
18.脚本调试
sh -vx helloWorld.sh
或者在脚本中增加set -x
19.sed命令
sed全称是:Stream EDitor即流编辑器,是一个很好的文本处理工具,本身是一个管道命令,处理时,把当前处理的行存储在临时缓冲区中,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行。它是以行为单位进行处理,可以将数据行进行替换、删除、新增、选取等特定工作。
20.sed选项
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令列模式上进行 sed 的动作编辑;
-i :直接修改读取的文件内容,而不是输出到终端。
21.sed function
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)
d :删除,因为是删除啊,所以 d 后面通常不接任何内容
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行)
p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行
s :取代,可以直接进行取代的工作!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g
22.awk命令
AWK是一种优良的文本处理工具。其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母,AWK 提供了极其强大的功能:可以进行样式装入、流控制、数学运算符、进程控制语句甚至于内置的变量和函数。它具备了一个完整的语言所应具有的几乎所有精美特性。实际上 AWK 的确拥有自己的语言:AWK 程序设计语言, 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
命令格式:
awk 'pattern1 {action1} pattern2 {action2} ...' filename
