回想我们在银行和政府机关去办事时, 都会有一个排队机, 先取一个号, 然后等待叫号, 办事窗口多, 号就叫得快, 办事窗口少, 号就叫得慢, 排队机是一个了不起的发明, 这里有许多值得我们在编程时借鉴的东西。

- 它其实应用了 leader/follower 的并发模式, 每个办事窗口就是一个工作线程, 由排号机这个 leader 来分配工作
- 它其实应用了限流模式, 用排号限制了任务的拥塞,再多的人来银行办事, 银行也能 hold 得住, 大不了广而告之, 今天的号发完了, 明天请早
- 它其实是一个消息队列系统
- 它其实是一个事件驱动系统
- 它其实就是一个排队机
闲言少叙, 书归正传, 我们来重点讲讲限流这回事, 任何系统都有容量的限制, 为了使我们的服务保持高可用性, 我们必须对系统进行限流, 也称速率限制 Rate Limiting
限流和流量控制也还有点区别,在传输层协议层面上就已经做了一些流量控制, TCP 通过可变大小的滑动窗口来进行数据传输的流量控制,简单来说, 发送方有一个滑动窗口, 大小为10, 也就是说发送10个字节之后才等待接收方的响应, 接收方在接收确认消息中包含一个 window advertisement 窗口建议告之发送方 -- 作为接收方准备好接收多少字节的数据, 这个值如果比较大,那么发送方的滑动窗口可以增大 , 可以快点发送数据, 因为接收方的处理效率很高, 反之, 则减小滑动窗口大小, 这样就减慢了发送速率, 当滑动窗口大小为1时, 则发送每个消息都要等待确认消息收到后才发送下一个
大多数的消息队列系统也用到了 Flow Control , 当生产者过快地发送消息, 而消费者没法及时处理时,并返回一个异常消息,告之生产者搞慢点 -- “马儿你慢点走慢点走吔”
而这里讲的限流是指速率控制, 服务器端对客户端的请求进行监控,当发觉某个客户端发送了过多或过快的请求就会做出限制, 根据预先制定的策略针对某个客户端的IP, 帐户或类型进行限流, 从而保证了对大多数正常请求的服务不受影响, 防止拒绝服务 DoS (denial of service) 和分布式拒绝服务 DDoS (distributed denial of service) , DoS 是很常见的网络攻击方式, 限流或者说速率控制 Rate Limiting 是行之有效的应对手段.
限流可以是比较粗放式的, 只根据每秒请求数的阈值来进行控制, 超过 QPS/TPS 上限的请求一律拒绝掉, 这种方式 有效, 但是不能精准打击那些攻击者, 反而会误伤无辜.
我们可以缩小限制范围, 按照如下三个级别来作区别对待
- 源地址层面 Source Address Level
我们从 HTTP 请求中都可以得到 TCP 头中的 source address, 如果来自一个源地址的请求过多过快, 可以将它超过阈值的请求拒绝掉, 其他来源的合法请求不做限制.
这里要着重注意一点, 用户的请求一般不会直接到达服务器, 而是会经过一个负载均衡器 Load Balancer 分流后到达服务器, 所以这个源地址很可能就变成了 Load Balancer 的地址, 所以我们最好先检查一下在 HTTP 头域中是否有 X-Forwarded-For , 这是由负载均衡器所添加的来自客户端的真实地址, 意谓转发自何处.
众多的 HTTP 代理服务器, 也会添加这个 HTTP 头域, 如果有这个头域, 那么就应该以它作为客户端的IP 加以区分, 无论是硬件的 F5, Netscalar, 还是软件版本的 Nginx, HAProxy 都支持这一选项.
- 用户层面 User level
微服务对外提供的 API , 首先需要通过认证 Authentication 和授权 Authorization, 一旦认证和授权通过, 我们就能得知这个请求所代表的用户信息, 针对这个信息, 可以做基于用户分组的限流.
例如, 我们在服务器签发的 token 中包含用户信息: userId, orgId, 然后就可以针对 userId 或 orgId 做单独的计数, 如果在特定时间单位中超过最大数量阈值, 则拒绝此特定用户或组织的请求. 实际应用中就可以在 JWT(Json Web Token) 中添加自定义字段来表示用户, 组织及应用程序的标识信息.
- 应用程序层面 Application Level
类似用户层面的限流, 一旦我们可以辨别出应用程序的标识, 就可以针对特定应用程序的请求进行计数, 按照下面介绍的限流算法来进行速率控制.
限流算法
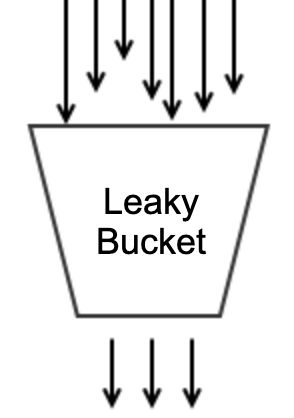
Leaky Bucket 漏桶
就象我们生活中常见的漏斗, 从油桶往油瓶里倒油, 没有漏斗, 除非是卖油翁那样的专家, 多数情况下油都会跑冒滴漏.

漏桶是类似的东西, 海量请求扑面而来, 可能瞬时就会把服务压垮, 而漏桶就可以用来限流削峰.
漏桶是总容量是不变的, 水滴(请求) 以任意速率流入, 但总是以恒定速率流出, 如果请求来得太多太快, 桶的容量就会撑满, 后续的请求就会被拒绝, 也就是说当一个请求到来, 就流一滴水进桶里,如果可以放入, 则处理此请求, 否则漏桶已满, 则拒绝此请求, 直到桶中水滴不再满时
Token Bucket 令牌桶
令牌桶与上而的漏桶异曲同工, 只不过它不是以固定速率流出, 而是以固定速率放入令牌到令牌桶中, 请求到来时从令牌桶中领取一个令牌才可继续处理服务, 如果取不到令牌, 则拒绝此请求

Fixed Window 固定窗口
固定窗口算法, 也就是用一个固定的时间窗口来跟踪速率, 每一个请求会增加这个窗口中的计数器, 请求来了加1, 处理完成就会减1, 如果这个计数器超过了阈值, 后续的请求就会丢弃掉.
比如60秒的窗口设置阈值为1200, 12:00 ~ 12:01 就是一个窗口, 在这个窗口期中的请求数超过了1200, 再进来的请求就会丢弃掉.

Sliding Log 滑动日志
以时间戳为 key 将请求日志保存在一张表中, 每个请求都会在这张表中添加一条日志, 日志的生存周期(TTL - Time To Live)有限, 过期的日志会被删除, 如果表中所存储的日志数已经达到了阈值, 后续的新请求就会丢弃掉

Sliding Window 滑动窗口
这是一种改进算法, 综合了固定窗口和滑动日志两种方法的优点,它结合了固定窗口算法的低处理成本和滑动日志的改进边界条件, 将当前时间窗口与过去时间窗口综合考虑。 与固定窗口算法一样,根据请求更改每个固定窗口的计数器。 接下来,再根据当前时间戳计算出当前窗口的加权值, 以及上一个窗口的请求率的加权值,以平滑流量突发。 例如,如果当前窗口是25%,那么我们将前一个窗口的计数加权75%。

限流级别
其实就是计数器涵盖的范围, 通过实例级别也就够了, 单个实例超过流量了, 由于前面都有一个负载均衡器存在, 其他实例大概率也会过载.
大致我们可以分为在下四个级别
实例级别 Instance
服务器级别 Servrer
集群级别 Pool/Cluster
数据中心 Data center
限流范围
具体到限制范围, 根据上述的三个层面, 源地址, 用户, 应用程序, 还可以加上微服务自身所提供的不同端点来划分范围
- 全部端点 all endpoints/特定端点 specified endpoint
- 全部源地址/特定源地址
- 全部用户/特定用户
- 全部应用程序/特定应用程序
限流策略
最简单的策略当然是直接拒绝, 简单粗暴有效, 但是如果想做得比较平滑优雅, 可以部分拒绝, 逐步收窄, 对于那些十分重要的大客户, 可没有额外资源可以调度的情况, 甚至可以设置为永不拒绝策略
- 全部拒绝
- 部分拒绝: 在指定时间间隔内允许若干个请求 QPS, QPM, QPH
- 总不拒绝: 对于某些非常重要的客户, 总是允许他们的请求, 直至系统资源耗尽
例如在 HTTP 请求拒绝的时候我们可以用响应码 "429 Too Many Requests", 还可加上一个 Retry-After 来建议用户多长时间以后再重试.

限流度量及触发条件
根据上述算法, 关键的度量指标就是计数器
- 漏桶中的水滴数是否已经达到阈值
- 令牌桶中的令牌数是否已经领光
- 固定窗口或滑动窗口中的计数器是否已经达到阈值
- 滑动日志中所存储的日志数是否已经达到阈值
当然可以设置更加细致的匹配和分组条件:
例如
- API 端点信息: url, responseCode, header, method, param
- 用户信息: userId, orgId
- ip 地址信息: source_address, x-forwarded-for
触发条件一般是单位时间内的最大请求数, 例如:
- 单位时间内的请求数 request count per interval
- 单位时间内的错误码次数 error code count per interval
- 单位时间内的并发请求数 concurrent request per interval
实例演示
对于实例级别的限流, 在内存中维护一个漏桶, 令牌桶, 或者计数器就好了
内存计数器
public interface RateLimiter {
boolean allow();
}
package com.github.walterfan.util.ratelimit;
import com.google.common.util.concurrent.Uninterruptibles;
import lombok.extern.slf4j.Slf4j;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
@Slf4j
public class FixedWindow implements RateLimiter {
private final ConcurrentMap windows = new ConcurrentHashMap<>();
private int maxRequestsPerSecond;
private int windowSizeInMs;
public FixedWindow(int maxReqPerSec, int windowSizeInMs) {
this.maxRequestsPerSecond = maxReqPerSec;
this.windowSizeInMs = windowSizeInMs;
}
@Override
public boolean allow() {
long windowKey = System.currentTimeMillis() / windowSizeInMs;
windows.putIfAbsent(windowKey, new AtomicInteger(0));
//log.debug("counter of {} --> {}", windowKey, windows.get(windowKey));
return windows.get(windowKey).incrementAndGet() <= maxRequestsPerSecond;
}
public String toString() {
StringBuilder sb = new StringBuilder("");
for(Map.Entry entry: windows.entrySet()) {
sb.append(entry.getKey());
sb.append(" --> ");
sb.append(entry.getValue());
sb.append("\n");
}
return sb.toString();
}
public static void main(String[] args) {
FixedWindow fixedWindow = new FixedWindow(10, 1000);
for(int i=0;i<20;i++) {
boolean ret = fixedWindow.allow();
Uninterruptibles.sleepUninterruptibly(50, TimeUnit.MILLISECONDS);
if(!ret)
log.info("{}, ret={}", i, ret);
}
log.info(fixedWindow.toString());
}
}
}
执行结果如下
10, ret=false
11, ret=false
12, ret=false
13, ret=false
14, ret=false
15, ret=false
1558961918 --> 4
1558961917 --> 16
Guava Ratelimiter
Guava 也提供了一个 Rate Limiter 的简单实现

使用方法
final RateLimiter rateLimiter = RateLimiter.create(2.0); // 允许每秒2.0 个请求 Call Per Second
void submitTasks(List tasks, Executor executor) {
for (Runnable task : tasks) {
// 这里会阻塞直至请求数不再达到阈值 2 CPS,
// 如果不想阻塞, 可使用 tryAcquire(int permits, long timeout, TimeUnit unit)
rateLimiter.acquire();
executor.execute(task);
}
}
Redis 计数器
对于集群级别的限流, 可以利用 Redis 来存储计算器, 比如我们想对某一个API 进行限流, 阈值为 100 CPS
在Redis 存储一张哈希表, key 名为 counter_
例如
set counter_check_health_cps:1558962905 1
"OK"
INCRBY counter_check_health_cps:1558962905 1
2
Zuul Route Filter
Spring Cloud 的开源网关项目 Zuul , 它基于过滤器模式提供若干过滤器的实现, 对于 Rate Limit 的也有一个开源的实现
org.springframework.cloud
spring-cloud-starter-netflix-zuul
com.marcosbarbero.cloud
spring-cloud-zuul-ratelimit
2.2.0.RELEASE
对于以下 /potato/health API
@Controller
@RequestMapping("/potato")
public class GreetingController {
@GetMapping("/health")
public ResponseEntity getSimple() {
return ResponseEntity.ok("OKOKOK");
}
}
可以设置 Zuul 针对 CheckHealth的速率控制为 5 CPS(Call Per Second)
zuul:
routes:
checkHealth:
path: /potato/health
url: forward:/
ratelimit:
enabled: true
repository: JPA
policy-list:
checkHealth:
- limit: 5
refresh-interval: 60
type:
- origin
strip-prefix: true
参考资料
- https://konghq.com/blog/how-to-design-a-scalable-rate-limiting-algorithm/
- https://hechao.li/2018/06/25/Rate-Limiter-Part1/
- https://github.com/marcosbarbero/spring-cloud-zuul-ratelimit
- https://www.baeldung.com/spring-cloud-zuul-rate-limit