Java 语言支持的类型分为两类:基本类型和引用类型。整型(byte 1, short 2, int 4, long 8)、字符型(char 2/4)、浮点型(float 4, double 8)和布尔型(boolean 1)都是基本类型。
Java 字符类型采用 UTF-16 编码,UTF-16 以双字节为编码单位,一个字符占 2 字节或 4 字节。中文和英文在 UTF-16 中都占 2 字节。
char c = '\u9999';
注意,如果使用一个巨大的整数值(超出 int 的表示范围),Java 不会自动把这个整数当成 long 来处理——除非显式的加上 l 或 L:
long longValue = 99999999999999; // 错误
long longValue = 99999999999999L; // 正确
同理,也不能将不带 f 或 F 的浮点型赋给 float 类型:
float f = 3.14; //错误
float f = 3.14F; //正确
Java 的 switch 语句原来支持 byte、short、char、int 四种类型,Java 7 增加了 String 类型。另,一直不支持 boolean 类型。
Java 中的 break 可以直接跳出外层循环,有时候还是蛮有用的:
outer:
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++) {
if ( xxx ){
break outer;
}
}
}
Java 中,数组也是一种数据类型,一种引用类型。
String[] ss = new String[]{"ab", "cd", "ef"}; // 静态初始化
String[] ss = {"ab", "cd", "ef"}; // 简化的静态初始化
String[] ss = new String[3]; // 动态初始化,系统赋类型默认值
Java 5 提供的 foreach 循环:
for (String s : ss) {
System.out.println(s);
}
Java 的核心概念(区别于C/C++)——引用。REMEMBER.
面向对象 OO
public, protected, private, default(无); abstract, final; static.对象,引用;引用在栈区,对象在堆区;
this.静态(
static)成员不能访问非静态成员;但非静态成员可以访问静态成员;外部类只能用
public修饰或无修饰;-

比如用
private修饰的name成员变量,那么就不能p.name来访问。p.name是要把name属性直接暴露出来!Java 引入包(package)制,提供了类的多层命名空间,用于解决类的命名冲突、类文件管理等问题。
同一个类中一个构造方法调用另一个构造方法:
this(xx, xx);调用父类构造器:super(xxx, xxx);子类构造器执行前会先调用父类构造器,一直向上到
java.lang.Object的构造器,这个过程必须完成,哪里被中断哪里就错了。(要么你显式super调用,要么系统自动调用父无参构造器)结果是,创建任何类的对象,最先执行的都是java.lang.Object的构造器。
比如:子类中没有用super显示调用父类构造器,而父类也没有无参构造器,这时就会编译出错相同类型的变量,调用同一个方法时呈现出多种不同的行为特征,这就是多态;
-
Java引用变量有两个类型:编译时类型和运行时类型。编译时类型是变量声明时的类型;运行时类型是实际赋给该变量的对象类型;编译时类型和运行时类型不同,就可能出现多态。-
BaseClass b = new SubClass();//编译时类型和运行时类型不同; -
b.selfIntroduce();//会调用运行时类型的方法,即子类的方法;
-
引用变量在编译阶段只能调用其编译时类型所具有的方法,但在运行时则执行它运行时类型所具有的方法;
因此,代码中b.subClassMethod();是编译不通过的。看起来像废话。如果想把某些类设置成最终类,即不能被当成父类,则可以使用
final修饰这个类;除此之外,使用private修饰这个类的所有构造器,从而保证子类无法调用该类的构造器,也就无法继承该类,也无法创建该类的实例。对于把所有构造器都设为private的类而言,可另外提供一个静态方法,用于创建该类的实例。继承与组合
is-avshas-aJava 对实例变量进行初始化的顺序是:先执行 初始化块 或 声明实例变量 时指定的初始值,再执行构造器里指定的初始值。
当
JVM第一次使用某个类时,系统会首先为该类的所有静态成员变量分配内存,接着对这些静态成员变量进行初始化,即执行静态初始化块代码static{}或 声明静态成员变量时指定的初始值。final变量不能重新赋值,子类不能复写父类的final方法,final类不能派生子类。通过使用,不可变会让系统更加安全。final关键字,可以实现不可变类
不可变类不是仅仅靠
final来实现的!不可变类是用代码控制的!看下面!
final修饰的成员变量必须显式的指定初始值,否则这些成员变量的值就一直是系统默认分配的0, '\u0000', false, null。这里的“显式指定”可以在声明变量时,可以在初始化块里,可以在构造器里。-
String和其他类的相互转化:-
String.valueOf()或直接value + ""; -
Integer.parseInt(), Double.parseDouble()...;
-
- 常量池:专门用于管理在编译时被确定并被保存在已编译的.class文件中的一些数据。它包括类、方法、接口中的常量,还包括字符串常量。
常量池中的对象,系统会自动保留对他们的强引用——所以不会轻易地被垃圾回收; -
new String("hello");会产生两个字符串对象:一个字符串常量"hello"对象在常量池中;一个在运行时的内存堆中; - 有抽象方法的类一定要定义为抽象类,抽象类不一定要有抽象方法。抽象方法不能有方法体,抽象类不能实例化,只能作为父类被其他子类继承;
- 从语义的角度来看,抽象类是从多个具体类中抽象出来的父类,它具有更高层次的抽象,抽象类避免了子类设计的随意性。
- 将抽象进行的跟彻底——接口——接口里所有方法都是抽象方法。
- 匿名内部类
-
- 被匿名内部类访问的局部变量自动变成
final修饰。 -
native关键字的意思是该方法是由其他语言实现的; -
Lambda表达式的类型是函数式接口; - 函数式接口:只包含一个抽象方法的接口——可以有其他方法,但只能有一个抽象方法;
Lambda表达式也是对象; -
Lambda表达式的本质:使用简洁的语法来创建函数式接口的实例。 -
JAR文件——Java Archive File———— Java 档案文件。
就是压缩文件而已,只不过是 Java 平台内部处理的标准。和普通 zip 或 rar 格式的压缩文件没什么区别,只不过多一个MANIFEST.MF清单文件。作用和压缩文件是一样的:打包压缩在一起,便于传输和处理。
工具类
java.util.Arrays
-
asList(T... a):好像只有这一个方法可以把任意个元素组成 List ;否则你只有 new 一个 List 然后 一个个 add 了: -
- 或者,后面的
Collections.addAll(Collection c, T... a); -
binarySearch(int[] a, int key):各种版本的二分查找(数组必须已有序); -
copyOf & copyOfRange:复制一个数组; -
equals(int[] a, int[] a2):比较两个数组(的每一个元素); -
deepEquals(Object[] a1, Object[] a2):Returns true if the two specified arrays are deeply equal to one another. -
toString(int[] a):友好的输出数组(元素);直接用System.out.println(int[] a)输出的是哈希值; -
deepToString(Object[] a):Returns a string representation of the deep contents of the specified array. -
fill(int[] a, int val):填充数组内容; -
hashCode(int[] a):Returns a hash code based on the contents of the specified array. -
deepHashCode(Object[] a):Returns a hash code based on the "deep contents" of the specified array. -
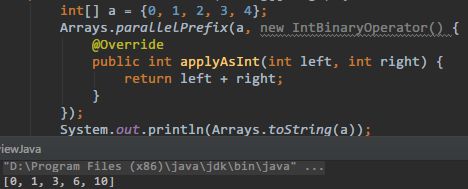
parallelPrefix(int[] array, IntBinaryOperator op):并行,累积(cumulate)计算;Cumulates, in parallel, each element of the given array in place, using the supplied function. For example if the array initially holds [2, 1, 0, 3]
and the operation performs addition, then upon return the array holds [2, 3, 3, 6].
Parallel prefix computation is usually more efficient than sequential loops for large arrays. -
-
setAll(int[] array, IntUnaryOperator generator):和上面的fill很像,但这里用的是生成函数generator,而不是静态值;
generator - a function accepting an index and producing the desired value for that position
可以用lambda表达式。
-
parallelSetAll(int[] array, IntUnaryOperator generator):并行版; -
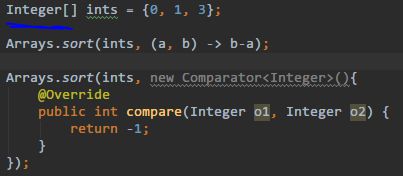
sort(int[] a):排序; -
sort(T[] a, Comparator c):自定义比较函数; -
parallelSort(int[] a):并行的排序; -
spliterator(double[] array):spliterator, splitable iterator,可分割迭代器,Java 8 新增的用于 并 行 遍 历 数据而设计的迭代器。见这里。
-
stream(double[] array):Java 8 流式编程接口,Returns a sequential DoubleStream with the specified array as its source.**
java.util.Scanner
一个文本扫描器,可以扫描File/Path(都指向一个文件), InputStream, String等实现了Readable接口的对象;
A simple text scanner which can parse primitive types and strings using regular expressions.
A Scanner breaks its input into tokens using a delimiter pattern, which by default matches whitespace. The resulting tokens may then be converted into values of different types using the various next methods.
String input = "1 fish 2 fish red fish blue fish";
Scanner s = new Scanner(input).useDelimiter("\\s*fish\\s*");
System.out.println(s.nextInt());
System.out.println(s.nextInt());
System.out.println(s.next());
System.out.println(s.next());
s.close();
1
2
red
blue
-
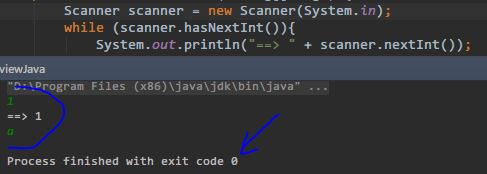
hasNext():有下一个字符串;默认以空白符为Delimiter; -
next():获取下一个字符串; -
hasNextBoolean/Byte/Int/Long/Double/Float:下一个。。。 -
hasNextLine():还有下一行;+nextLine(); -
useDelimiter(String pattern):自定义分隔符(Delimiter); -
useRadix(int):自定义数字的进制: -
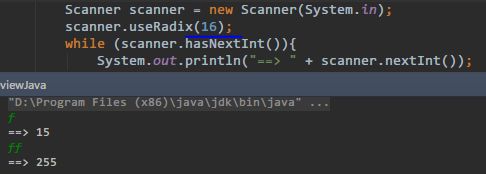
当读到不符合要求的内容时,hasNextXXX()方法静默退出,不抛出任何异常:
Scanner还支持与正则表达式配合使用。
System 类
System 类代表当前 Java 程序的运行平台,程序不能创建 System 类的对象;System 类提供了代表标准输入、标准输出、标准错误的类变量,并提供了一些静态方法用于访问环境变量、系统属性,还提供了加载文件和动态链接库的方法。
-
System.exit(int status):退出虚拟机; -
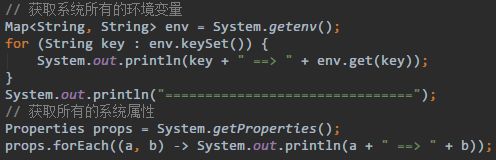
System.getenv():获取环境变量; -
System.getProperties():获取系统属性; -
-
System.gc():通知系统进行垃圾清理; -
System.runFinalization():通知系统进行资源回收;(貌似都没什么用) System.currentTimeMillis():当前时间毫秒;-
System.in System.out System.err:三个标准流; -
System.setIn() setOut() setErr():重定向; -
System.identityHashCode(Object X):根据对象的内存地址计算得到的 Hash 值;当某个类的hashCode()方法被重写后,该类实例的hashCode()方法就不能唯一的标识该对象;此时就可以用identityHashCode()方法。
Runtime 类
Runtime 类代表 Java 程序的运行时环境,每个 Java 程序都有一个与之对应的 Runtime 实例,应用程序通过该对象与其运行时环境相连。程序不能自己创建 Runtime 实例,但可以通过 getRuntime()方法获取与之关联的 Runtime 对象;
- 与 System 类类似的是 Runtime 类也提供了
gc()方法和runFinalization()方法来通知系统进行垃圾回收、资源清理,并提供了load(String filename) 和 loadLibrary(String libname)方法来加载文件和动态链接库。 -
runtime.exec("notepad.exe"):运行CMD命令!和 Python 一样!

java.util.Objects
Java 7 新增了一个 Objects 工具类,它提供了一些工具方法来操作对象,这些工具方法大多是“空指针”安全的。比如你不能确定一个引用变量是否为 null,如果贸然调用该变量的 toString() 方法,则可能引发 NullPointerException 异常;但如果使用 Objects 类提供的 toString() 方法,就不会引发空指针异常——当 o 为 null 时,程序就返回一个 “null” 字符串。
-
Objects.requireNonNull(T obj):当 obj 为 null 时抛出 NullPointerException 异常。
java.lang.String
public final class String
extends Object
implements Serializable, Comparable, CharSequence
不可被继承;;
The class String includes methods for examining individual characters of the sequence, for comparing strings, for searching strings, for extracting substrings, and for creating a copy of a string with all characters translated to uppercase or to lowercase.
-
String(byte[] bytes, Charset charset):Constructs a new String by decoding the specified array of bytes using the specified charset. -
String(char[] value),String(String original),String(StringBuffer buffer),String(StringBuilder builder); -
length()/isEmpty()/toLowerCase()/toUpperCase():基本操作; -
trim():去除收尾的空白符; -
charAt(int index):获取字符串中的单个字节; -
int compareTo(String anotherString)/compareToIgnoreCase(String str):比较字符串;返回第一个不同字符的差值; -
concat(String str):连接,即加到尾部; -
boolean contains(CharSequence s):包含;查找字符串; -
equals(Object anObject)/equalsIgnoreCase(String anotherString):比较字符串; -
static String format(String format, Object... args):格式化字符串,类似于 C 语言的printf()或 Python 的%; -
byte[] getBytes(Charset charset)/getBytes(String charsetName):Encodes this String into a sequence of bytes using the given charset, storing the result into a new byte array. -
getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin):字节数组; -
char[] toCharArray():返回一个 char 数组,包含相同内容; -
hashCode():String 类重写了hashCode()方法!记住! -
-
int indexOf(int ch)/indexOf(String str[, int fromIndex])/lastIndexOf(int ch[, int fromIndex])/lastIndexOf(String str[, int fromIndex])/endsWith(String suffix)/startsWith(String prefix):检索字符/字符串; -
static String join(CharSequence delimiter, CharSequence... elements):join操作;String.join("xxx", "a", "b", "c"); -
String[] split(String regex[, int limit]):split操作——join的逆操作; -
-
boolean matches(String regex):正则表达式;Tells whether or not this string matches the given regular expression. -
String replace(char oldChar, char newChar)/replace(CharSequence target, CharSequence replacement)/replaceAll(String regex, String replacement)/replaceFirst(String regex, String replacement):字符串操作,替换; -
substring(int beginIndex[, int endIndex]):子串; -
static String valueOf(boolean b/char c/char[] data/double d/int i/long l/Object obj):转换其他类型;


StringBuilder:非线程安全,性能略高;StringBuffer:线程安全;// 可变字符串类;
sb.append(), insert(), replace(), delete(), reverse()等原地操作;
java.lang.Math
稍复杂的计算,如三角函数、对数、指数;
-
Math.E/Math.PI:2.718281828459045 / 3.141592653589793 -
abs(T t), toDegrees(1.57), toRadians(90), sin/cos/tan, max/min:基本计算; -
floor()/ceil():向下取整(小于目标数的最大整数)/向上取整; -
round():四舍五入取整; -
sqrt()/cbrt:平方根/立方根;(square root / cubic root) -
exp(n):e 的 n 次 幂; -
pow(x, y):x 的 y 次方; -
log(x)/log10(x):自然对数/底为 10 的对数; -
Math.random():返回 0.0 到 1.0 之间的伪随机数;
java.util.Random
一个功能更完善(相比如Math.random())的随机数生成器;
如何生成 [5, 20)之间的随机数?r.nextInt(15) + 5
-
Random([long seed]):种子;默认为当前系统时间; -
DoubleStream doubles([long streamSize[, double randomNumberOrigin, double randomNumberBound]]):流式编程,生成一个[ 0.0, 1.0 )(或[ randomNumberOrigin, randomNumberBound ))的 Double 流; -
IntStream ints(long streamSize, int randomNumberOrigin, int randomNumberBound):同上(不过返回的是任意一个合法整数或[ Origin, Bound ));longs(...); -
nextBoolean(), nextBytes(byte[] bytes), nextDouble(), nextFloat(), nextInt(), nextLong(): -
nextInt(int bound):返回 [ 0, bound ) 之间的任意一个整数; -
相同的种子会产生相同的伪随机数序列:

java.util.Date & java.util.Calendar 时间日期类
Date无法实现国际化,而且它对不同属性也使用了前后矛盾的偏移量,比如月份和小时都是以 0 开始的,月份中的天数则是从 1 开始的;
Date从 JDK1.0 就开始存在了,它的大部分构造器、方法都已经过时,不再推荐使用;
总体来说,
Date是一个设计相当糟糕的类,因此 Java 官方建议尽量少用Date;因为
Date类在设计上存在一些缺陷,所以 Java 提供了Calendar类(since jdk1.1)来更好的处理日期和时间;而
Calendar又显得过于复杂;
java.time Java 8 新增的日期、时间包
参考:Java8 日期/时间(Date Time)API 指南
为什么我们需要新的 Java 日期/时间API?
在开始研究 Java 8日期/时间 API 之前,让我们先来看一下为什么我们需要这样一个新的API。在Java中,现有的与日期和时间相关的类存在诸多问题,其中有:
- Java 的日期/时间类的定义并不一致,在 java.util 和 java.sql 的包中都有日期类,此外用于格式化和解析的类在 java.text 包中定义。
- java.util.Date 同时包含日期和时间,而 java.sql.Date 仅包含日期,将其纳入 java.sql 包并不合理。另外这两个类都有相同的名字,这本身就是一个非常糟糕的设计。
- 对于时间、时间戳、格式化以及解析,并没有一些明确定义的类。对于格式化和解析的需求,我们有 java.text.DateFormat 抽象类,但通常情况下,SimpleDateFormat 类被用于此类需求。
- 所有的日期类都是可变的,因此他们都不是线程安全的,这是 Java 日期类最大的问题之一。
- 日期类并不提供国际化,没有时区支持,因此Java引入了 java.util.Calendar 和 java.util.TimeZone 类,但他们同样存在上述所有的问题。
在现有的日期和日历类中定义的方法还存在一些其他的问题,但以上问题已经很清晰地表明:Java 需要一个健壮的日期/时间类。这也是为什么 Joda Time 在 Java 日期/时间需求中扮演了高质量替换的重要角色。
Java 8日期/时间 API
Java 8日期/时间 API 是 JSR-310 的实现,它的实现目标是克服旧的日期时间实现中所有的缺陷,新的日期/时间API的一些设计原则是:
- 不变性:新的日期/时间 API 中,所有的类都是不可变的,这对多线程环境有好处。
- 关注点分离:新的 API 将人可读的日期时间和机器时间(unix timestamp)明确分离,它为日期(Date)、时间(Time)、日期时间(DateTime)、时间戳(unix timestamp)以及时区定义了不同的类。
- 清晰:在所有的类中,方法都被明确定义用以完成相同的行为。举个例子,要拿到当前实例我们可以使用 now() 方法,在所有的类中都定义了 format() 和 parse() 方法,而不是像以前那样专门有一个独立的类。为了更好的处理问题,所有的类都使用了工厂模式和策略模式,一旦你使用了其中某个类的方法,与其他类协同工作并不困难。
- 实用操作:所有新的日期/时间 API 类都实现了一系列方法用以完成通用的任务,如:加、减、格式化、解析、从日期/时间中提取单独部分,等等。
- 可扩展性:新的日期/时间 API 是工作在 ISO-8601 日历系统上的,但我们也可以将其应用在非 IOS 的日历上。
Java 日期/时间 API 包
Java 日期/时间 API 包含以下相应的包。
- java.time 包:这是新的 Java 日期/时间 API 的基础包,所有的主要基础类都是这个包的一部分,如:
LocalDate, LocalTime, LocalDateTime, Instant, Period, Duration等等。所有这些类都是不可变的和线程安全的,在绝大多数情况下,这些类能够有效地处理一些公共的需求。- java.time.chrono 包:这个包为非 ISO 的日历系统定义了一些泛化的 API,我们可以扩展 AbstractChronology 类来创建自己的日历系统。
- java.time.format 包:这个包包含能够格式化和解析日期时间对象的类,在绝大多数情况下,我们不应该直接使用它们,因为 java.time 包中相应的类已经提供了格式化和解析的方法。
- java.time.temporal 包:这个包包含一些时态对象,我们可以用其找出关于日期/时间对象的某个特定日期或时间,比如说,可以找到某月的第一天或最后一天。你可以非常容易地认出这些方法,因为它们都具有 “withXXX” 的格式。
- java.time.zone 包:这个包包含支持不同时区以及相关规则的类。
System.out.println(LocalDateTime.now());
2017-01-29T21:19:52.802
java.util.集合
这是一个大主题,待发掘。这里只记录一些细枝末节。
Collection和Map接口是Java集合框架的根接口。
Collection接口(子接口为Set和List)中定义的方法包括:
add(Object o), addAll(Collection c), remove(Object o), removeAll(Collection c), retainAll(Collection c)(求交集),
removeIf(Predicate filter)(Java 8 新增,批量删除符合条件的元素)
clear(), isEmpty(), size()
contains(Object o), containsAll(Collection c),
iterator(), spliterator()
toArray(),
stream()/parallelStream()(流式编程)
forEach(Comsumer action):Java 8 为Iterable接口新增的默认方法;
迭代Collection集合过程中不要修改集合内容,否则会引发ConcurrentModificationException;(尽管在用Iterator遍历时可以用iterator.remove()方法删除上一次迭代的元素)
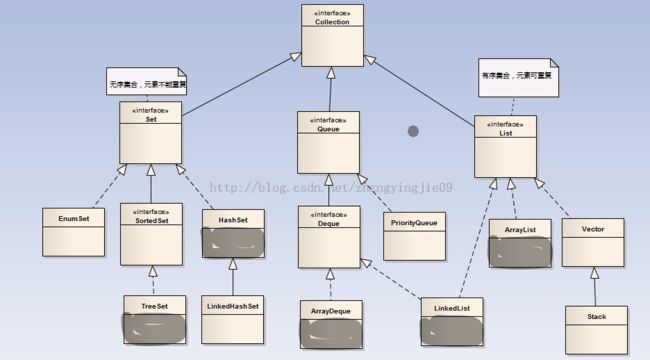
常用的类有:
-
HashSet:Set接口的 哈希表(Hash Table)实现;非线程安全;根据hashCode()值和equals()方法来确定对象的存储位置——先根据hashCode()值计算桶位,再用equals()方法比较(如果桶位上已经有对象);分析以下四种情况:-
hashCode()不同,equals()为true——存在两个不同的桶里; -
hashCode()相同,equals()为false——存储在同一个桶里,链接法链起来; -
hashCode()不同,equals()为false——存在不同的桶里; -
hashCode()相同,equals()为true——后面一个存不进去,冲突了;
-
- 所以,当我们试图把某个类的对象存入
Set中时,应重写该类的hashCode()和equals()方法,并使他们的返回值保持一致。Set.remove()的逻辑也是一样的:先通过hashCode()方法计算桶位,在用equals()比较。 -
LinkedHashSet:在HashSet的基础上,用 双 链 表 维护元素添加的顺序,可以获得更快的遍历速度,并且是按元素的添加顺序遍历;

-
SortedSet接口; -
TreeSet:红黑树实现;确保集合元素处于有序状态;TreeSet会调用对象的compareTo()方法来进行比较,从而确定元素的存储位置;这里虽然不关equals()方法什么事,但从逻辑上考虑还是应该保证equals()方法和compareTo()的一致性。- Java 提供了一个
Comparable接口,该接口里定义了一个compareTo()方法; - 已实现了
Comparable接口的类有:BigDecimal, BigInteger, 以及所有数值类型的包装类(Double, Integer...), Character, Boolean(true > false), String, Date, Time等;
- Java 提供了一个
-
EnumSet:专为枚举类设计的集合,EnumSet中的元素必须是指定枚举类型的枚举值; -
List是Collection的子接口,是有序集合,因此新增了一些根据索引来操作集合元素的方法:-
add(int index, Object o), allAll(int index, Collection o), get(int index), indexOf(Object o), lastIndexOf(Object o), remove(int index), set(int index, Object element), subList(int fromIndexInclude, int toIndexExclude), replaceAll(UnaryOperator operator), sort(Comparator c);
-
- 相比于
Set,List接口还额外提供了listIterator()方法来返回一个ListIterator迭代器;ListIterator继承自Iterator接口,新增了专门操作List的方法:-
boolean hasPrevious(), Object previous(), add(Object o);向前迭代和增加元素(Iterator只能向后迭代和删除元素);
-
-
ArrayList:
ArrayList和Vector
Vector是一个非常古老的类(since jdk1.0),有很多缺陷,不建议使用;
Stack(栈)继承自Vector,因此也不建议使用;
若要使用“栈”这种数据结构,用ArrayDeque;
- 固定长度的
List:Arrays.asList(T... a)返回的是固定长度的List集合,不支持增加、删除元素; -
Queue集合 -
Queue接口:-
add(Object o):将指定元素加入队列尾部; -
peek():获取队列头部元素,但不删除; -
poll():获取队列头部元素,并删除; - 还有
element(), offer(Object e), remove()等方法;
-
Queue有一个PriorityQueue实现类。除此之外,Queue还有一个Deque接口,代表“双端队列”,两端都可以添加、删除元素。Deque的实现类有ArrayDeque和LinkedList。**
-
-
PriorityQueue实现类:加入队列中的元素会按大小排序; -
ArrayDeque:和ArrayList很像,只是加入了在数组前端添加、删除的功能; -
LinkedList:List的链表实现,同时实现了Deque接口,也是双端队列的实现类; -
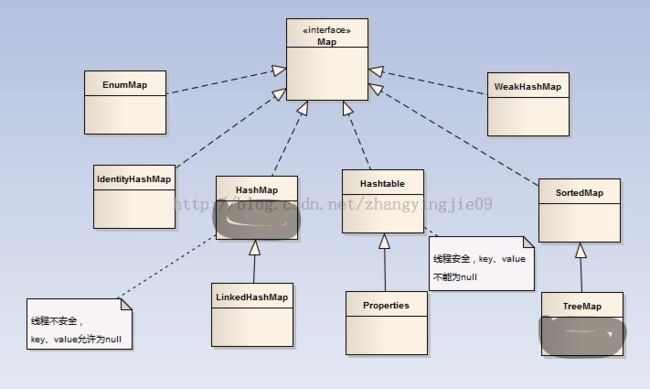
从 Java 源码来看,Java 是先实现了 Map ,然后通过包装一个所有 value 都为 null 的 Map 就实现了 Set 集合。
-
HashMap:Map接口的 哈希表(Hash Table)实现;-
IdentityHashMap:当且仅当两个 key 严格相等(key1 == key2)时才认为两个 key 相等:

-
-
TreeMap:SortedMap接口实现类,红黑树实现; -
LinkedHashMap:同LinkedHashSet; -
EnumMap:同EnumSet; -
Map接口方法:
clear(), containsKey(Object key), containsValue(Object value), isEmpty(), size(),
Set entrySet():返回 Map 中所有 key-value 对组成的 Map.Entry 对象的 Set 集合;(Entry 是 Map 的内部类,有getKey(), getValue(), setValue(V value)三种方法)
Set keySet():返回所有 key 组成的 Set 集合;
Collection values():返回所有 value 组成的 Collection 集合;
get(Object key), put(Object key, Object value)(key 存在则覆盖原 value,不存在则添加一个新的 key-value 对), remove(Object key)/remove(Object key, Object value),
putAll(Map m)Java 8 为 Map 新增的方法:
compute(Object key, BiFunction remappingFunction)/computeIfAbsent/computeIfPresent
forEach(BiConsumer action):遍历 key-value 对;
getOrDefault(Object key, V defaultValue):获取指定 key 值对应的 value,key 不存在时返回 defaultValue;
putIfAbsent(Object key, V value)
replace(Object key, V value):与 put 不同的是,当 key 不存在时不会添加新的 key-value 对;
replaceAll(BiFunction function):用 BiFunction 重新计算所有的 key-value 对;
- 使用
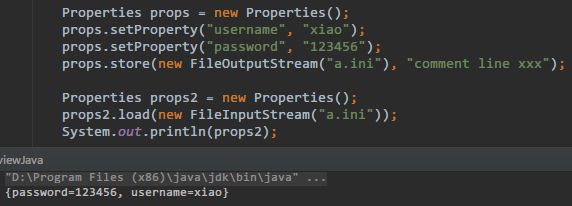
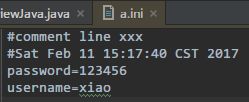
Properties读写属性文件(Windows 平台上的 ini 文件就是一种属性文件) -
Properties类可以把 Map 对象和属性文件关联起来,从而方便的读写属性文件中的键值对;
Properties相当于一个 key、value 都是 String 类型的 Map。
java.util.Collections 工具类
排序操作:
-
reverse(List list), shuffle(List list), sort(List list), sort(List list, Comparator c):颠倒顺序,洗牌(打乱顺序),排序; -
swap(List list, int i, int j):交换元素; -
rotate(List, int distance):当 distance 为正时,将 list 集合后 distance 个元素整体移动到前面;为负时将前 distance 个元素移动到后面;
查找、替换操作:
-
int binarySearch(List list, Object key):二分查找,前提有序; -
max(Collection c)/max(Collection, Comparator comp)/min/min:根据自然顺序/指定顺序返回最大/最小元素; -
fill(List list, Object o):填充; -
int frequency(Collection c, Object o):出现次数; -
replaceAll(List list, Object oldVal, Object newVal):替换所有旧值;
同步控制:
-
synchronizedList/Set/Map(List/Set/Map c):将指定集合包装成同步的,即线程安全的;Java 集合框架中常用的 ArrayList, ArrayDeque, LinkedList, HashSet, TreeSet, HashMap, TreeMap 都是线程不安全的;
设置不可变集合:
-
emptyXxx():返回一个空的,不可变的集合对象; -
singleton(T o)/singletonList(T o)/singletonMap(K k, V v):返回一个仅包含一个元素的 set,list,map; -
unmodifiableXxx(C c):返回指定集合对象的不可变视图;只读,任何修改操作都不支持(包括修改 key-value 对的 value);
泛型
本章的内容可以与前一章的内容补充阅读,因为 JDK1.5 增加泛型支持在很大程度上都是为了让集合能记住其元素的数据类型。
“菱形语法”:List
所谓泛型,就是允许在定义类、接口、方法时使用 类 型 参 数。
上述菱形语法中的
使用通配符来匹配任何泛型:
public void test(List l){}
这里List表示所有泛型List的父类。
List:设定通配符的上限;
List:设定通配符的下限;
定义泛型方法:
void fromArrayToCollection(T[] a, Collection c) {
for (T o : a){
c.add(a);
}
}
fromArrayToCollection(a, c);// 调用的时候无需显式传入类型参数,编译器会根据实参类型自动推断;
不支持泛型数组——
能够声明List类型,[]
但不能创建ArrayList的实例。[10]
无法实例化,也就不能用。
异常处理
异常机制可以使程序中的异常处理代码和正常业务逻辑分离,从而使程序代码更加优雅,并且更具健壮性。
try, catch, finally, throw, throws
-
try块用于放置可能抛出异常的代码; - 多个
catch块用于捕捉异常; -
finally块用于释放在try块里打开的物理资源,异常机制会保证finally块总被执行(只有用System.exit(1)来退出虚拟机才可以避免 finally 的执行;return 语句不能阻止。); -
throw:(在代码中)抛出异常:throw new Exception("您正在闯红灯!请赶紧停下!"); -
throws:(在定义方法时)声明抛出异常:public static void main(String[] args) throws IOException {
Checked异常和Runtime异常:Checked异常是可以在编译阶段被处理的异常,所以必须被手动、显式的处理;Runtime异常是运行时异常,无需强制处理;
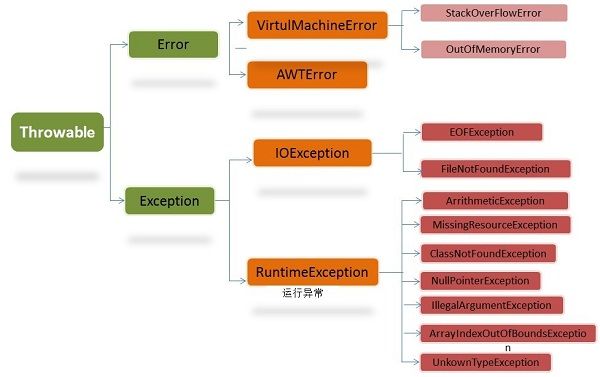
Error 错误,一般是指与虚拟机相关的问题,如系统崩溃、虚拟机错误、动态链接失败等,这种错误无法恢复或不可捕捉,通常应用程序无法处理,因此程序中不应该试图用 catch 捕获 Error 对象。
先处理小异常,再处理大异常。
总是把对应 Exception 的 catch 块放在最后,因为如果把它放在前面,则后面的 catch 块将永远不会获得执行的机会。
Java 7 提供的多异常捕获:catch (IndexOutOfBoundsException|NumberFormatException|ArithmeticException e){}
使用try-catch-finally的正确姿势:
FileInputStream fis = null;// 【块】 作用域,所以在这里 【声 明】;
try {
fis = new FileInputStream("a.txt");// 在 try 块中 尝 试 打开;
...
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fis != null) {// 这里,因为可能打开失败,fis还是null;
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
上面代码显得有些臃肿。Java 7 提供了自动关闭资源的 try 语句。

注意点:
- 资源的声明和初始化都必须放在()里,不能像上面那样在外面声明里面初始化;
- fis 的作用域还是只有在 try 块中;catch 块和外部都无法访问;
- 这里的自动关闭特性只是省去了 finally 语句,catch 捕捉异常还是不可省的;
能自动关闭是因为资源类实现了AutoCloseable或Closeable接口;
Java 7 几乎把所有的资源类(文件 IO、JDBC 的 Connection、Statement 等接口)都实现了
AutoCloseable或Closeable接口;所以,任性的用吧;
暂时不想处理或不能处理的异常,用throw或throws往上抛;throw在代码中抛,throws在方法声明中抛;或者先在 catch 中部分处理异常,处理不了的部分再往上抛;
自定义异常类
继承Exception或RuntimeException类;
public class MyException extends Exception {
public MyException(){
super();
}
public MyException(String msg) {
super(msg);
}
}
不要使用过于庞大的 try 块,而是划分为多个 try-catch 单元。
MySQL 数据库与 JDBC 编程
JDBC for Java Database Connectivity,Java 数据库连接。
JDBC 为数据库开发提供了标准 API。使用 JDBC 开发的数据库应用可以跨平台,甚至可以跨数据库(如果全部使用标准的 SQL 语句)。
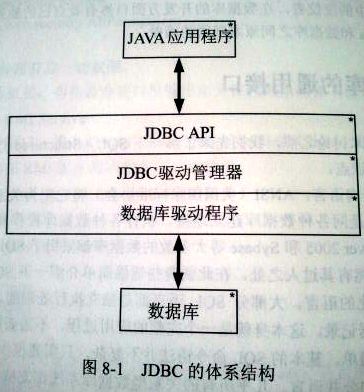
开始之前首先要在项目中引入依赖:
基本过程:
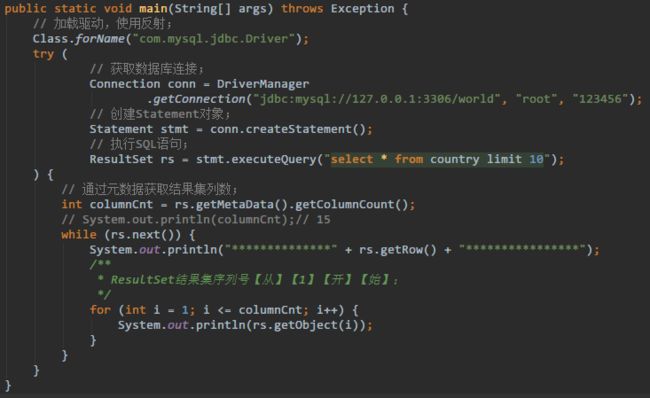
Connection:
-
Statement createStatement():返回一个Statement对象; -
PreparedStatement prepareStatement(String sql):返回预编译的Statement对象; -
CallableStatement prepareCall(String sql):返回CallableStatement对象,用于调用存储过程;
除此之外,Connection还有控制事务的方法:
setSavePoint([String name]), roolback([Savepoint savepoint]), setAutoCommit(boolean autoCommit)(关闭/打开自动提交,打开/关闭事务), commit()
Statement:(PreparedStatement和CallableStatement都是其子类)
-
ResultSet executeQuery(String sql):执行查询语句; -
int executeUpdate(String sql):执行 DML 语句和 DDL 语句,并返回受影响的行数; -
boolean execute(String sql):执行任何 SQL 语句,如果执行后的第一个结果为ResultSet对象,则返回 true;如果执行后的第一个结果为受影响的行数或没有任何结果,则返回 false。 - 执行了
execute之后可以用Statement对象的以下两个方法来获取执行结果:getResultSet()getUpdateCount()
使用PreparedStatement执行 SQL 语句

否则,就得用这种繁琐的字符串拼接方式(注意单引号),不仅很容易出错,还容易遭到 SQL 注入攻击。
String sql = "select * from jdbc_test where jdbc_name='" + userName + "' and jdbc_desc='" + userPass + "'";
还有内容:使用CallableStatement调用存储过程、管理结果集、处理 Blob 类型数据、使用ResultSetMetaData分析结果集、离线RowSet、CachedRowSet查询分页、事务、分析数据库信息、数据库连接池。
Annotation 注解
从 JDK 5 开始,Java 增加了对元数据(
MetaData)的支持,也就是Annotation(注解)。注解是代码里的特殊标记,这些标记可以在编译、类加载、运行时被读取,并执行相应的处理。通过使用注解,开发人员可以在不改变原有逻辑的情况下,在源文件中嵌入一些补充的信息。代码分析工具、开发工具和部署工具可以通过这些补充信息进行验证或部署。
Annotation就像修饰符一样,可用于修饰包、类、构造器、方法、成员变量、参数、局部变量的声明,这些信息被存储在Annotation的"name=value"中。
Annotation是一个接口,程序可以通过 反 射 来获取指定程序元素的Annotation对象,然后通过Annotation对象来取得注解里的元数据。
Annotation不影响代码的执行。
IO 输入输出
java.io.File
An abstract representation of file and directory pathnames.
对文件和目录路径的抽象抽象的文件或目录。
File 能创建、删除、重命名文件和目录——这是文件和目录层面上的,没有进入到文件里面的内容——File 不 能 访 问 文 件 内 容 。访问文件内容需要 IO。
在 File 眼中,文件和目录是一样的;一种抽象的文件和目录——实际存在与否毫不影响。所以才有
exists()方法来判断是否存在。
File 类:
开始之前,一个重要的注意点:File 既可以是相对路径也可以是绝对路径;在相对路径的时候,File 内部并不会自动的把它转为绝对路径;
绝对路径并不是相对路径的完成形式!
绝对路径并不是相对路径的完成形式!!
绝对路径并不是相对路径的完成形式!!!他们是平等的!
所以,
new File("a.ini").getParent()为null,new File("a/b/c").getParent()为a\b;
因为 父路径 仅看/前面的部分 && 相对路径并不会自动补全为绝对路径,相对路径和绝对路径是平等的。
访问文件/路径名:
-
System.out.println(File f)//直接输出File:输出 File 初始化时的路径; -
String getPath():同直接输出 File,输出该 File 对应的路径; -
String getName():文件:文件名;路径:最后一级路径名; -
String getAbsolutePath():根据当前工作路径生成绝对路径,然后输出绝对路径字符串; -
File getAbsoluteFile():同上,但这里返回的是转换为绝对路径后的 File 对象; -
String getParent():路径中/之前的内容,如果没有则返回null; -
File getParentFile():同上,但返回的是父路径 File,若无返回null; -
boolean renameTo(File newNameFile):重命名;
File file = new File("a/b/c");
file: a\b\c
file.getPath(): a\b\c
file.getName(): c
file.getAbsolutePath(): D:\IntellijIDEAProjects\Empty_Project\a\b\c
file.getAbsoluteFile(): D:\IntellijIDEAProjects\Empty_Project\a\b\c
file.getParent(): a\b
file.getParentFile(): a\b
File file = new File("a.ini");
file: a.ini
file.getPath(): a.ini
file.getName(): a.ini
file.getAbsolutePath(): D:\IntellijIDEAProjects\Empty_Project\a.ini
file.getAbsoluteFile(): D:\IntellijIDEAProjects\Empty_Project\a.ini
file.getParent(): null
file.getParentFile(): null
文件/路径检测:
-
boolean exists():判断是否 真 的 存在; -
boolean canWrite()/canRead():是否可写/可读; -
boolean isFile()/isDirectory():是否是文件/目录; -
boolean isAbsolute():是否是绝对路径;
获取常规文件信息:
-
long lastModified():最后修改时间; -
long length():文件内容长度;
文件/路径操作:
-
boolean createNewFile():若文件已经存在,直接返回 false;若不存在,创建成功返回 true,失败返回 false;注意,这个方法只能用来创建文件!new File("a").createNewFile()则创建一个文件a;不能创建路径! -
boolean mkdir():这才是创建目录!但只能创建一层! -
boolean mkdirs():创建多级目录;new File("a/b/c").mkdirs(); -
boolean delete():删除文件或路径的最后一级;上面用mkdirs()一次性创建a/b/c三级目录后,用delete()只能删除最后一级的c目录;所以:
File只能代表一个文件,或一个目录,即多级路径的最后一级;尽管你用了一段长长的路径来初始化它,它实际代表的只有最后一级路径。
-
String[] list():列出所有子文件名和路径名,用String数组盛装; -
File[] listFiles():用File数组盛装; -
static File[] listRoots():列出系统所有的根路径;
File file = new File("xxx");
// 先绝对化,再获取父路径;直接获取是null;
for (String s : file.getAbsoluteFile().getParentFile().list()) {
System.out.println(s);
}
在 Windows 平台的路径分隔符是反斜杠
'\',而 Java 中'\'表示转义,所以要这样写:"F:\\abc\\test.txt";或者直接用'/',Java 支持自动将斜线'/'【当为】平台无关的路径分隔符。
一个思考:

这个应该是在 HTML 中用的;在这里new File(String filename)是字符串,放进去没效果。
IO 流
输入流/输出流;字节流/字符流;节点流/处理流(or 包装流);
-
InputStream/Reader:所有输入流的基类; -
OutputStream/Writer:所有输出流的基类;
Java 使用处理流来包装节点流是一种典型的装饰器设计模式;处理流可以“嫁接”在任何已存在的流的基础之上,这就允许 Java 应用采用相同的代码、透明的方式来访问不同的输入/输出流。
InputStream 和 Reader
FileInputStream fis = new FileInputStream("a.txt");
byte[] bbuf = new byte[5];
int hasRead = 0;
while ((hasRead=fis.read(bbuf)) > 0){
System.out.println(new String(bbuf, 0, hasRead, "gb2312"));
System.out.println("--------");
}
fis.close();
output:
这一�
--------
校�确
--------
实和�
--------
�的父
--------
亲梁�
--------
舫�有
--------
关,�
...
// 将字节缓冲区大小改为1024后,完整输出:
这一切,确实和他的父亲梁启超有关,父亲希望他做一个有趣的人,正如父亲给他的信中说的那样:
我愿意你趁毕业后一两年,分出点光阴,多学些常识,尤其是文学或人文科学中之某部门,稍为多用点功夫。我怕你因所学太专之故,把生活也弄成近于单调,太单调的生活, 容易厌倦,厌倦即为苦恼,乃堕落之根源……不独朋友而已,即如在家庭里头,像你有我这样一位爹爹,也属人生难逢的幸福;若你的学问兴味太过单调,将来也会相对词竭,不能领着我的教训,你在生活中本来应享有的乐趣,也削减不少了。
gb2312编码下,一个中文字符2个字节,若不能读入一个完整的字符就会出现乱码。(即使将字节缓冲区大小设为偶数,仍旧不能避免乱码,因为英文字符和半角标点符号还是占1个字节)
FileReader fr = new FileReader("a.txt");
System.out.println(fr.getEncoding());
char[] cbuf = new char[1024];
int hasRead = 0;
while ((hasRead=fr.read(cbuf)) > 0) {
System.out.println(new String(cbuf, 0, hasRead));
}
fr.close();
output:
��һ�У�ȷʵ�����ĸ����������йأ�����ϣ������һ����Ȥ���ˣ����縸����������˵��������
��Ը����ñ�ҵ��һ���꣬�ֳ����������ѧЩ��ʶ����������ѧ�����Ŀ�ѧ��֮ij���ţ���Ϊ���õ㹦������������ѧ̫ר֮�ʣ�������ҲŪ�ɽ��ڵ�����̫��������� ������룬��뼴Ϊ���գ��˶���֮��Դ�����������Ѷ��ѣ������ڼ�ͥ��ͷ��������������һλ������Ҳ�������ѷ���Ҹ��������ѧ����ζ̫������������Ҳ����Դʽߣ����������ҵĽ�ѵ�����������б���Ӧ���е���Ȥ��Ҳ���������ˡ�
将gb2312格式的a.txt读取成字符串,是需要指定编码的(除非与默认一致为utf-8);但FileReader的构造函数没有接受字符编码参数的版本,so。
读入字节流的时候是不需要编码的,因为是字节;而读入字符流的时候,只有
InputStreamReader这一个从字节流到字符流的转换流提供了接受编码的构造方法。
所以上述代码可以改为:
InputStreamReader fr = new InputStreamReader(new FileInputStream("a.txt"), "gb2312");
OutputStream 和 Writer
FileInputStream fis = new FileInputStream("a.txt");
FileOutputStream fos = new FileOutputStream("acopy.txt");
byte[] bbuf = new byte[32];
int hasRead = 0;
while ((hasRead=fis.read(bbuf)) > 0) {
fos.write(bbuf, 0, hasRead);
}
fis.close();
fos.close();
// 字节流,不涉及编码。
// FileWriter 略;
Windows 平台的换行符是
\r\n,Unix 是\n;
输入输出流类图

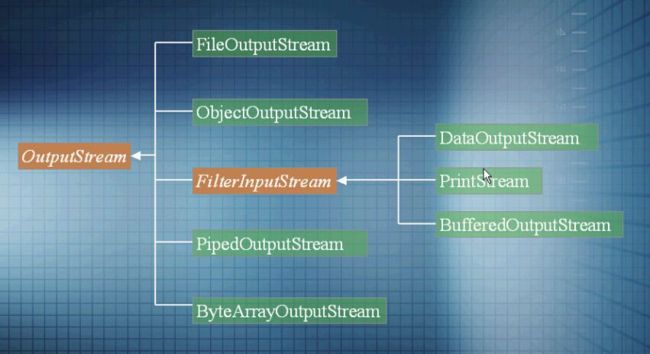
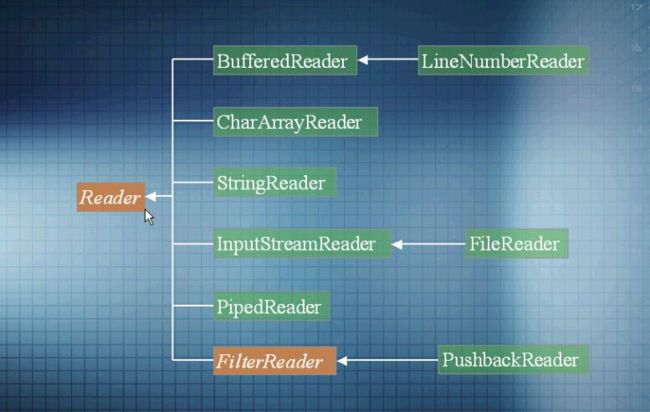
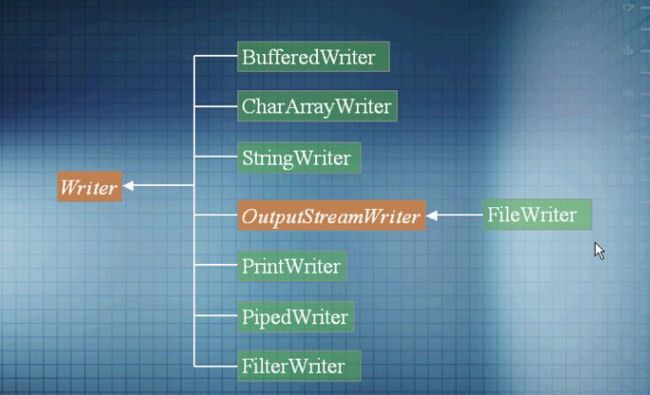
System.in是InputStream,System.out是处理流PrintStream.
输入输出的内容是文本,就应考虑使用字符流;二进制内容就考虑字节流。
InputStreamReader inputStreamReader = new InputStreamReader(new FileInputStream("a.txt"), "gb2312");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String line = null;
while ((line=bufferedReader.readLine()) != null){
System.out.println(line);
}
// InputStreamReader inputStreamReader = new InputStreamReader(new FileInputStream("a.txt"), "gb2312");
// BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
// bufferedReader.lines().forEach(System.out::println);
Java 虚拟机读写其他进程的数据
前面介绍过,Runtime对象的exec()方法可以运行平台上的其他程序,该方法产生一个 Process 对象,Process 对象代表由该 Java 程序启动的子进程。Process 类提供了如下三个方法:
-
InputStream getErrorStream():获取子程序的错误流; -
InputStream getInputStream():获取子进程的输出流(麻蛋,这里居然是站在主进程的角度); -
OutputStream getOutputStream():获取子进程的输入流;
Process p = Runtime.getRuntime().exec("ipconfig");
BufferedReader br = new BufferedReader(new InputStreamReader(p.getInputStream(), "gbk"));
br.lines().forEach(System.out::println);
output:
Windows IP 配置
无线局域网适配器 无线网络连接 2:
连接特定的 DNS 后缀 . . . . . . . :
本地链接 IPv6 地址. . . . . . . . : fe80::412e:cbae:8818:bef1%14
IPv4 地址 . . . . . . . . . . . . : 172.18.217.1
子网掩码 . . . . . . . . . . . . : 255.255.0.0
默认网关. . . . . . . . . . . . . :
... ...
序列化
对象序列化的目标是将对象保存到磁盘中,或在网络中直接传输对象。对象序列化机制允许把内存中的 Java 对象转换为平台无关的二进制流,并可将这种二进制流恢复成原来的 Java 对象。
序列化:Serialize,反序列化:Deserialize;
为了让某个类是可序列化的,该类必须 实现以下两个接口之一:Serializable或Externalizable;
Serializable是一个标记接口,实现该接口无需实现任何方法,它只是表明该类的实例是可序列化的。
通常建议:程序创建的每个
JavaBean类都实现Serializable。
处理流ObjectOutputStream和ObjectInputStream
public class ReviewJava {
public static void main(String[] args) throws IOException, ClassNotFoundException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("objectOutput.txt"));
oos.writeObject(new Person("孙悟空", 500));
oos.close();
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("objectOutput.txt"));
Person p = (Person) ois.readObject();
System.out.println(p);
ois.close();
}
}
class Person implements Serializable{
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
output:
Person{name='孙悟空', age=500}
反序列化机制无需通过构造器来初始化 Java 对象。
当一个可序列化类有多个父类时,包括直接父类和间接父类,这些父类要么有无参数的构造器,要么也是可序列化的——否则反序列化时将抛出
InvalidClassException异常。如果父类是不可序列化的,只是带有无参数的构造器,则该父类中定义的成员变量值不会被序列化到二进制流中。
对象引用的序列化
若某个类是可序列化的,则它的每一个成员变量都必须是可序列化的,否则,该类将不可序列化。
当序列化一个
Teacher对象时,如果该Teacher对象持有一个Person对象的引用,为了在反序列化时可以正确恢复该Teacher对象,程序会顺带将该Person对象也序列化,所以Person类也必须是可序列化的,否则Teacher类将不可序列化。回想上面,
Person类持有一个String类型的name属性,序列化Person时String name当然要被序列化。递归序列化
当对某个对象进行序列化时,系统会自动把该对象的所有实例变量依次进行序列化,如果某个实例变量引用到另一个对象,则被引用的对象也会被序列化;这种情况被称为“递归序列化”。
为了防止重复序列化同一个对象,序列化机制会对每一个序列化的对象进行编号;如果某个对象已经被序列化过,程序将只是直接输出一个序列化编号,而不是再次序列化该对象。
这样可能引起一个潜在的问题——某个对象在序列化之后的修改将不会再次被输出。
使用transient关键字避免对某个实例变量的序列化:
private transient int age;
serialVersionUID
根据前面的介绍可以知道,反序列化 Java 对象时必须提供该对象的 class 文件,现在的问题是,随着项目的升级,系统的 class 文件也会升级,Java 如何保证两个 class 文件的兼容性?
Java 序列化机制允许为序列化类提供一个 private static final 的 serialVersionUID 值,该值用于标识该 Java 类的序列化版本,也就是说,如果一个类升级后,只要它的 serialVersionUID 保持不变,序列化机制就会把它们当做同一个序列化版本。
NIO & NIO.2
略。看印象笔记和书。
java.nio.file.Path/Paths/Files
早期的 Java 只提供了一个 File 类来访问文件系统,但 File 类的功能比较有限,它不能利用特定文件系统的特性,File 类所提供的的方法的性能也不高。而且,其大多数方法在出错时仅返回失败,并不会提供异常信息。
Java 7 的 NIO.2 为了弥补这种不足,引入了一个 Path 接口,代表一个平台无关的路径。除此之外,NIO.2 还提供了 Paths、Files 两个工具类,其中 Files 包含大量静态的工具方法来操作文件;Paths 则包含两个返回 Path 的静态工厂方法。
Path 接口也提供了一堆类似(or 增强)File 类的功能,为避免混淆,略。
Paths 工具类只有两个 get 方法,用来生成 Path ,同略。
Files
Files 类是一个高度封装的工具类,它提供了大量的工具方法来完成文件复制、读取文件内容、写入文件内容等功能——这些原本需要通过 IO 操作才能完成的功能,用 Files 工具类可以很方便、优雅的完成。
使用 Files 可以大大简化文件 IO.
一个前提:Files 的工具方法都是与 Path 配合使用的,好在 File 有个 toPath() 方法,这样就可以将 Files 与 File 衔接起来用。
-
copy(InputStream in, Path target, CopyOption... options):复制输入流中的内容到文件; -
copy(Path source, OutputStream out):复制文件的内容到输出流; -
copy(Path source, Path target, CopyOption... options):复制文件的内容到另一个文件; -
createDirectories(Path dir, FileAttribute... attrs):File.mkdirs() -
createDirectory(Path dir, FileAttribute... attrs):File.mkdir() -
createFile(Path path, FileAttribute... attrs):File.createNewFile() -
delete(Path path)/deleteIfExists(Path path)/exists(Path path, LinkOption... options):File.delete()/File.exists() -
static Stream:Return a Stream that is lazily populated with Path by searching for files in a file tree rooted at a given starting file.find(Path start, int maxDepth, BiPredicate
但是用Files.find()的时候遇到了问题:

遇到没有权限的文件夹,直接抛出异常退出了,不能跳过继续遍历。
最后的FileVisitOption是一个枚举值,但它总共只有一个FOLLOW_LINKS啊!!!毛用没有!!!
-
getLastModifiedTime(Path path, LinkOption... options):File.lastModified() -
isDirectory(Path path, LinkOption... options):File.isDirectory() -
isExecutable(Path path), isHidden(Path path), isReadable(Path path), isRegularFile(Path path, LinkOption... options), isSameFile(Path path, Path path2), isSymbolicLink(Path path), isWritable(Path path): -
Stream:读取文件内所有的行;lines(Path path[, Charset cs]) -
List:上面返回的是流,这里返回的是readAllLines(Path path[, Charset cs]) List; -
write(Path path, byte[] bytes, OpenOption... options):方便的写数据; -
write(Path path, Iterable lines, [Charset cs, ]OpenOption... options):将多行数据写入文件; -
Stream:File.listFiles()list(Path dir) -
move(Path source, Path target, CopyOption... options):移动文件到新的路径; -
BufferedReader newBufferedReader(Path path[, Charset cs]):将文件打开为BufferedReader流;等价于new BufferedReader(new InputStreamReader(new FileInputStream(File file, String cs)));只不过要快捷的多! -
BufferedWriter newBufferedWriter(Path path[, Charset cs], OpenOption... options):恩,快捷; -
InputStream newInputStream(Path path, OpenOption... options):同上; -
OutputStream newOutputStream(Path path, OpenOption... options): -
DirectoryStream:以 Path 流的方式返回目标路径的所有子路径;newDirectoryStream(Path dir, DirectoryStream.Filter filter) -
String probeContentType(Path path):探测文件类型; -
long size(Path path):File.length()
接下来是遍历路径 walk/walkFileTree
-
Stream:这里用的也是walk(Path start, [int maxDepth, ]FileVisitOption... options) FileVisitOption,和上面find的问题一样:遇到没有访问权限的路径就直接抛出异常退出,没法让它继续下去; -
Path walkFileTree(Path start, [Set:这里用的是options, int maxDepth, ]FileVisitor visitor) FileVisitor,它能对访问成功/失败、打开路径前/后的情况做很细致的控制,遍 历 路 径 就 是 它 了 !
File root = new File("C:/");
final int[] pathCnt = {0};
Files.walkFileTree(root.toPath(), new SimpleFileVisitor(){
// 访问一个目录前调用;
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException {
System.out.println(dir);
++pathCnt[0];
return super.preVisitDirectory(dir, attrs);
}
// 访问文件前调用;
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println(file);
++pathCnt[0];
return super.visitFile(file, attrs);
}
// 访 问 文 件 失 败 ,或 者 目 录 不 可 打 开 ,时调用;所以改写的关键地方在这里;
@Override
public FileVisitResult visitFileFailed(Path file, IOException exc) throws IOException {
// 默认行为是简单的抛出 exc;
// return super.visitFileFailed(file, exc);
exc.printStackTrace();
// try {
// Thread.sleep(5000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
return FileVisitResult.CONTINUE;
}
// dir的所有 子 孙 路径都被访问完毕后,调用此方法;
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
return super.postVisitDirectory(dir, exc);
}
});
System.out.println(pathCnt[0]);
===========================================================
public class SimpleFileVisitor implements FileVisitor {
/**
* Initializes a new instance of this class.
*/
protected SimpleFileVisitor() {
}
/**
* Invoked for a directory before entries in the directory are visited.
*
* Unless overridden, this method returns {@link FileVisitResult#CONTINUE
* CONTINUE}.
*/
@Override
public FileVisitResult preVisitDirectory(T dir, BasicFileAttributes attrs)
throws IOException
{
Objects.requireNonNull(dir);
Objects.requireNonNull(attrs);
return FileVisitResult.CONTINUE;
}
/**
* Invoked for a file in a directory.
*
*
Unless overridden, this method returns {@link FileVisitResult#CONTINUE
* CONTINUE}.
*/
@Override
public FileVisitResult visitFile(T file, BasicFileAttributes attrs)
throws IOException
{
Objects.requireNonNull(file);
Objects.requireNonNull(attrs);
return FileVisitResult.CONTINUE;
}
/**
* Invoked for a file that could not be visited.
*
*
Unless overridden, this method re-throws the I/O exception that prevented
* the file from being visited.
*/
@Override
public FileVisitResult visitFileFailed(T file, IOException exc)
throws IOException
{
Objects.requireNonNull(file);
throw exc;
}
/**
* Invoked for a directory after entries in the directory, and all of their
* descendants, have been visited.
*
*
Unless overridden, this method returns {@link FileVisitResult#CONTINUE
* CONTINUE} if the directory iteration completes without an I/O exception;
* otherwise this method re-throws the I/O exception that caused the iteration
* of the directory to terminate prematurely.
*/
@Override
public FileVisitResult postVisitDirectory(T dir, IOException exc)
throws IOException
{
Objects.requireNonNull(dir);
if (exc != null)
throw exc;
return FileVisitResult.CONTINUE;
}
}
多线程
进程是资源分配的基本单位,线程是任务调度的基本单位。
线程共享进程的内存、文件句柄等资源。
使用多线程来实现并发要比使用多进程实现并发的性能高得多。(?)
继承 Thread 类创建线程
public class ReviewJava {
public static void main(String[] args) {
new MyThread().start();
System.out.println("开启线程是瞬间的!不是阻塞到它执行完!");
}
}
class MyThread extends Thread {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println("In Thread, println: " + i);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
java.lang.Thread:
-
Thread([ThreadGroup group,] [Runnable target,] [String name]):构造方法; -
static Thread currentThread():获取当前线程; -
getName():线程名,默认是 main, Thread-0, Thread-1... -
int getPriority()/setPriority(int newPriority):线程优先级; -
ThreadGroup getThreadGroup():获取所属的线程组; -
setDaemon()/isDaemon():守护线程; -
join([long millis]):等待线程执行完; -
static void sleep(long millis):睡觉;
实现 Runnable 接口创建线程
- 实现 Runnable 接口,重写 run() 方法;
- 创建实例并作为 Thread 实例的 target:
new Thread(target).start()
多个线程可以共享同一个 target,该 target 的实例变量可以在多个线程间共享。But 这样好吗?书上说好!你说呢?
public class ReviewJava {
public static void main(String[] args) {
// 两个线程共享同一个target;
MyThread target = new MyThread();
new Thread(target).start();
new Thread(target).start();
}
}
class MyThread implements Runnable {
private int i = 0;
@Override
public void run() {
for (; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + ": " + i);
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
output:
Thread-1: 0 // 几乎同时进入循环0,所以;
Thread-0: 0 // 几乎同时进入循环0,所以;
Thread-0: 1
Thread-1: 2
Thread-1: 3
Thread-0: 4
Thread-1: 5
Thread-0: 6
Thread-0: 7
Thread-1: 8
Thread-0: 9
使用 Callable 和 Future 创建线程
可以有返回值,可以抛出异常,但比前两种稍显复杂。
线程以以下三种方法结束:
- run() 或 call()(Callable 接口) 方法执行完,线程正常结束;
- 线程抛出一个未捕获的异常;
- 直接调用 stop() 方法来结束线程——该方法容易导致死锁,通常不推荐使用。
通过调用一个线程对象的 join() 方法来等待其执行完成。
Daemon Thread,守护线程,当所有前台线程都死亡时,后台线程(守护线程)会自动死亡。JVM 的垃圾回收线程就是典型的守护线程。(setDaemon())
主线程默认是前台线程,前台线程创建的子线程默认是前台线程;后台线程创建的子线程默认是后台线程。
线程同步
同步监视器/同步代码块
synchronized(obj) {
...
}
obj 就是同步监视器;线程开始执行同步代码块之前必须获得对同步监视器的锁定。
将上面的代码修改为:
public void run() {
synchronized (i) {
for (; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + ": " + i);
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
output:
Thread-0: 0
Thread-0: 1
Thread-0: 2
Thread-0: 3
Thread-0: 4
Thread-0: 5
Thread-0: 6
Thread-0: 7
Thread-0: 8
Thread-0: 9
就不会出现两个线程同时进入循环0的情况了。
同步方法
同步方法的同步监视器是 this。
public synchronized void run() {
同步锁(Lock)
可以实现更灵活的锁机制,lock()/unlock(),略。
死锁
两个线程相互等待对方释放锁时就会发生死锁,Java 虚拟机没有监测,也没有采取措施来处理死锁情况,所以多线程编程时只能避免死锁出现。一旦出现死锁,整个程序既不会发生任何异常,也不会给出任何提示。
线程间通信
-
wait()/notify()/notifyAll(),略。 - 使用 Lock 对象来同步时,要配合 Condition 来控制线程通信。
- 使用阻塞队列(BlockingQueue)来控制线程间通信
阻塞队列满时,添加操作会被阻塞;空时取操作被阻塞;通过向阻塞队列的存取(put(E e)/take())来实现线程间通信。
线程组 ThreadGroup
用来对线程进行批量管理。默认情况下,子线程和创建它的父线程处于同一线程组。
Thread([ThreadGroup group,] [Runnable target,] [String name])
-
int activeCount():返回此线程组中活动线程的数目;
线程池
略。
线程安全的集合类
- 通过包装;
Map m = Collections.synchronizedMap(new HashMap()) - Java 5 提供的,在 java.util.concurrent 包下的大量支持高效并发访问的集合接口和实现类;
ConcurrentHashMap, CopyOnWriteArrayList...
网络编程
书上讲的是,,,额,,,还是略好了。
集合与数组的转换
Collections.addAll(Collection c, T... elements) 一次性添加多个元素到集合;
Collection.toArray() 返回一个重新分配空间的数组(看清楚是 Collection接口);
Arrays.asList(T... a) 返回一个固定长度的List;
补充
stream 流式编程——未
不可变类
不可变类:当你获得这个类的一个实例引用时,你不可以改变这个实例的内容。不可变类的实例一但创建,其内在成员变量的值就不能被修改。
举个例子:String 和 StringBuilder,String 是 immutable 的,每次对于 String 对象的修改都将产生一个新的 String 对象,而原来的对象保持不变,而 StringBuilder 是 mutable,因为每次对于它的对象的修改都作用于该对象本身,并没有产生新的对象。
不可变类的好处:
- 线程安全,可以不用被 synchroinzed 就在并发环境中共享,无需使用额外的锁机制(简化编程模型);
- 提高性能,可以被缓存起来重复使用;例如对字符串字面值的缓存;
immutable 也有一个缺点就是会制造大量垃圾,由于他们不能被重用而且对于它们的使用就是”用“然后”扔“,字符串就是一个典型的例子,它会创造很多的垃圾,给垃圾收集带来很大的麻烦。当然这只是个极端的例子,合理的使用 immutable 对象会创造很大的价值。
如何实现不可变类?
- immutable对象的状态在创建之后就不能发生改变,任何对它的改变都应该产生一个新的对象。
- Immutable类的所有的属性都应该是final的。
- 对象必须被正确的创建,比如:对象引用在对象创建过程中不能泄露(leak)。
- 对象应该是final的,以此来限制子类继承父类,以避免子类改变了父类的immutable特性。
- 如果类中包含mutable类对象,那么返回给客户端的时候,返回该对象的一个拷贝,而不是该对象本身(该条可以归为第一条中的一个特例)
其他
-
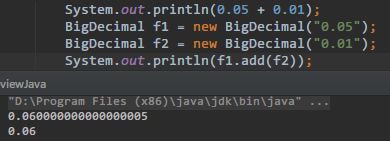
java.math.BigDecimal:高精度数字,解决Double不够精确的问题; -
注意点(坑)

作用域问题。Java 的作用域和 C/C++ 是很相似的,try 块中的变量,在 finally 块中访问不到。
两个new String("语文")对象,虽然内容是一样的,但是是不同的对象!地址不一样!理解!
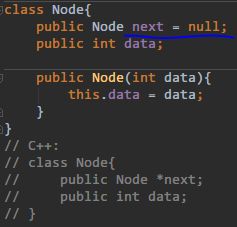
Java 如何实现链表结构?引用的概念还不够刻骨铭心啊!
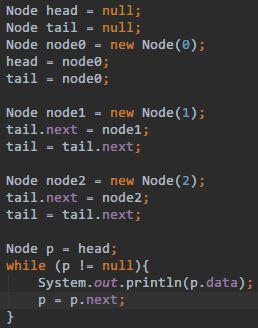

Collection.toArray()返回的是Object[]类型,Object[]是不能转换为String[]类型的。数组里面的每一个元素都是Object,不是仅仅强转一个引用就行的。
所有的 包 装 类 也都是 不 可 变 类 !!
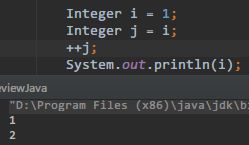
基本类型(如 int)的数值和包装类(Integer)之间是可以自动“装箱拆箱”的,但在需要使用类型参数 T 地方,int 是不能自动转为 Integer 的,必须手动修改。
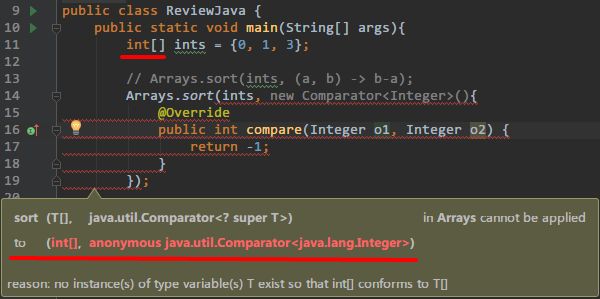
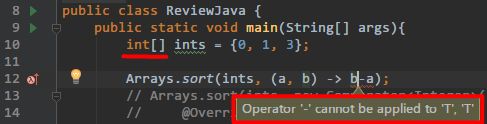
换为 Integer 后全都消停了: