
- 前言:
在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大部分内容参照自这一篇文章,有一些自己补充的,也算是重新学习一下 Java 吧。
前序文章链接:
Java 面试知识点解析(一)——基础知识篇
Java 面试知识点解析(二)——高并发编程篇
Java 面试知识点解析(三)——JVM篇
对于 Java 各个版本的特性,特别是 Java 8 的新知识点,我们都应该有所了解。
前排申明和好文推荐:闪烁之狐 » Java5新特性及使用 » Java6新特性及使用 » Java7新特性及使用 » Java8新特性及使用(一) » Java8新特性及使用(二)
(一)Java 5 相关知识点
参考文章:jdk 1.5新特性
1)增强型 for 循环:
答:增强 for 循环:foreach 语句,foreach 简化了迭代器。
格式:// 增强for循环括号里写两个参数,第一个是声明一个变量,第二个就是需要迭代的容器
for( 元素类型 变量名 : Collection集合 & 数组 ) {
…
}
语法:
for ( type 变量名:集合变量名 ) { … }
注意事项:
- 迭代变量必须在( )中定义!
- 集合变量可以是数组或实现了Iterable接口的集合类。
高级for循环和传统for循环的区别:
高级for循环在使用时,必须要明确被遍历的目标。这个目标,可以是Collection集合或者数组,如果遍历Collection集合,在遍历过程中还需要对元素进行操作,比如删除,需要使用迭代器。
如果遍历数组,还需要对数组元素进行操作,建议用传统for循环因为可以定义角标通过角标操作元素。如果只为遍历获取,可以简化成高级for循环,它的出现为了简化书写。比起普通的for循环,高级for循环还有性能优势,因为它对数组索引的边界值只计算一次(摘自《Effective Java》第46条)。
高级for循环可以遍历map集合吗?
答:原则上map集合是无法使用增强for循环来迭代的,因为增强for循环只能针对实现了Iterable接口的集合进行迭代;Iterable是jdk5中新定义的接口,就一个方法iterator方法,只有实现了Iterable接口的类,才能保证一定有iterator方法,java有这样的限定是因为增强for循环内部还是用迭代器实现的,而实际上,我们可以通过某种方式来使用增强for循环。
for(Object obj : map.entrySet()) {
Map.Entry entry = (Entry) obj; // obj 依次表示Entry
System.out.println(entry.getKey() + "=" + entry.getValue());
}
总之,for-each 循环在简洁性和预防 Bug 方面有着传统 for 循环无法比拟的优势,并且没有性能损失。应该尽可能地使用 for-each 循环。遗憾的是,有三种常见的情况是无法使用 for-each 循环的:
过滤——如果需要遍历集合,并删除选定的元素,就需要使用显式地迭代器,以便可以调用它的 remove 方法。
转换——如果需要遍历列表或者数组,并取代它部分或者全部的元素值(增删、或对元素进行赋值),就需要列表迭代器或者数组索引,以便设定元素的值
平行迭代——如果需要并行地遍历多个集合,就需要显式地控制迭代器或者所因变量以便所有迭代器或者索引变量都可以得到同步前移
2)可变参数:
解析:什么意思呢?举个例子:在 JDK 1.5 之前,当我们要为一个传递多个类型相同的参数时,我们有两种方法解决,1.直接传递一个数组过去,2.有多少个参数就传递多少个参数。
例如:
public void printColor(String red,String green,String yellow){
}
// 或者
public void printColor(String[] colors){
}
这样编写方法参数虽然能够实现我们想要的效果,但是,这样是不是有点麻烦呢?再者,如果参数个数不确定,我们怎么办呢?Java JDK1.5为我们提供的可变参数就能够完美的解决这个问题
答:
可变参数(...):用到函数的参数上,当要操作的同一个类型元素个数不确定的时候,可是用这个方式,这个参数可以接受任意个数的同一类型的数据。
和以前接收数组不一样的是:
以前定义数组类型,需要先创建一个数组对象,再将这个数组对象作为参数传递给函数。现在,直接将数组中的元素作为参数传递即可。底层其实是将这些元素进行数组的封装,而这个封装动作,是在底层完成的,被隐藏了。所以简化了用户的书写,少了调用者定义数组的动作。
如果在参数列表中使用了可变参数,可变参数必须定义在参数列表结尾(也就是必须是最后一个参数,否则编译会失败。)。
如果要获取多个int数的和呢?可以使用将多个int数封装到数组中,直接对数组求和即可。
可变参数的特点:
- ① 只能出现在参数列表的最后;
- ② “...” 位于变量类型和变量名之间,前后有无空格都可以;
- ③ 调用可变参数的方法时,编译器为该可变参数隐含创建一个数组,在方法体中以数组的形式访问可变参数。
Public int add(int x, int... args){//也可以直接(int..args)就是说传不传都可以
Int sum = x;
For(int i = 0; i<=args.lengrth;i++){
Sum+=args[i];
}
return sum;
}
实例:
public class VariableParameter {
public static void main(String[] args) {
System. out.println(add(1, 2));
System. out.println(add(1, 2, 3));
}
public static int add(int x, int... args){
int sum = x;
for(int i = 0; i < args.length; i++){
sum += args[i];
}
return sum;
}
}
3)枚举
解析:关键字 enum
答:
问题:对象的某个属性的值不能是任意的,必须为固定的一组取值其中的某一个;
解决办法:
1)在 setGrade 方法中做判断,不符合格式要求就抛出异常;
2)直接限定用户的选择,通过自定义类模拟枚举的方式来限定用户的输入,写一个 Grade 类,私有构造函数,对外提供 5 个静态的常量表示类的实例;
3)jdk5 中新定义了枚举类型,专门用于解决此类问题;
4)枚举就是一个特殊的java类,可以定义属性、方法、构造函数、实现接口、继承类;
为什么要有枚举?
问题:要定义星期几或性别的变量,该怎么定义?假设用1-7分别表示星期一到星期日,但有人可能会写成int weekday = 0;或即使使用常量方式也无法阻止意外。
枚举就是要让某个类型的变量的取值只能为若干个固定值中的一个,否则,编译器就会报错。枚举可以让编译器在编译时就可以控制源程序中填写的非法值,普通变量的方式在开发阶段无法实现这一目标。
用普通类如何实现枚举功能,定义一个Weekday的类来模拟枚举功能。
1、私有的构造方法。
2、每个元素分别用一个公有的静态成员变量表示。
可以有若干公有方法或抽象方法。采用抽象方法定义nextDay就将大量的if.else语句转移成了一个个独立的类
示例:定义一个Weekday的类来模拟枚举功能。
public class WeekDay {
private WeekDay(){}
public static final WeekDay SUN = new WeekDay();
public static final WeekDay MON = new WeekDay();
public WeekDay nextDay(){
if(this == SUN){
return MON ;
} else{
return SUN ;
}
}
public String toString(){
return this == SUN? "SUN":"MON" ;
}
}
public class EnumTest {
public static void main(String[] args) {
WeekDay day = WeekDay.MON;
System. out.println(day.nextDay());
//结果:SUN
}
}
使用枚举类实现
public class EnumTest {
public static void main(String[] args) {
WeekDay day = WeekDay.FRI;
System.out.println(day);
//结果:FRI
System.out.println(day.name());
//结果:FRI
System.out.println(day.ordinal());
//结果:5
System.out.println(WeekDay. valueOf("SUN"));
//结果:SUN
System.out.println(WeekDay. values().length);
//结果:7
}
public enum WeekDay{
SUN,MON ,TUE,WED, THI,FRI ,SAT;
}
}
总结: 枚举是一种特殊的类,其中的每个元素都是该类的一个实例对象,例如可以调用WeekDay.SUN.getClass().getName 和 WeekDay.class.getName()。
注意: 最后一个枚举元素后面可以加分号,也可以不加分号。
实现带有构造方法的枚举
- 枚举就相当于一个类,其中也可以定义构造方法、成员变量、普通方法和抽象方法。
- 枚举元素必须位于枚举体中的最开始部分,枚举元素列表的最后要有分号与其他成员分隔。把枚举中的成员方法或变量等放在枚举元素的前面,编译器会报告错误。
- 带构造方法的枚举:
构造方法必须定义成私有的
如果有多个构造方法,将根据枚举元素创建时所带的参数决定选择哪个构造方法创建对象。
枚举元素 MON 和 MON() 的效果一样,都是调用默认的构造方法。
示例:
public class EnumTest {
public static void main(String[] args) {
WeekDay day = WeekDay.FRI;
}
public enum WeekDay{
SUN(1),MON (),TUE, WED,THI ,FRI,SAT;
private WeekDay(){
System. out.println("first" );
}
private WeekDay(int value){
System. out.println("second" );
}
//结果:
//second
//first
//first
//first
//first
//first
//first
}
}
实现带有抽象方法的枚举
定义枚举TrafficLamp,实现抽象的nextTrafficLamp方法:每个元素分别是由枚举类的子类来生成的实例对象,这些子类采用类似内部类的方式进行定义。增加上表示时间的构造方法。
public class EnumTest {
public static void main(String[] args) {
TrafficLamp lamp = TrafficLamp.RED;
System.out.println(lamp.nextLamp());
//结果:GREEN
}
public enum TrafficLamp {
RED(30) {
public TrafficLamp nextLamp() {
return GREEN;
}
}, GREEN(45) {
public TrafficLamp nextLamp() {
return YELLOW;
}
}, YELLOW(5) {
public TrafficLamp nextLamp() {
return RED;
}
};
private int time;
private TrafficLamp(int time) {
this.time = time;
}
public abstract TrafficLamp nextLamp();
}
}
注意:
1、枚举只有一个成员时,就可以作为一种单例的实现方式。
2、查看生成的class文件,可以看到内部类对应的class文件。
4)自动拆装箱
答:在 Java 中数据类型分为两种:基本数据类型、引用数据类型(对象)
自动装箱:把基本类型变成包装器类型,本质是调用包装器类型的valueOf()方法
注意:基本数据类型的数组与包装器类型数组不能互换
在 java程序中所有的数据都需要当做对象来处理,针对8种基本数据类型提供了包装类,如下:
int → Integer
byte → Byte
short → Short
long → Long
char → Character
double → Double
float → Float
boolean → Boolean
在 jdk 1.5 以前基本数据类型和包装类之间需要相互转换:
基本---引用 Integer x = new Integer(x);
引用---基本 int num = x.intValue();
1)Integer x = 1; x = x + 1; 经历了什么过程?装箱→拆箱→装箱
2)为了优化,虚拟机为包装类提供了缓冲池,Integer池的大小为 -128~127 一个字节的大小。String池:Java 为了优化字符串操作也提供了一个缓冲池;
→ 享元模式(Flyweight Pattern):享元模式的特点是,复用我们内存中已经存在的对象,降低系统创建对象实例。
自动装箱:
Integer num1 = 12;
自动拆箱:
System.out.println(num1 + 12);
基本数据类型的对象缓存:
Integer num1 = 12;
Integer num2 = 12;
System.out.println(num1 == num2);//ture
Integer num3 = 129;
Integer num4 = 129;
System.out.println(num3 == num4);//false
Integer num5 = Integer.valueOf(12);
Integer num6 = Integer.valueOf(12);
System.out.println(num5 == num6);//true
示例:
public class AutoBox {
public static void main(String[] args) {
//装箱
Integer iObj = 3;
//拆箱
System. out.println(iObj + 12);
//结果:15
Integer i1 = 13;
Integer i2 = 13;
System. out.println(i1 == i2);
//结果:true
i1 = 137;
i2 = 137;
System. out.println(i1 == i2);
//结果:false
}
}
注意:
如果有很多很小的对象,并且他们有相同的东西,那就可以把他们作为一个对象。
如果还有很多不同的东西,那就可以作为外部的东西,作为参数传入。
这就是享元设计模式(flyweight)。
例如示例中的Integer对象,在-128~127范围内的Integer对象,用的频率比较高,就会作为同一个对象,因此结果为true。超出这个范围的就不是同一个对象,因此结果为false。
5)泛型 Generics
答:引用泛型之后,允许指定集合里元素的类型,免去了强制类型转换,并且能在编译时刻进行类型检查的好处。Parameterized Type作为参数和返回值,Generic是vararg、annotation、enumeration、collection的基石。
泛型可以带来如下的好处总结如下:
- 类型安全:抛弃List、Map,使用List、Map给它们添加元素或者使用Iterator遍历时,编译期就可以给你检查出类型错误
- 方法参数和返回值加上了Type: 抛弃List、Map,使用List、Map
- 不需要类型转换:List list = new ArrayList();
- 类型通配符“?”: 假设一个打印List中元素的方法printList,我们希望任何类型T的List都可以被打印
6)静态导入
答:静态导入:导入了类中的所有静态成员,简化静态成员的书写。
import语句可以导入一个类或某个包中的所有类
import static语句导入一个类中的某个静态方法或所有静态方法
import static java.util.Collections.*; //导入了Collections类中的所有静态成员
静态导入可以导入静态方法,这样就不必写类名而可以直接调用静态方法了。
例子:
原来的:
public class Demo12 {
public static void main(String[] args) {
System.out.println(Math.max(12, 15));
System. out.println(Math.abs(3-6));
}
}
使用静态导入的:
import static java.lang.Math.max ;
import static java.lang.Math.abs ;
public class Demo12 {
public static void main(String[] args) {
System.out.println(max(12, 15));
System. out.println(abs(3-6));
}
}
注意:
1、也可以通过import static java.lang.Math.*;导入Math类下所有的静态方法。
2、如果将javac设置为了Java5以下,那么静态导入等jdk1.5的特性都会报告错误。
7)新的线程模型和并发库Thread Framework(重要)
答: 最主要的就是引入了 java.util.concurrent 包,这个都是需要重点掌握的。
HashMap 的替代者 ConcurrentHashMap 和 ArrayList 的替代者 CopyOnWriteArrayList 在大并发量读取时采用 java.util.concurrent 包里的一些类会让大家满意 BlockingQueue、Callable、Executor、Semaphore
8)内省(Introspector)
答:是 Java 语言对 Bean 类属性、事件的一种缺省处理方法。例如类 A 中有属性 name , 那我们通过 getName,setName 来得到其值或者设置新的值。通过 getName/setName 来访问name属性,这就是默认的规则。Java 中提供了一套 API 用来访问某个属性的 getter /setter 方法,通过这些 API 可以使你不需要了解这个规则(但你最好还是要搞清楚),这些 API 存放于包 java.beans 中。
一般的做法是通过类 Introspector 来获取某个对象的 BeanInfo 信息,然后通过 BeanInfo 来获取属性的描述器 (PropertyDescriptor),通过这个属性描述器就可以获取某个属性对应的 getter/setter 方法,然后我们就可以通过反射机制来 调用这些方法。
扩展阅读:java Introspector(内省) 的介绍
9)注解(Annotations)
答:
注解(Annotation)是一种应用于类、方法、参数、变量、构造器及包声明中的特殊修饰符,它是一种由JSR-175标准选择用来描述元数据的一种工具。Java从Java5开始引入了注解。在注解出现之前,程序的元数据只是通过java注释和javadoc,但是注解提供的功能要远远超过这些。注解不仅包含了元数据,它还可以作用于程序运行过程中、注解解释器可以通过注解决定程序的执行顺序。
比如,下面这段代码:
@Override
public String toString() {
return "This is String.";
}
上面的代码中,我重写了toString()方法并使用了@Override注解。但是,即使我们不使用@Override注解标记代码,程序也能够正常执行。那么,该注解表示什么?这么写有什么好处吗?事实上,@Override告诉编译器这个方法是一个重写方法(描述方法的元数据),如果父类中不存在该方法,编译器便会报错,提示该方法没有重写父类中的方法。如果我不小心拼写错误,例如将toString()写成了toStrring(){double r},而且我也没有使用@Override注解,那程序依然能编译运行。但运行结果会和我期望的大不相同。现在我们了解了什么是注解,并且使用注解有助于阅读程序。
为什么要引入注解?
使用注解之前(甚至在使用之后),XML被广泛的应用于描述元数据。不知何时开始一些应用开发人员和架构师发现XML的维护越来越糟糕了。他们希望使用一些和代码紧耦合的东西,而不是像XML那样和代码是松耦合的(在某些情况下甚至是完全分离的)代码描述。如果你在Google中搜索“XML vs. annotations”,会看到许多关于这个问题的辩论。最有趣的是XML配置其实就是为了分离代码和配置而引入的。上述两种观点可能会让你很疑惑,两者观点似乎构成了一种循环,但各有利弊。下面我们通过一个例子来理解这两者的区别。
假如你想为应用设置很多的常量或参数,这种情况下,XML是一个很好的选择,因为它不会同特定的代码相连。如果你想把某个方法声明为服务,那么使用注解会更好一些,因为这种情况下需要注解和方法紧密耦合起来,开发人员也必须认识到这点。
另一个很重要的因素是注解定义了一种标准的描述元数据的方式。在这之前,开发人员通常使用他们自己的方式定义元数据。例如,使用标记接口,注释,transient关键字等等。每个程序员按照自己的方式定义元数据,而不像注解这种标准的方式。
目前,许多框架将XML和Annotation两种方式结合使用,平衡两者之间的利弊。
参考文章(更多注解戳这里):Java注解的理解和应用
10)新增 ProcessBuilder 类
答:
ProcessBuilder 类是 Java5 在 java.lang 包中新添加的一个新类,此类用于创建操作系统进程,它提供一种启动和管理进程(也就是应用程序)的方法。在此之前,都是由 Process 类处来实现进程的控制管理。每个 ProcessBuilder 实例管理一个进程属性集。它的 start() 方法利用这些属性创建一个新的 Process 实例。start() 方法可以从同一实例重复调用,以利用相同的或相关的属性创建新的子进程。
ProcessBuilder 是一个 final 类,有两个带参数的构造方法,你可以通过构造方法来直接创建 ProcessBuilder 的对象。而 Process 是一个抽象类,一般都通过 Runtime.exec() 和 ProcessBuilder.start() 来间接创建其实例。ProcessBuilder 为进程提供了更多的控制,例如,可以设置当前工作目录,还可以改变环境参数。而 Process 类的功能相对来说简单的多。ProcessBuilder 类不是同步的。如果多个线程同时访问一个 ProcessBuilder,而其中至少一个线程从结构上修改了其中一个属性,它必须保持外部同步。
若要使用 ProcessBuilder 创建一个进程,只需要创建 ProcessBuilder 的一个实例,指定该进程的名称和所需参数。要执行此程序,调用该实例上的 start() 即可。下面是一个执行打开 Windows 记事本的例子。注意它将要编辑的文件名指定为一个参数。
class PBDemo {
public static void main(String args[]) {
try {
ProcessBuilder proc = new ProcessBuilder("notepad.exe", "testfile");
proc.start();
} catch (Exception e) {
System.out.println("Error executing notepad.");
}
}
}
参考文章:Java5新特性及使用
11)新增Formatter格式化器(Formatter)
Formatter 类是Java5中新增的 printf-style 格式化字符串的解释器,它提供对布局和对齐的支持,提供了对数字,字符串和日期/时间数据的常用格式以及特定于语言环境的输出。常见的 Java 类型,如 byte,java.math.BigDecimal 和 java.util.Calendar 都支持。 通过 java.util.Formattable 接口提供了针对任意用户类型的有限格式定制。
更详细的介绍见这里。主要使用方法的代码示例如下:
import java.io.BufferedReader;
import java.io.FileReader;
import java.text.MessageFormat;
import java.text.SimpleDateFormat;
import java.util.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 格式化测试使用的示例类.
*
* @author blinkfox on 2017-11-28.
*/
public class FormatTester {
private static final Logger log = LoggerFactory.getLogger(FormatTester.class);
/**
* 格式化.
*/
private static void formatter() {
StringBuilder sb = new StringBuilder();
Formatter formatter = new Formatter(sb, Locale.US);
// 可重新排序输出.
formatter.format("%n%4$2s %3$2s %2$2s %1$2s %n", "a", "b", "c", "d"); // -> " d c b a"
formatter.format(Locale.FRANCE, "e = %+10.4f", Math.E); // -> "e = +2,7183"
formatter.format("%nAmount gained or lost since last statement: $ %(,.2f", 6217.58);
// -> "Amount gained or lost since last statement: $ 6,217.58"
log.info("打印出格式化后的字符串:{}", formatter);
formatter.close();
}
/**
* printf打印.
*/
private static void printf() {
String filename = "testfile";
try (FileReader fileReader = new FileReader(filename)) {
BufferedReader reader = new BufferedReader(fileReader);
String line;
int i = 1;
while ((line = reader.readLine()) != null) {
System.out.printf("Line %d: %s%n", i++, line);
}
} catch (Exception e) {
System.err.printf("Unable to open file named '%s': %s", filename, e.getMessage());
}
}
/**
* stringFormat使用.
*/
private static void stringFormat() {
// 格式化日期.
Calendar c = new GregorianCalendar(1995, Calendar.MAY, 23);
String s = String.format("Duke's Birthday: %1$tm %1$te,%1$tY", c);
// -> s == "Duke's Birthday: May 23, 1995"
log.info(s);
}
/**
* 格式化消息.
*/
private static void messageFormat() {
String msg = "欢迎光临,当前({0})等待的业务受理的顾客有{1}位,请排号办理业务!";
MessageFormat mf = new MessageFormat(msg);
String fmsg = mf.format(new Object[]{new Date(), 35});
log.info(fmsg);
}
/**
* 格式化日期.
*/
private static void dateFormat() {
String str = "2010-1-10 17:39:21";
SimpleDateFormat format = new SimpleDateFormat("yyyyMMddHHmmss");
try {
log.info("格式化后的日期:{}", format.format(format.parse(str)));
} catch (Exception e) {
log.error("日期格式化出错!", e);
}
}
public static void main(String[] args) {
formatter();
stringFormat();
messageFormat();
dateFormat();
printf();
}
}
参考文章:Java5新特性及使用
12)新增 Scanner 类(Scanner)
java.util.Scanner 是 Java5 的新特征,主要功能是简化文本扫描,但这个类最实用的地方还是在获取控制台输入。
(1).Scanner概述
可以从字符串(Readable)、输入流、文件、Channel等来直接构造Scanner对象,有了Scanner了,就可以逐段(根据正则分隔式)来扫描整个文本,并对扫描后的结果做想要的处理。
Scanner 默认使用空格作为分割符来分隔文本,但允许你使用 useDelimiter(Pattern pattern) 或 useDelimiter(String pattern) 方法来指定新的分隔符。
主要API如下:
-
delimiter(): 返回此Scanner当前正在用于匹配分隔符的Pattern。 -
hasNext(): 判断扫描器中当前扫描位置后是否还存在下一段。 -
hasNextLine(): 如果在此扫描器的输入中存在另一行,则返回true。 -
next(): 查找并返回来自此扫描器的下一个完整标记。 -
nextLine(): 此扫描器执行当前行,并返回跳过的输入信息。
(2).扫描控制台输入
当通过 new Scanner(System.in) 创建了一个 Scanner 实例时,控制台会一直等待输入,直到敲回车键结束,把所输入的内容传给 Scanner,作为扫描对象。如果要获取输入的内容,则只需要调用 Scanner 的 nextLine() 方法即可。
/**
* 扫描控制台输入.
*
* @author blinkfox 2017-11-28
*/
public class ScannerTest {
public static void main(String[] args) {
Scanner s = new Scanner(System.in);
System.out.println("请输入字符串:");
while (true) {
String line = s.nextLine();
if (line.equals("exit")) break;
System.out.println(">>>" + line);
}
}
}
(3).其它示例
该示例中会从 myNumbers 文件中读取长整型 long 的数据。
Scanner sc = new Scanner(new File("myNumbers"));
while (sc.hasNextLong()) {
long aLong = sc.nextLong();
}
以下示例可以使用除空格之外的分隔符来从一个字符串中读取几个条目:
String input = "1 fish 2 fish red fish blue fish";
Scanner s = new Scanner(input).useDelimiter("\\s*fish\\s*");
System.out.println(s.nextInt());
System.out.println(s.nextInt());
System.out.println(s.next());
System.out.println(s.next());
s.close();
将输出:
1
2
red
blue
参考文章:Java5新特性及使用
13)StringBuilder
StringBuilder 也是 Java5 中新增的类,主要用来代替 + 号和 StringBuffer 来更加高效的拼接字符串。StringBuffer 与 StringBuilder 都是继承于 AbstractStringBuilder,主要的区别就是 StringBuffer 的函数上都有 synchronized 关键字,保证线程安全。
关于 StringBuilder 的使用这里就不再详细介绍了,网上文章也有很多。总之,对于动态字符串的拼接推荐使用 StringBuilder。静态字符串的拼接直接使用 + 号或者字符串的 concat(String str) 方法,甚至也使用 StringBuilder 亦可。
参考文章:Java5新特性及使用
(二)Java 6 相关知识点
关于 JDK 1.6 的新特性,了解一下就可以了...如果有兴趣深入研究的童鞋,右转这里:Java6新特性及使用
1)Desktop 类和 SystemTray 类:
答:
在JDK6中 ,AWT新增加了两个类:Desktop 和 SystemTray 。
前者可以用来打开系统默认浏览器浏览指定的 URL,打开系统默认邮件客户端给指定的邮箱发邮件,用默认应用程序打开或编辑文件(比如,用记事本打开以txt为后缀名的文件),用系统默认的打印机打印文档;
后者可以用来在系统托盘区创建一个托盘程序.
2)使用 JAXB2 来实现对象与 XML 之间的映射
答:
JAXB是Java Architecture for XML Binding的缩写,可以将一个Java对象转变成为XML格式,反之亦然。
我们把对象与关系数据库之间的映射称为ORM, 其实也可以把对象与XML之间的映射称为OXM(Object XML Mapping). 原来JAXB是Java EE的一部分,在JDK6中,SUN将其放到了Java SE中,这也是SUN的一贯做法。
JDK6中自带的这个JAXB版本是2.0, 比起1.0(JSR 31)来,JAXB2(JSR 222)用JDK5的新特性Annotation来标识要作绑定的类和属性等,这就极大简化了开发的工作量。
实际上,在Java EE 5.0中,EJB和Web Services也通过Annotation来简化开发工作。另外,JAXB2在底层是用StAX(JSR 173)来处理XML文档。除了JAXB之外,我们还可以通过XMLBeans和Castor等来实现同样的功能。
3)理解StAX
答:
StAX(JSR 173)是JDK6.0中除了DOM和SAX之外的又一种处理XML文档的API。
StAX 的来历 :在JAXP1.3(JSR 206)有两种处理XML文档的方法:DOM(Document Object Model)和SAX(Simple API for XML).
由 于JDK6.0中的JAXB2(JSR 222)和JAX-WS 2.0(JSR 224)都会用到StAX,所以Sun决定把StAX加入到JAXP家族当中来,并将JAXP的版本升级到1.4(JAXP1.4是JAXP1.3的维护版本). JDK6里面JAXP的版本就是1.4. 。
StAX是The Streaming API for XML的缩写,一种利用拉模式解析(pull-parsing)XML文档的API.StAX通过提供一种基于事件迭代器(Iterator)的API让 程序员去控制xml文档解析过程,程序遍历这个事件迭代器去处理每一个解析事件,解析事件可以看做是程序拉出来的,也就是程序促使解析器产生一个解析事件,然后处理该事件,之后又促使解析器产生下一个解析事件,如此循环直到碰到文档结束符;
SAX也是基于事件处理xml文档,但却是用推模式解析,解析器解析完整个xml文档后,才产生解析事件,然后推给程序去处理这些事件;DOM 采用的方式是将整个xml文档映射到一颗内存树,这样就可以很容易地得到父节点和子结点以及兄弟节点的数据,但如果文档很大,将会严重影响性能。
4)使用Compiler API
答:
现在我们可以用JDK6 的Compiler API(JSR 199)去动态编译Java源文件,Compiler API结合反射功能就可以实现动态的产生Java代码并编译执行这些代码,有点动态语言的特征。
这个特性对于某些需要用到动态编译的应用程序相当有用,比如JSP Web Server,当我们手动修改JSP后,是不希望需要重启Web Server才可以看到效果的,这时候我们就可以用Compiler API来实现动态编译JSP文件,当然,现在的JSP Web Server也是支持JSP热部署的,现在的JSP Web Server通过在运行期间通过Runtime.exec或ProcessBuilder来调用javac来编译代码,这种方式需要我们产生另一个进程去 做编译工作,不够优雅而且容易使代码依赖与特定的操作系统;Compiler API通过一套易用的标准的API提供了更加丰富的方式去做动态编译,而且是跨平台的。
5)轻量级Http Server API
答:
JDK6 提供了一个简单的Http Server API,据此我们可以构建自己的嵌入式Http Server,它支持Http和Https协议,提供了HTTP1.1的部分实现,没有被实现的那部分可以通过扩展已有的Http Server API来实现,程序员必须自己实现HttpHandler接口,HttpServer会调用HttpHandler实现类的回调方法来处理客户端请求,在 这里,我们把一个Http请求和它的响应称为一个交换,包装成HttpExchange类,HttpServer负责将HttpExchange传给 HttpHandler实现类的回调方法.
6)插入式注解处理API(Pluggable Annotation Processing API)
答:
插入式注解处理API(JSR 269)提供一套标准API来处理Annotations(JSR 175)
实 际上JSR 269不仅仅用来处理Annotation,我觉得更强大的功能是它建立了Java 语言本身的一个模型,它把method, package, constructor, type, variable, enum, annotation等Java语言元素映射为Types和Elements(两者有什么区别?), 从而将Java语言的语义映射成为对象, 我们可以在javax.lang.model包下面可以看到这些类. 所以我们可以利用JSR 269提供的API来构建一个功能丰富的元编程(metaprogramming)环境.
JSR 269用Annotation Processor在编译期间而不是运行期间处理Annotation, Annotation Processor相当于编译器的一个插件,所以称为插入式注解处理.如果Annotation Processor处理Annotation时(执行process方法)产生了新的Java代码,编译器会再调用一次Annotation Processor,如果第二次处理还有新代码产生,就会接着调用Annotation Processor,直到没有新代码产生为止.每执行一次process()方法被称为一个"round",这样整个Annotation processing过程可以看作是一个round的序列.
JSR 269主要被设计成为针对Tools或者容器的API. 举个例子,我们想建立一套基于Annotation的单元测试框架(如TestNG),在测试类里面用Annotation来标识测试期间需要执行的测试方法。
7)用Console开发控制台程序
JDK6 中提供了java.io.Console 类专用来访问基于字符的控制台设备. 你的程序如果要与Windows下的cmd或者Linux下的Terminal交互,就可以用Console类代劳. 但我们不总是能得到可用的Console, 一个JVM是否有可用的Console依赖于底层平台和JVM如何被调用. 如果JVM是在交互式命令行(比如Windows的cmd)中启动的,并且输入输出没有重定向到另外的地方,那么就可以得到一个可用的Console实例.
8)对脚本语言的支持
如: ruby, groovy, javascript.
9)Common annotations
Common annotations 原本是Java EE 5.0(JSR 244)规范的一部分,现在SUN把它的一部分放到了Java SE 6.0中.随着Annotation元数据功能(JSR 175)加入到Java SE 5.0里面,很多Java 技术(比如EJB,Web Services)都会用Annotation部分代替XML文件来配置运行参数(或者说是支持声明式编程,如EJB的声明式事务), 如果这些技术为通用目的都单独定义了自己的Annotations,显然有点重复建设, 所以,为其他相关的Java技术定义一套公共的Annotation是有价值的,可以避免重复建设的同时,也保证Java SE和Java EE 各种技术的一致性。
10)Java DB(Derby)
从 JDK6 开始,JDK 目录中新增了一个名为 db 的目录。这便是 Java 6 的新成员:Java DB。这是一个纯 Java 实现、开源的数据库管理系统(DBMS),源于 Apache 软件基金会(ASF)名下的项目 Derby。它只有 2MB 大小,对比动辄上 G 的数据库来说可谓袖珍。但这并不妨碍 Derby 功能齐备,支持几乎大部分的数据库应用所需要的特性。JDK6.0里面带的这个Derby的版本是10.2.1.7,支持存储过程和触发器;有两种运行模式,一种是作为嵌入式数据库,另一种是作为网络数据库。前者的数据库服务器和客户端都在同一个JVM里面运行,后者允许数据库服务器端和客户端不在同一个JVM里面,而且允许这两者在不同的物理机器上。值得注意的是JDK6里面的这个Derby支持JDK6的新特性 JDBC 4.0 规范(JSR 221)。
11)JDBC 4.0
在 Java SE 6 所提供的诸多新特性和改进中,值得一提的是为 Java 程序提供数据库访问机制的 JDBC 版本升级到了 4.0, 这个以 JSR-221 为代号的版本,提供了更加便利的代码编写机制及柔性,并且支持更多的数据类型。JDBC4.0 主要有以下改进和新特性。
- 自动加载
java.sql.Driver,而不需要再调用class.forName; - 添加了
java.sql.RowId数据类型用来可以访问sql rowid; - 添加了
National Character Set的支持; - 增强了
BLOB和CLOB的支持功能; -
SQL/XML和XML支持; -
Wrapper Pattern; -
SQLException增强; -
Connection和Statement接口增强; -
New Scalar Funtions; -
JDBC API changes。
(三)JAVA 7 相关知识点
之前已经写过一篇详细介绍 Java 7 特性的文章了,这里就直接黏了:Java 7新特性
1)Diamond Operator
类型判断是一个人特殊的烦恼,入下面的代码:
Map> anagrams = new HashMap>();
通过类型推断后变成:
Map> anagrams = new HashMap<>();
注:这个<>被叫做diamond(钻石)运算符,Java 7后这个运算符从引用的声明中推断类型。
2)在switch语句中使用字符串
switch语句可以使用原始类型或枚举类型。Java引入了另一种类型,我们可以在switch语句中使用:字符串类型。
说我们有一个根据其地位来处理贸易的要求。直到现在,我们使用if-其他语句来完成这个任务。
private voidprocessTrade(Trade t){
String status = t.getStatus();
if(status.equalsIgnoreCase(NEW)) {
newTrade(t);
} else if(status.equalsIgnoreCase(EXECUTE)) {
executeTrade(t);
} else if(status.equalsIgnoreCase(PENDING)) {
pendingTrade(t);
}
}
这种处理字符串的方法是粗糙的。在Java中,我们可以使用增强的switch语句来改进程序,该语句以String类型作为参数。
public voidprocessTrade(Trade t) {
String status = t.getStatus();
switch(status) {
caseNEW:
newTrade(t);
break;
caseEXECUTE:
executeTrade(t);
break;
casePENDING:
pendingTrade(t);
break;
default:
break;
}
}
在上面的程序中,状态字段总是通过使用 String.equals() 与案例标签来进行比较。
3)自动资源管理
Java中有一些资源需要手动关闭,例如Connections,Files,Input/OutStreams等。通常我们使用 try-finally 来关闭资源:
public voidoldTry() {
try{
fos= newFileOutputStream("movies.txt");
dos= newDataOutputStream(fos);
dos.writeUTF("Java 7 Block Buster");
} catch(IOException e) {
e.printStackTrace();
} finally{
try{
fos.close();
dos.close();
} catch(IOException e) {
// log the exception
}
}
}
然而,在Java 7中引入了另一个很酷的特性,可以自动管理资源。它的操作也很简单,我们所要做的就是在 try 块中申明资源如下:
try(resources_to_be_cleant){
// your code
}
以上方法与旧的 try-finally 能最终写成下面的代码:
public voidnewTry() {
try(FileOutputStream fos = newFileOutputStream("movies.txt");
DataOutputStream dos = newDataOutputStream(fos)) {
dos.writeUTF("Java 7 Block Buster");
} catch(IOException e) {
// log the exception
}
}
上面的代码也代表了这个特性的另一个方面:处理多个资源。FileOutputStream 和 DataOutputStream 在try语句中一个接一个地含在语句中,每一个都用分号(;)分隔符分隔开。我们不必手动取消或关闭流,因为当空间存在try块时,它们将自动关闭。
在后台,应该自动关闭的资源必须试验 java.lang.AutoCloseable 接口。
任何实现 AutoCloseable 接口的资源都可以作为自动资源管理的候选。AutoCloseable 是 java.io.Closeable 接口的父类,JVM会在程序退出try块后调用一个方法 close()。
4)带下划线的数字文本
数字文字绝对是对眼睛的一种考验。我相信,如果你给了一个数字,比如说,十个零,你就会像我一样数零。如果不计算从右到左的位置,识别一个文字的话,就很容易出错,而且很麻烦。Not anymore。Java在识别位置时引入了下划线。例如,您可以声明1000,如下所示:
int thousand = 1_000;
或1000000(一百万)如下:
int million = 1_000_000
请注意,这个版本中也引入了二进制文字-例如“0b1”-因此开发人员不必再将它们转换为十六进制。
5)改进的异常处理
在异常处理区域有几处改进。Java引入了多个catch功能,以使用单个抓到块捕获多个异常类型。
假设您有一个方法,它抛出三个异常。在当前状态下,您将分别处理它们,如下所示:
public voidoldMultiCatch() {
try{
methodThatThrowsThreeExceptions();
} catch(ExceptionOne e) {
// log and deal with ExceptionOne
} catch(ExceptionTwo e) {
// log and deal with ExceptionTwo
} catch(ExceptionThree e) {
// log and deal with ExceptionThree
}
}
在一个catch块中逐个捕获一个连续的异常,看起来很混乱。我还看到了捕获十几个异常的代码。这是非常低效和容易出错的。Java为解决这只丑小鸭带来了新的语言变化。请参阅下面的方法oldMultiCatch方法的改进版本:
public voidnewMultiCatch() {
try{
methodThatThrowsThreeExceptions();
} catch(ExceptionOne | ExceptionTwo | ExceptionThree e) {
// log and deal with all Exceptions
}
}
多个异常通过使用 “|” 操作符在一个catch块中捕获。这样,您不必编写数十个异常捕获。但是,如果您有许多属于不同类型的异常,那么您也可以使用“多个catch块”块。下面的代码片段说明了这一点:
public voidnewMultiMultiCatch() {
try{
methodThatThrowsThreeExceptions();
} catch(ExceptionOne e) {
// log and deal with ExceptionOne
} catch(ExceptionTwo | ExceptionThree e) {
// log and deal with ExceptionTwo and ExceptionThree
}
}
在上面的例子中,在和ExceptionThree属于不同的层次结构,因此您希望以不同的方式处理它们,但使用一个抓到块。
6)New file system API(NIO 2.0)
那些使用Java的人可能还记得框架引起的头痛。在操作系统或多文件系统之间无缝地工作从来都不是一件容易的事情.。有些方法,例如删除或重命名,在大多数情况下都是出乎意料的。使用符号链接是另一个问题。实质上API需要大修。
为了解决上述问题,Java引入了一个新的API,并在许多情况下引入了新的api。
在NIO2.0提出了许多增强功能。在处理多个文件系统时,它还引入了新的类来简化开发人员的生活。
Working With Path(使用路径):
新的 java.nio.file 由包和接口组成例如:Path,Paths,FileSystem,FileSystems等等。
路径只是对文件路径的简单引用。它与java.io.File等价(并具有更多的特性)。下面的代码段显示了如何获取对“临时”文件夹的路径引用:
public voidpathInfo() {
Path path= Paths.get("c:\Temp\temp");
System.out.println("Number of Nodes:"+ path.getNameCount());
System.out.println("File Name:"+ path.getFileName());
System.out.println("File Root:"+ path.getRoot());
System.out.println("File Parent:"+ path.getParent());
}
最终控制台的输出将是:
Number of Nodes:2
File Name:temp.txt
File Root:c:
File Parent:c:Temp
删除文件或目录就像在文件中调用delete方法(注意复数)一样简单。在类公开两个删除方法,一个抛出NoSuchFileException,另一个不抛。
下面的delete方法调用抛出NoSuchFileException,因此您必须处理它:
Files.delete(path);
Where as Files.deleteIfExists(path) does not throw exception (as expected) if the file/directory does not exist.
使用 Files.deteleIfExists(path) 则不会抛出异常。
您可以使用其他实用程序方法,例如Files.copy(.)和Files.move(.)来有效地对文件系统执行操作。类似地,使用 createSymbolicLink(..) 方法使用代码创建符号链接。
文件更改通知:
JDK 7中最好的改善算是File change notifications(文件更改通知)了。这是一个长期等待的特性,它最终被刻在NIO 2.0中。WatchService API 允许您在对主题(目录或文件)进行更改时接收通知事件。
具体的创建步骤就不给了,总之它的功能就跟它的名字一般,当文件发生更改的时候,能及时作出反馈。
7)Fork and Join(Fork/Join框架)
在一个 Java 程序中有效地使用并行内核一直是一个挑战。很少有国内开发的框架将工作分配到多个核心,然后加入它们来返回结果集。Java已经将这个特性作为Fork/Join框架结合了起来。
基本上,在把手头的任务变成了小任务,直到小任务简单到可以不进一步分手的情况下解决。这就像一个分而治之的算法.。在这个框架中需要注意的一个重要概念是,理想情况下,没有工作线程是空闲的。他们实现了一个 work-stealing 算法,在空闲的工人“偷”工作从那些工人谁是忙。
支持Fork-Join机制的核心类是 ForkJoinPool和ForkJoinTask。
什么是Fork/Join框架:
Java7提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
Fork/Join的运行流程图如下:
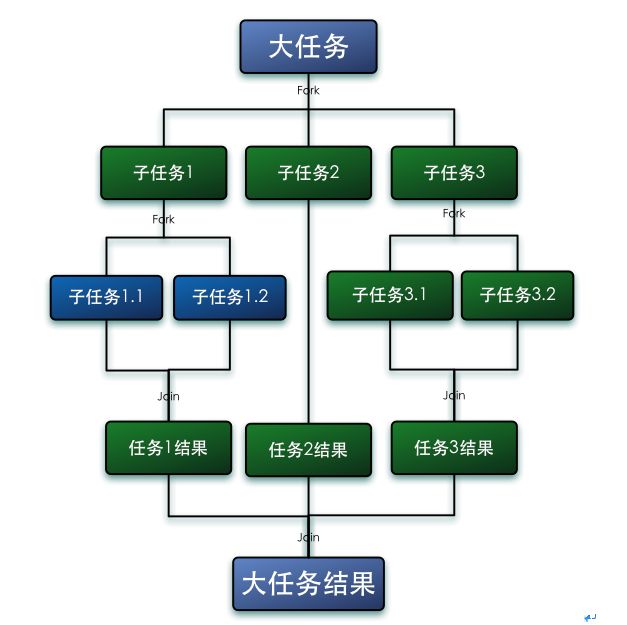
工作窃取算法:
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:

工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
Fork/Join框架使用示例:
让我们通过一个简单的需求来使用下 Fork/Join 框架,需求是:计算1 + 2 + 3 + 4的结果。
使用 Fork/Join 框架首先要考虑到的是如何分割任务,如果我们希望每个子任务最多执行两个数的相加,那么我们设置分割的阈值是2,由于是4个数字相加,所以 Fork/Join 框架会把这个任务 fork 成两个子任务,子任务一负责计算1 + 2,子任务二负责计算3 + 4,然后再 join 两个子任务的结果。
因为是有结果的任务,所以必须继承 RecursiveTask ,实现代码如下:
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
/**
* CountTask.
*
* @author blinkfox on 2018-01-03.
*/
public class CountTask extends RecursiveTask {
/** 阈值. */
public static final int THRESHOLD = 2;
/** 计算的开始值. */
private int start;
/** 计算的结束值. */
private int end;
/**
* 构造方法.
*
* @param start 计算的开始值
* @param end 计算的结束值
*/
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
/**
* 执行计算的方法.
*
* @return int型结果
*/
@Override
protected Integer compute() {
int sum = 0;
// 如果任务足够小就计算任务.
if ((end - start) <= THRESHOLD) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任务大于阈值,就分裂成两个子任务来计算.
int middle = (start + end) / 2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
// 等待子任务执行完,并得到结果,再合并执行结果.
leftTask.fork();
rightTask.fork();
sum = leftTask.join() + rightTask.join();
}
return sum;
}
/**
* main方法.
*
* @param args 数组参数
*/
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinPool fkPool = new ForkJoinPool();
CountTask task = new CountTask(1, 4);
Future result = fkPool.submit(task);
System.out.println("result:" + result.get());
}
}
参考文章:Java7新特性及使用
这里是Java 7的新特性一览表:http://www.oschina.net/news/20119/new-features-of-java-7
(四)Java 8 相关知识点
关于 Java 8 中新知识点,面试官会让你说说 Java 8 你了解多少,下面分享一下我收集的 Java 8 新增的知识点的内容,前排申明引用自:Java8新特性及使用
1)接口默认方法和静态方法
Java 8用默认方法与静态方法这两个新概念来扩展接口的声明。与传统的接口又有些不一样,它允许在已有的接口中添加新方法,而同时又保持了与旧版本代码的兼容性。
1.接口默认方法
默认方法与抽象方法不同之处在于抽象方法必须要求实现,但是默认方法则没有这个要求。相反,每个接口都必须提供一个所谓的默认实现,这样所有的接口实现者将会默认继承它(如果有必要的话,可以覆盖这个默认实现)。让我们看看下面的例子:
private interface Defaulable {
// Interfaces now allow default methods, the implementer may or
// may not implement (override) them.
default String notRequired() {
return "Default implementation";
}
}
private static class DefaultableImpl implements Defaulable {
}
private static class OverridableImpl implements Defaulable {
@Override
public String notRequired() {
return "Overridden implementation";
}
}
Defaulable 接口用关键字 default 声明了一个默认方法 notRequired(),Defaulable 接口的实现者之一 DefaultableImpl 实现了这个接口,并且让默认方法保持原样。Defaulable 接口的另一个实现者 OverridableImpl 用自己的方法覆盖了默认方法。
1.1 多重继承的冲突说明:
由于同一个方法可以从不同的接口引入,自然而然的会有冲突的现象,规则如下:
- 一个声明在类里面的方法优先于任何默认方法
- 优先选取最具体的实现
public interface A {
default void hello() {
System.out.println("Hello A");
}
}
public interface B extends A {
default void hello() {
System.out.println("Hello B");
}
}
public class C implements A, B {
public static void main(String[] args) {
new C().hello(); // 输出 Hello B
}
}
1.2 优缺点:
- 优点: 可以在不破坏代码的前提下扩展原有库的功能。它通过一个很优雅的方式使得接口变得更智能,同时还避免了代码冗余,并且扩展类库。
- 缺点: 使得接口作为协议,类作为具体实现的界限开始变得有点模糊。
1.3 接口默认方法不能重载Object类的任何方法:
接口不能提供对Object类的任何方法的默认实现。简单地讲,每一个java类都是Object的子类,也都继承了它类中的 equals()/hashCode()/toString() 方法,那么在类的接口上包含这些默认方法是没有意义的,它们也从来不会被编译。
在 JVM 中,默认方法的实现是非常高效的,并且通过字节码指令为方法调用提供了支持。默认方法允许继续使用现有的Java接口,而同时能够保障正常的编译过程。这方面好的例子是大量的方法被添加到 java.util.Collection 接口中去:stream(),parallelStream(),forEach(),removeIf() 等。尽管默认方法非常强大,但是在使用默认方法时我们需要小心注意一个地方:在声明一个默认方法前,请仔细思考是不是真的有必要使用默认方法。
2.接口静态方法
Java 8 带来的另一个有趣的特性是接口可以声明(并且可以提供实现)静态方法。在接口中定义静态方法,使用 static 关键字,例如:
public interface StaticInterface {
static void method() {
System.out.println("这是Java8接口中的静态方法!");
}
}
下面的一小段代码是上面静态方法的使用。
public class Main {
public static void main(String[] args) {
StaticInterface.method(); // 输出 这是Java8接口中的静态方法!
}
}
Java 支持一个实现类可以实现多个接口,如果多个接口中存在同样的 static 方法会怎么样呢?如果有两个接口中的静态方法一模一样,并且一个实现类同时实现了这两个接口,此时并不会产生错误,因为Java8中只能通过接口类调用接口中的静态方法,所以对编译器来说是可以区分的。
2)Lambda 表达式
Lambda 表达式(也称为闭包)是整个Java 8发行版中最受期待的在Java语言层面上的改变,Lambda允许把函数作为一个方法的参数(即:行为参数化,函数作为参数传递进方法中)。
一个 Lambda 可以由用逗号分隔的参数列表、–> 符号与函数体三部分表示。
首先看看在老版本的Java中是如何排列字符串的:
List names = Arrays.asList("peter", "anna", "mike", "xenia");
Collections.sort(names, new Comparator() {
@Override
public int compare(String a, String b) {
return b.compareTo(a);
}
});
只需要给静态方法 Collections.sort 传入一个List对象以及一个比较器来按指定顺序排列。通常做法都是创建一个匿名的比较器对象然后将其传递给sort方法。 在Java 8 中你就没必要使用这种传统的匿名对象的方式了,Java 8提供了更简洁的语法,lambda表达式:
Collections.sort(names, (String a, String b) -> {
return b.compareTo(a);
});
看到了吧,代码变得更短且更具有可读性,但是实际上还可以写得更短:
Collections.sort(names, (String a, String b) -> b.compareTo(a));
对于函数体只有一行代码的,你可以去掉大括号{}以及return关键字,但是你还可以写得更短点:
Collections.sort(names, (a, b) -> b.compareTo(a));
Java编译器可以自动推导出参数类型,所以你可以不用再写一次类型。
更多 Lambda 表达式的示例在这里:Java8 lambda表达式10个示例
3)函数式接口
Lambda 表达式是如何在 Java 的类型系统中表示的呢?每一个Lambda表达式都对应一个类型,通常是接口类型。而函数式接口是指仅仅只包含一个抽象方法的接口,每一个该类型的Lambda表达式都会被匹配到这个抽象方法。因为默认方法不算抽象方法,所以你也可以给你的函数式接口添加默认方法。
我们可以将Lambda表达式当作任意只包含一个抽象方法的接口类型,确保你的接口一定达到这个要求,你只需要给你的接口添加 @FunctionalInterface 注解,编译器如果发现你标注了这个注解的接口有多于一个抽象方法的时候会报错的。
示例如下:
@FunctionalInterface
interface Converter {
T convert(F from);
}
Converter converter = (from) -> Integer.valueOf(from);
Integer converted = converter.convert("123");
System.out.println(converted); // 123
注意: 如果
@FunctionalInterface如果没有指定,上面的代码也是对的。
更多参考: Java 8——Lambda表达式、Java8新特性及使用
4)方法引用
1.概述:
在学习了Lambda表达式之后,我们通常使用Lambda表达式来创建匿名方法。然而,有时候我们仅仅是调用了一个已存在的方法。如下:
Arrays.sort(strArray, (s1, s2) -> s1.compareToIgnoreCase(s2));
在Java8中,我们可以直接通过方法引用来简写Lambda表达式中已经存在的方法。
Arrays.sort(strArray, String::compareToIgnoreCase);
这种特性就叫做方法引用(Method Reference)。
方法引用是用来直接访问类或者实例的已经存在的方法或者构造方法。方法引用提供了一种引用而不执行方法的方式,它需要由兼容的函数式接口构成的目标类型上下文。计算时,方法引用会创建函数式接口的一个实例。当Lambda表达式中只是执行一个方法调用时,不用Lambda表达式,直接通过方法引用的形式可读性更高一些。方法引用是一种更简洁易懂的Lambda表达式。
注意: 方法引用是一个Lambda表达式,其中方法引用的操作符是双冒号::。
2.分类:
方法引用的标准形式是:类名::方法名。(注意:只需要写方法名,不需要写括号)
有以下四种形式的方法引用:
- 引用静态方法: ContainingClass::staticMethodName
- 引用某个对象的实例方法: containingObject::instanceMethodName
- 引用某个类型的任意对象的实例方法:ContainingType::methodName
- 引用构造方法: ClassName::new
3.示例:
使用示例如下:
public class Person {
String name;
LocalDate birthday;
public Person(String name, LocalDate birthday) {
this.name = name;
this.birthday = birthday;
}
public LocalDate getBirthday() {
return birthday;
}
public static int compareByAge(Person a, Person b) {
return a.birthday.compareTo(b.birthday);
}
@Override
public String toString() {
return this.name;
}
}
public class MethodReferenceTest {
@Test
public static void main() {
Person[] pArr = new Person[] {
new Person("003", LocalDate.of(2016,9,1)),
new Person("001", LocalDate.of(2016,2,1)),
new Person("002", LocalDate.of(2016,3,1)),
new Person("004", LocalDate.of(2016,12,1))
};
// 使用匿名类
Arrays.sort(pArr, new Comparator() {
@Override
public int compare(Person a, Person b) {
return a.getBirthday().compareTo(b.getBirthday());
}
});
//使用lambda表达式
Arrays.sort(pArr, (Person a, Person b) -> {
return a.getBirthday().compareTo(b.getBirthday());
});
//使用方法引用,引用的是类的静态方法
Arrays.sort(pArr, Person::compareByAge);
}
}
5)Steam
Java8添加的
Stream API(java.util.stream)把真正的函数式编程风格引入到Java中。这是目前为止对Java类库最好的补充,因为Stream API可以极大提供Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。使用 Steam 写出来的代码真的能让人兴奋,这里链出之前的一篇文章:Java 8——函数式数据处理(流)
流可以是无限的、有状态的,可以是顺序的,也可以是并行的。在使用流的时候,你首先需要从一些来源中获取一个流,执行一个或者多个中间操作,然后执行一个最终操作。中间操作包括filter、map、flatMap、peel、distinct、sorted、limit 和 substream。终止操作包括 forEach、toArray、reduce、collect、min、max、count、anyMatch、allMatch、noneMatch、findFirst 和 findAny。 java.util.stream.Collectors 是一个非常有用的实用类。该类实现了很多归约操作,例如将流转换成集合和聚合元素。
1.一些重要方法说明:
-
stream: 返回数据流,集合作为其源 -
parallelStream: 返回并行数据流, 集合作为其源 -
filter: 方法用于过滤出满足条件的元素 -
map: 方法用于映射每个元素对应的结果 -
forEach: 方法遍历该流中的每个元素 -
limit: 方法用于减少流的大小 -
sorted: 方法用来对流中的元素进行排序 -
anyMatch: 是否存在任意一个元素满足条件(返回布尔值) -
allMatch: 是否所有元素都满足条件(返回布尔值) -
noneMatch: 是否所有元素都不满足条件(返回布尔值) -
collect: 方法是终端操作,这是通常出现在管道传输操作结束标记流的结束
2.一些使用示例:
2.1 Filter 过滤:
stringCollection
.stream()
.filter((s) -> s.startsWith("a"))
.forEach(System.out::println);
2.2 Sort 排序:
stringCollection
.stream()
.sorted()
.filter((s) -> s.startsWith("a"))
.forEach(System.out::println);
2.3 Map 映射:
stringCollection
.stream()
.map(String::toUpperCase)
.sorted((a, b) -> b.compareTo(a))
.forEach(System.out::println);
2.4 Match 匹配:
boolean anyStartsWithA = stringCollection
.stream()
.anyMatch((s) -> s.startsWith("a"));
System.out.println(anyStartsWithA); // true
boolean allStartsWithA = stringCollection
.stream()
.allMatch((s) -> s.startsWith("a"));
System.out.println(allStartsWithA); // false
boolean noneStartsWithZ = stringCollection
.stream()
.noneMatch((s) -> s.startsWith("z"));
System.out.println(noneStartsWithZ); // true
2.5 Count 计数:
long startsWithB = stringCollection
.stream()
.filter((s) -> s.startsWith("b"))
.count();
System.out.println(startsWithB); // 3
2.6 Reduce 规约:
Optional reduced = stringCollection
.stream()
.sorted()
.reduce((s1, s2) -> s1 + "#" + s2);
reduced.ifPresent(System.out::println);
6)Optional
到目前为止,臭名昭著的空指针异常是导致Java应用程序失败的最常见原因。以前,为了解决空指针异常,Google公司著名的Guava项目引入了Optional类,Guava通过使用检查空值的方式来防止代码污染,它鼓励程序员写更干净的代码。受到Google Guava的启发,Optional类已经成为Java 8类库的一部分。
Optional实际上是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
我们下面用两个小例子来演示如何使用Optional类:一个允许为空值,一个不允许为空值。
Optional fullName = Optional.ofNullable(null);
System.out.println("Full Name is set? " + fullName.isPresent());
System.out.println("Full Name: " + fullName.orElseGet(() -> "[none]"));
System.out.println(fullName.map(s -> "Hey " + s + "!").orElse("Hey Stranger!"));
如果Optional类的实例为非空值的话,isPresent()返回true,否从返回false。为了防止Optional为空值,orElseGet()方法通过回调函数来产生一个默认值。map()函数对当前Optional的值进行转化,然后返回一个新的Optional实例。orElse()方法和orElseGet()方法类似,但是orElse接受一个默认值而不是一个回调函数。下面是这个程序的输出:
Full Name is set? false
Full Name: [none]
Hey Stranger!
让我们来看看另一个例子:
Optional firstName = Optional.of("Tom");
System.out.println("First Name is set? " + firstName.isPresent());
System.out.println("First Name: " + firstName.orElseGet(() -> "[none]"));
System.out.println(firstName.map(s -> "Hey " + s + "!").orElse("Hey Stranger!"));
System.out.println();
下面是程序的输出:
First Name is set? true
First Name: Tom
Hey Tom!
7)Date/Time API
Java 8 在包java.time下包含了一组全新的时间日期API。新的日期API和开源的Joda-Time库差不多,但又不完全一样,下面的例子展示了这组新API里最重要的一些部分:
1.Clock 时钟:
Clock类提供了访问当前日期和时间的方法,Clock是时区敏感的,可以用来取代System.currentTimeMillis()来获取当前的微秒数。某一个特定的时间点也可以使用Instant类来表示,Instant类也可以用来创建老的java.util.Date对象。代码如下:
Clock clock = Clock.systemDefaultZone();
long millis = clock.millis();
Instant instant = clock.instant();
Date legacyDate = Date.from(instant); // legacy java.util.Date
2.Timezones 时区:
在新API中时区使用ZoneId来表示。时区可以很方便的使用静态方法of来获取到。时区定义了到UTS时间的时间差,在Instant时间点对象到本地日期对象之间转换的时候是极其重要的。代码如下:
System.out.println(ZoneId.getAvailableZoneIds());
// prints all available timezone ids
ZoneId zone1 = ZoneId.of("Europe/Berlin");
ZoneId zone2 = ZoneId.of("Brazil/East");
System.out.println(zone1.getRules());
System.out.println(zone2.getRules());
// ZoneRules[currentStandardOffset=+01:00]
// ZoneRules[currentStandardOffset=-03:00]
3.LocalTime 本地时间:
LocalTime定义了一个没有时区信息的时间,例如 晚上10点,或者 17:30:15。下面的例子使用前面代码创建的时区创建了两个本地时间。之后比较时间并以小时和分钟为单位计算两个时间的时间差。代码如下:
LocalTime now1 = LocalTime.now(zone1);
LocalTime now2 = LocalTime.now(zone2);
System.out.println(now1.isBefore(now2)); // false
long hoursBetween = ChronoUnit.HOURS.between(now1, now2);
long minutesBetween = ChronoUnit.MINUTES.between(now1, now2);
System.out.println(hoursBetween); // -3
System.out.println(minutesBetween); // -239
LocalTime提供了多种工厂方法来简化对象的创建,包括解析时间字符串。代码如下:
LocalTime late = LocalTime.of(23, 59, 59);
System.out.println(late); // 23:59:59
DateTimeFormatter germanFormatter = DateTimeFormatter
.ofLocalizedTime(FormatStyle.SHORT)
.withLocale(Locale.GERMAN);
LocalTime leetTime = LocalTime.parse("13:37", germanFormatter);
System.out.println(leetTime); // 13:37
4.LocalDate 本地日期:
LocalDate表示了一个确切的日期,比如2014-03-11。该对象值是不可变的,用起来和LocalTime基本一致。下面的例子展示了如何给Date对象加减天/月/年。另外要注意的是这些对象是不可变的,操作返回的总是一个新实例。代码如下:
LocalDate today = LocalDate.now();
LocalDate tomorrow = today.plus(1, ChronoUnit.DAYS);
LocalDate yesterday = tomorrow.minusDays(2);
LocalDate independenceDay = LocalDate.of(2014, Month.JULY, 4);
DayOfWeek dayOfWeek = independenceDay.getDayOfWeek();
System.out.println(dayOfWeek); // FRIDAY
从字符串解析一个LocalDate类型和解析LocalTime一样简单。代码如下:
DateTimeFormatter germanFormatter = DateTimeFormatter
.ofLocalizedDate(FormatStyle.MEDIUM)
.withLocale(Locale.GERMAN);
LocalDate xmas = LocalDate.parse("24.12.2014", germanFormatter);
System.out.println(xmas); // 2014-12-24
5.LocalDateTime 本地日期时间:
LocalDateTime同时表示了时间和日期,相当于前两节内容合并到一个对象上了。LocalDateTime和LocalTime还有LocalDate一样,都是不可变的。LocalDateTime提供了一些能访问具体字段的方法。代码如下:
LocalDateTime sylvester = LocalDateTime.of(2014, Month.DECEMBER, 31, 23, 59, 59);
DayOfWeek dayOfWeek = sylvester.getDayOfWeek();
System.out.println(dayOfWeek); // WEDNESDAY
Month month = sylvester.getMonth();
System.out.println(month); // DECEMBER
long minuteOfDay = sylvester.getLong(ChronoField.MINUTE_OF_DAY);
System.out.println(minuteOfDay); // 1439
只要附加上时区信息,就可以将其转换为一个时间点Instant对象,Instant时间点对象可以很容易的转换为老式的java.util.Date。代码如下:
Instant instant = sylvester
.atZone(ZoneId.systemDefault())
.toInstant();
Date legacyDate = Date.from(instant);
System.out.println(legacyDate); // Wed Dec 31 23:59:59 CET 2014
格式化LocalDateTime和格式化时间和日期一样的,除了使用预定义好的格式外,我们也可以自己定义格式。代码如下:
DateTimeFormatter formatter =
DateTimeFormatter
.ofPattern("MMM dd, yyyy - HH:mm");
LocalDateTime parsed = LocalDateTime.parse("Nov 03, 2014 - 07:13", formatter);
String string = formatter.format(parsed);
System.out.println(string); // Nov 03, 2014 - 07:13
和java.text.NumberFormat不一样的是新版的DateTimeFormatter是不可变的,所以它是线程安全的。
关于Java8中日期API更多的使用示例可以参考Java 8中关于日期和时间API的20个使用示例。
8)重复注解
自从Java 5引入了注解机制,这一特性就变得非常流行并且广为使用。然而,使用注解的一个限制是相同的注解在同一位置只能声明一次,不能声明多次。Java 8打破了这条规则,引入了重复注解机制,这样相同的注解可以在同一地方声明多次。
重复注解机制本身必须用@Repeatable注解。事实上,这并不是语言层面上的改变,更多的是编译器的技巧,底层的原理保持不变。让我们看一个快速入门的例子:
import java.lang.annotation.ElementType;
import java.lang.annotation.Repeatable;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
public class RepeatingAnnotations {
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Filters {
Filter[] value();
}
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Repeatable(Filters.class)
public @interface Filter {
String value();
};
@Filter("filter1")
@Filter("filter2")
public interface Filterable {
}
public static void main(String[] args) {
for(Filter filter: Filterable.class.getAnnotationsByType(Filter.class)) {
System.out.println(filter.value());
}
}
}
正如我们看到的,这里有个使用@Repeatable(Filters.class)注解的注解类Filter,Filters仅仅是Filter注解的数组,但Java编译器并不想让程序员意识到Filters的存在。这样,接口Filterable就拥有了两次Filter(并没有提到Filter)注解。
同时,反射相关的API提供了新的函数getAnnotationsByType()来返回重复注解的类型(请注意Filterable.class.getAnnotation(Filters.class)经编译器处理后将会返回Filters的实例)。
9)扩展注解的支持
Java 8扩展了注解的上下文。现在几乎可以为任何东西添加注解:局部变量、泛型类、父类与接口的实现,就连方法的异常也能添加注解。下面演示几个例子:
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import java.util.ArrayList;
import java.util.Collection;
public class Annotations {
@Retention(RetentionPolicy.RUNTIME)
@Target({ ElementType.TYPE_USE, ElementType.TYPE_PARAMETER })
public @interface NonEmpty {
}
public static class Holder<@NonEmpty T> extends @NonEmpty Object {
public void method() throws @NonEmpty Exception {
}
}
@SuppressWarnings("unused")
public static void main(String[] args) {
final Holder holder = new @NonEmpty Holder();
@NonEmpty Collection<@NonEmpty String> strings = new ArrayList<>();
}
}
10)Base 64
在Java 8中,Base64编码已经成为Java类库的标准。它的使用十分简单,下面让我们看一个例子:
import java.nio.charset.StandardCharsets;
import java.util.Base64;
public class Base64s {
public static void main(String[] args) {
final String text = "Base64 finally in Java 8!";
final String encoded = Base64.getEncoder().encodeToString(text.getBytes(StandardCharsets.UTF_8));
System.out.println(encoded);
final String decoded = new String(Base64.getDecoder().decode(encoded), StandardCharsets.UTF_8);
System.out.println(decoded);
}
}
程序在控制台上输出了编码后的字符与解码后的字符:
QmFzZTY0IGZpbmFsbHkgaW4gSmF2YSA4IQ==
Base64 finally in Java 8!
Base64类同时还提供了对URL、MIME友好的编码器与解码器(Base64.getUrlEncoder() / Base64.getUrlDecoder(), Base64.getMimeEncoder() / Base64.getMimeDecoder())。
11)JavaFX
JavaFX是一个强大的图形和多媒体处理工具包集合,它允许开发者来设计、创建、测试、调试和部署富客户端程序,并且和Java一样跨平台。从Java8开始,JavaFx已经内置到了JDK中。关于JavaFx更详细的文档可参考JavaFX中文文档。
12)HashMap的底层实现有变化
Java8中,HashMap内部实现又引入了红黑树(数组+链表+红黑树),使得HashMap的总体性能相较于Java7有比较明显的提升。
13)JVM内存管理方面,由元空间代替了永久代。
区别:
- 元空间并不在虚拟机中,而是使用本地内存
- 默认情况下,元空间的大小仅受本地内存限制
- 也可以通过-XX:MetaspaceSize指定元空间大小
(五)Java 9 相关知识点
引用自文章:Java 9 中的 9 个新特性、Java 9 新特性概述——IBM、【译】使用示例带你提前了解 Java 9 中的新特性
1)Java 9 PEPK(JShell)
Oracle 公司(Java Library 开发者)新引进一个代表 Java Shell 的称之为 “jshell” 或者 REPL(Read Evaluate Print Loop)的新工具。该工具可以被用来执行和测试任何 Java 中的结构,如 class,interface,enum,object,statements 等。使用非常简单。
JDK 9 EA(Early Access)下载地址:https://jdk9.java.net/download/
G:\>jshell
| Welcome to JShell -- Version 9-ea
| For an introduction type: /help intro
jshell> int a = 10
a ==> 10
jshell> System.out.println("a value = " + a )
a value = 10
2)集合工厂方法
通常,您希望在代码中创建一个集合(例如,List 或 Set ),并直接用一些元素填充它。 实例化集合,几个 “add” 调用,使得代码重复。 Java 9,添加了几种集合工厂方法:
Set ints = Set.of(1, 2, 3);
List strings = List.of("first", "second");
除了更短和更好阅读之外,这些方法也可以避免您选择特定的集合实现。 事实上,从工厂方法返回已放入数个元素的集合实现是高度优化的。这是可能的,因为它们是不可变的:在创建后,继续添加元素到这些集合会导致 “UnsupportedOperationException” 。
3)接口中的私有方法
在 Java 8 中,我们可以在接口中使用默认或者静态方法提供一些实现方式,但是不能创建私有方法。
为了避免冗余代码和提高重用性,Oracle 公司准备在 Java SE 9 接口中引入私有方法。也就是说从 Java SE 9 开始,我们也能够在接口类中使用 ‘private’ 关键字写私有化方法和私有化静态方法。
接口中的私有方法与 class 类中的私有方法在写法上并无差异,如:
public interface Card{
private Long createCardID(){
// Method implementation goes here.
}
private static void displayCardDetails(){
// Method implementation goes here.
}
}
4)Java 平台级模块系统
这里只给出解决的问题,仅限了解....
Java 9 的定义功能是一套全新的模块系统。当代码库越来越大,创建复杂,盘根错节的“意大利面条式代码”的几率呈指数级的增长。这时候就得面对两个基础的问题: 很难真正地对代码进行封装, 而系统并没有对不同部分(也就是 JAR 文件)之间的依赖关系有个明确的概念。每一个公共类都可以被类路径之下任何其它的公共类所访问到, 这样就会导致无意中使用了并不想被公开访问的 API。此外,类路径本身也存在问题: 你怎么知晓所有需要的 JAR 都已经有了, 或者是不是会有重复的项呢? 模块系统把这俩个问题都给解决了。
5)进程 API
Java SE 9 迎来一些 Process API 的改进,通过添加一些新的类和方法来优化系统级进程的管控。
Process API 中的两个新接口:
- java.lang.ProcessHandle
- java.lang.ProcessHandle.Info
Process API 示例
ProcessHandle currentProcess = ProcessHandle.current();
System.out.println("Current Process Id: = " + currentProcess.getPid());
6)Try With Resources Improvement
我们知道,Java SE 7 引入了一个新的异常处理结构:Try-With-Resources,来自动管理资源。这个新的声明结构主要目的是实现“Automatic Better Resource Management”(“自动资源管理”)。
Java SE 9 将对这个声明作出一些改进来避免一些冗长写法,同时提高可读性。
Java SE 7 示例
void testARM_Before_Java9() throws IOException {
BufferedReader reader1 = new BufferedReader(new FileReader("journaldev.txt"));
try (BufferedReader reader2 = reader1) {
System.out.println(reader2.readLine());
}
}
Java SE 9 示例
void testARM_Java9() throws IOException {
BufferedReader reader1 = new BufferedReader(new FileReader("journaldev.txt"));
try (reader1) {
System.out.println(reader1.readLine());
}
}
7)CompletableFuture API Improvements
在 Java SE 9 中,Oracle 公司将改进 CompletableFuture API 来解决一些 Java SE 8 中出现的问题。这些被添加的 API 将用来支持一些延时和超时操作,实用方法和更好的子类化。
Executor exe = CompletableFuture.delayedExecutor(50L, TimeUnit.SECONDS);
这里的 delayedExecutor() 是静态实用方法,用来返回一个在指定延时时间提交任务到默认执行器的新 Executor 对象。
8)反应式流 ( Reactive Streams )
反应式编程的思想最近得到了广泛的流行。 在 Java 平台上有流行的反应式 库 RxJava 和 R eactor。反应式流规范的出发点是提供一个带非阻塞负压( non-blocking backpressure ) 的异步流处理规范。反应式流规范的核心接口已经添加到了 Java9 中的 java.util.concurrent.Flow 类中。
Flow 中包含了 Flow.Publisher、Flow.Subscriber、Flow.Subscription 和 F low.Processor 等 4 个核心接口。Java 9 还提供了 SubmissionPublisher 作为 Flow.Publisher 的一个实现。RxJava 2 和 Reactor 都可以很方便的 与 Flow 类的核心接口进行互操作。
9)改进的 Stream API
长期以来,Stream API 都是 Java 标准库最好的改进之一。通过这套 API 可以在集合上建立用于转换的申明管道。在 Java 9 中它会变得更好。Stream 接口中添加了 4 个新的方法:dropWhile, takeWhile, ofNullable。还有个 iterate 方法的新重载方法,可以让你提供一个 Predicate (判断条件)来指定什么时候结束迭代:
IntStream.iterate(1, i -> i < 100, i -> i + 1).forEach(System.out::println);
第二个参数是一个 Lambda,它会在当前 IntStream 中的元素到达 100 的时候返回 true。因此这个简单的示例是向控制台打印 1 到 99。
除了对 Stream 本身的扩展,Optional 和 Stream 之间的结合也得到了改进。现在可以通过 Optional 的新方法 stram 将一个 Optional 对象转换为一个(可能是空的) Stream 对象:
Stream s = Optional.of(1).stream();
在组合复杂的 Stream 管道时,将 Optional 转换为 Stream 非常有用。
10)HTTP/2
Java 9 中有新的方式来处理 HTTP 调用。这个迟到的特性用于代替老旧的 HttpURLConnection API,并提供对 WebSocket 和 HTTP/2 的支持。注意:新的 HttpClient API 在 Java 9 中以所谓的孵化器模块交付。也就是说,这套 API 不能保证 100% 完成。不过你可以在 Java 9 中开始使用这套 API:
HttpClient client = HttpClient.newHttpClient();
HttpRequest req =
HttpRequest.newBuilder(URI.create("http://www.google.com"))
.header("User-Agent","Java")
.GET()
.build();
HttpResponse resp = client.send(req, HttpResponse.BodyHandler.asString());
HttpResponse
除了这个简单的请求/响应模型之外,HttpClient 还提供了新的 API 来处理 HTTP/2 的特性,比如流和服务端推送。
11)Optional Class Improvements
在 Java SE 9 中,Oracle 公司添加了一些新的实用方法到 java.util.Optional 类里面。这里我将使用一些简单的示例来描述其中的一个:stream 方法。
如果一个值出现在给定 Optional 对象中,stream() 方法可以返回包含该值的一个顺序 Stream 对象。否则,将返回一个空 Stream。
stream() 方法已经被添加,并用来在 Optional 对象中使用,如:
Stream emp = getEmployee(id)
Stream empStream = emp.flatMap(Optional::stream)
这里的 Optional.stream() 方法被用来转化 Employee 可选流对象 到 Employee 流中,如此我们便可以在后续代码中使用这个结果。
12)多版本兼容 JAR
我们最后要来着重介绍的这个特性对于库的维护者而言是个特别好的消息。当一个新版本的 Java 出现的时候,你的库用户要花费数年时间才会切换到这个新的版本。这就意味着库得去向后兼容你想要支持的最老的 Java 版本 (许多情况下就是 Java 6 或者 7)。这实际上意味着未来的很长一段时间,你都不能在库中运用 Java 9 所提供的新特性。幸运的是,多版本兼容 JAR 功能能让你创建仅在特定版本的 Java 环境中运行库程序时选择使用的 class 版本:
multirelease.jar
├── META-INF
│ └── versions
│ └── 9
│ └── multirelease
│ └── Helper.class
├── multirelease
├── Helper.class
└── Main.class
在上述场景中, multirelease.jar 可以在 Java 9 中使用, 不过 Helper 这个类使用的不是顶层的 multirelease.Helper 这个 class, 而是处在“META-INF/versions/9”下面的这个。这是特别为 Java 9 准备的 class 版本,可以运用 Java 9 所提供的特性和库。同时,在早期的 Java 诸版本中使用这个 JAR 也是能运行的,因为较老版本的 Java 只会看到顶层的这个 Helper 类。
欢迎转载,转载请注明出处!
ID:@我没有三颗心脏
github:wmyskxz
欢迎关注公众微信号:wmyskxz_javaweb
分享自己的Java Web学习之路以及各种Java学习资料