1 搭建ES集群
集群的说明
我们计划集群名称为:leyou-elastic,部署3个elasticsearch节点,分别是:
node-01:http端口9201,TCP端口9301
node-02:http端口9202,TCP端口9302
node-03:http端口9203,TCP端口9303
第一步:直接复制前天准备好的ES,但是复制之前一定要把之前的数据清理
清理的方式就是 删除data文件夹
第二步:复制完后文件夹改名为
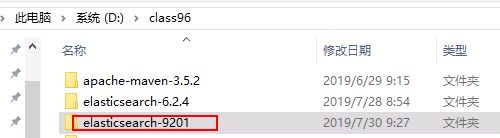
第三步:修改配置文件elasticsearch.yml
内容为:
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 127.0.0.1
# 集群的名称
cluster.name: leyou-elastic
#当前节点名称 每个节点不一样
node.name: node-01
#数据的存放路径 每个节点不一样
path.data: d:\class96\elasticsearch-9201\data
#日志的存放路径 每个节点不一样
path.logs: d:\class96\elasticsearch-9201\log
# http协议的对外端口 每个节点不一样
http.port: 9201
# TCP协议对外端口 每个节点不一样
transport.tcp.port: 9301
#三个节点相互发现
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#声明大于几个的投票主节点有效,请设置为(nodes / 2) + 1
discovery.zen.minimum_master_nodes: 2
# 是否为主节点
node.master: true
修改完成后使用utf-8的方式另存为一下,不然不认中文
第四步:再复制两份,总共三份,修改按照上述配置文件修改

第五步:分别启动三个ES
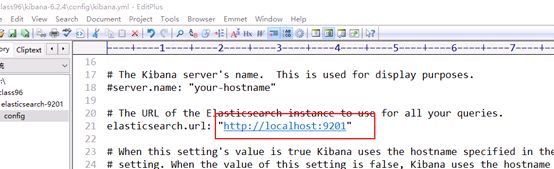
第六步:修改kibana指向的ES集群,然后启动
这里指向9201 9202 9303是没有区别的
第七步:使用elasticsearch-head插件可以看集群的情况

2 使用kibana操作
指定索引库的分片数量和副本数,默认分片5,副本数是1
put heima
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
}
}
使用head插件查看

原生的API
RestAPI
SpringDataElasticSearch方式
3 RestAPI操作ES
1.1 使用kibana创建一个索引库
PUT /item
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
},
"mappings": {
"docs": {
"properties": {
"id": {
"type": "keyword"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"category": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"images": {
"type": "keyword",
"index": false
},
"price": {
"type": "double"
}
}
}
}
}
1.2 创建maven项目
第一步:创建maven项目
第二步:导入依赖
1.3 代码操作
1.3.1 初始化client
private RestHighLevelClient client = null;
private Gson gson = new Gson();
@Before
public void init(){
client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9201, "http"),
new HttpHost("localhost", 9202, "http"),
new HttpHost("localhost", 9203, "http")));
}
1.3.2 添加文档数据
准备一个pojo类
@Data
@AllArgsConstructor //全参构造方法
@NoArgsConstructor //无参构造方法
public class Item implements Serializable{
private Long id;
private String title; //标题
private String category;// 分类
private String brand; // 品牌
private Double price; // 价格
private String images; // 图片地址
}
// 新增或修改 IndexRequest
Item item = new Item(1L,"大米6X手机","手机","小米",1199.0,"http.jpg");
String jsonStr = gson.toJson(item);
IndexRequest request = new IndexRequest("item","docs",item.getId().toString());
request.source(jsonStr, XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);
1.3.3 修改文档数据
就是使用上面的新增方法,它既是新增也是修改
1.3.4 根据id获取文档数据
GetRequest request = new GetRequest("item","docs","1");
GetResponse getResponse = client.get(request, RequestOptions.DEFAULT);
String sourceAsString = getResponse.getSourceAsString();
Item item = gson.fromJson(sourceAsString, Item.class);
System.out.println(item);
1.3.5 删除文档数据
DeleteRequest deleteRequest = new DeleteRequest("item","docs","1");
client.delete(deleteRequest,RequestOptions.DEFAULT);
1.3.6 批量新增文档数据
// 准备文档数据:
List
list.add(new Item(1L, "小米手机7", "手机", "小米", 3299.00,"http://image.leyou.com/13123.jpg"));
list.add(new Item(2L, "坚果手机R1", "手机", "锤子", 3699.00,"http://image.leyou.com/13123.jpg"));
list.add(new Item(3L, "华为META10", "手机", "华为", 4499.00,"http://image.leyou.com/13123.jpg"));
list.add(new Item(4L, "小米Mix2S", "手机", "小米", 4299.00,"http://image.leyou.com/13123.jpg"));
list.add(new Item(5L, "荣耀V10", "手机", "华为", 2799.00,"http://image.leyou.com/13123.jpg"));
BulkRequest bulkRequest = new BulkRequest();
for (Item item : list) {
bulkRequest.add(new IndexRequest("item","docs",item.getId().toString()).source(JSON.toJSONString(item),XContentType.JSON)) ;
}
client.bulk(bulkRequest,RequestOptions.DEFAULT);
1.3.7 各种查询
@Test
public void testQuery() throws Exception{
SearchRequest searchRequest = new SearchRequest("item");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.query(QueryBuilders.termQuery("title","小米"));
searchSourceBuilder.query(QueryBuilders.matchQuery("title","小米手机"));
searchSourceBuilder.query(QueryBuilders.fuzzyQuery("title","大米").fuzziness(Fuzziness.ONE));
searchSourceBuilder.query(QueryBuilders.rangeQuery("price").gte(3000).lte(4000));
searchSourceBuilder.query(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("title","手机"))
.must(QueryBuilders.rangeQuery("price").gte(3000).lte(3500)));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
long total = searchHits.getTotalHits();
System.out.println("总记录数:"+total);
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
Item item = JSON.parseObject(sourceAsString, Item.class);
System.out.println(item);
}
}
1.3.8 过滤
1、属性字段显示的过滤
searchSourceBuilder.fetchSource(new String[]{"title","category"},null);
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
2、查询结果的过滤
searchSourceBuilder.query(QueryBuilders.termQuery("title","手机"));
searchSourceBuilder.postFilter(QueryBuilders.termQuery("brand","小米"));
1.3.9 分页
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.from(0); //起始位置
searchSourceBuilder.size(3); //每页显示条数
1.3.10 排序
searchSourceBuilder.sort("id", SortOrder.ASC); // 参数1:排序的域名 参数2:顺序
1.3.11 高亮
构建高亮的条件
searchSourceBuilder.query(QueryBuilders.termQuery("title","小米"));
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("");
highlightBuilder.postTags("");
highlightBuilder.field("title");
searchSourceBuilder.highlighter(highlightBuilder);
解析高亮的结果
for (SearchHit hit : hits) {
Map
HighlightField highlightField = highlightFields.get("title");
String title = highlightField.getFragments()[0].toString();
String sourceAsString = hit.getSourceAsString();
Item item = JSON.parseObject(sourceAsString, Item.class);
item.setTitle(title);
System.out.println(item);
}
1.3.12 聚合
需求:根据品牌统计数量
构建的条件代码
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.aggregation(AggregationBuilders.terms("brandAvg").field("brand"));
解析结果:
Aggregations aggregations = searchResponse.getAggregations();
Terms terms = aggregations.get("brandAvg");
Listextends Terms.Bucket> buckets = terms.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString()+":"+bucket.getDocCount());
}
4 SpringDataElasticSearch框架的使用
1.4 准备环境
1、添加依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
2、创建引导类
@SpringBootApplication
public class EsApplication {
public static void main(String[] args) {
SpringApplication.run(EsApplication.class,args);
}
}
3、添加配置文件 application.yml
spring:
data:
elasticsearch:
cluster-name: leyou-elastic
cluster-nodes: 127.0.0.1:9301,127.0.0.1:9302,127.0.0.1:9303
4、创建一个测试类,注入SDE提供的一个模板
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataEsManager {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
}
Kibana:http
原始的api:tcp
RestAPI:http
Sde: tcp
1.5 操作索引库和映射
第一步:准备一个pojo,并且构建和索引的映射关系
@Data
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName="leyou",type = "goods",shards = 3,replicas = 1)
public class Goods implements Serializable{
@Field(type = FieldType.Long)
private Long id;
@Field(type = FieldType.Text,analyzer = "ik_max_word",store = true)
private String title; //标题
@Field(type = FieldType.Keyword,index = true,store = true)
private String category;// 分类
@Field(type = FieldType.Keyword,index = true,store = true)
private String brand; // 品牌
@Field(type = FieldType.Double,index = true,store = true)
private Double price; // 价格
@Field(type = FieldType.Keyword,index = false,store = true)
private String images; // 图片地址
}
第二步:创建索引库和映射
@Test
public void addIndexAndMapping(){
// elasticsearchTemplate.createIndex(Goods.class); //根据pojo中的注解创建索引库
elasticsearchTemplate.putMapping(Goods.class); //根据pojo中的注解创建映射
}
1.6 操作文档
// 新增或修改
// Goods goods = new Goods(1L,"大米6X手机","手机","小米",1199.0,"http.jpg");
// goodsRespository.save(goods); //save or update
// 根据id查询
// Optional
// Goods goods = optional.get();
// System.out.println(goods);
// 删除
// goodsRespository.deleteById(1L);
// 批量新增
/* List
list.add(new Goods(1L, "小米手机7", "手机", "小米", 3299.00,"http://image.leyou.com/13123.jpg"));
list.add(new Goods(2L, "坚果手机R1", "手机", "锤子", 3699.00,"http://image.leyou.com/13123.jpg"));
list.add(new Goods(3L, "华为META10", "手机", "华为", 4499.00,"http://image.leyou.com/13123.jpg"));
list.add(new Goods(4L, "小米Mix2S", "手机", "小米", 4299.00,"http://image.leyou.com/13123.jpg"));
list.add(new Goods(5L, "荣耀V10", "手机", "华为", 2799.00,"http://image.leyou.com/13123.jpg"));
goodsRespository.saveAll(list);*/
1.7 查询
1.7.1 goodsRespository自带的查询
// Iterable
// Iterable
Iterable
for (Goods goods : goodsList) {
System.out.println(goods);
}
1.7.2 自定义查询方法
可以在接口中根据规定定义一些方法就可以直接使用
public interface GoodsRespository extends ElasticsearchRepository
public List
public List
public List
public List
public List
}
使用:
// List
List
for (Goods goods : goodsList) {
System.out.println(goods);
}
1.8 SpringDataElasticSearch结合原生api查询
1、结合native查询
@Test
public void testQuery(){
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
nativeSearchQueryBuilder.withQuery(QueryBuilders.termQuery("title", "小米"));
// nativeSearchQueryBuilder.withQuery(QueryBuilders.matchAllQuery());
// nativeSearchQueryBuilder.withPageable(PageRequest.of(0,3,Sort.by(Sort.Direction.DESC,"price")));
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms("brandAvg").field("brand"));
AggregatedPage
Aggregations aggregations = aggregatedPage.getAggregations();
Terms terms = aggregations.get("brandAvg");
Listextends Terms.Bucket> buckets = terms.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString()+bucket.getDocCount());
}
List
for (Goods goods : content) {
System.out.println(goods);
}
}
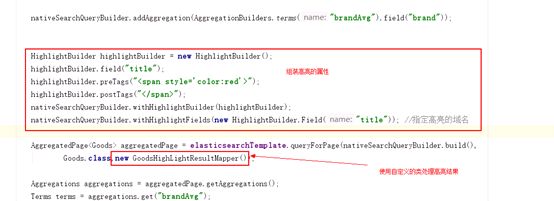
2、自己处理高亮
需要自定一个用来处理高亮的实现类
class GoodsHighLightResultMapper implements SearchResultMapper{
@Override
public
List
Aggregations aggregations = searchResponse.getAggregations();
String scrollId = searchResponse.getScrollId();
SearchHits searchHits = searchResponse.getHits();
long total = searchHits.getTotalHits();
float maxScore = searchHits.getMaxScore();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
T t = JSON.parseObject(sourceAsString, aClass);
Map
HighlightField highlightField = highlightFields.get("title");
String title = highlightField.getFragments()[0].toString();
try {
BeanUtils.setProperty(t,"title",title);
} catch (Exception e) {
e.printStackTrace();
}
content.add(t);
}
return new AggregatedPageImpl
// List
}
3、使用